

 新火種
2024-12-13
新火種
2024-12-13 


看GAN如何一步步控制圖像生成風(fēng)格?詳解StyleGAN進(jìn)化過程
選自Medium
作者:Jonathan Hui
機器之心編譯
參與:魔王、杜偉
GAN 能夠有條不紊地控制其生成圖像的風(fēng)格嗎?
你了解自己的風(fēng)格嗎?大部分 GAN 模型并不了解。那么,GAN 能夠有條不紊地控制其生成圖像的風(fēng)格嗎?
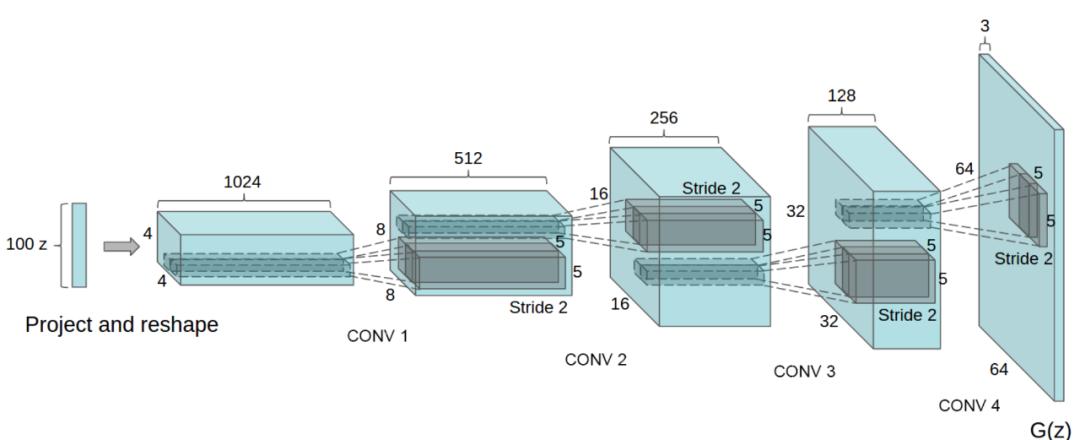
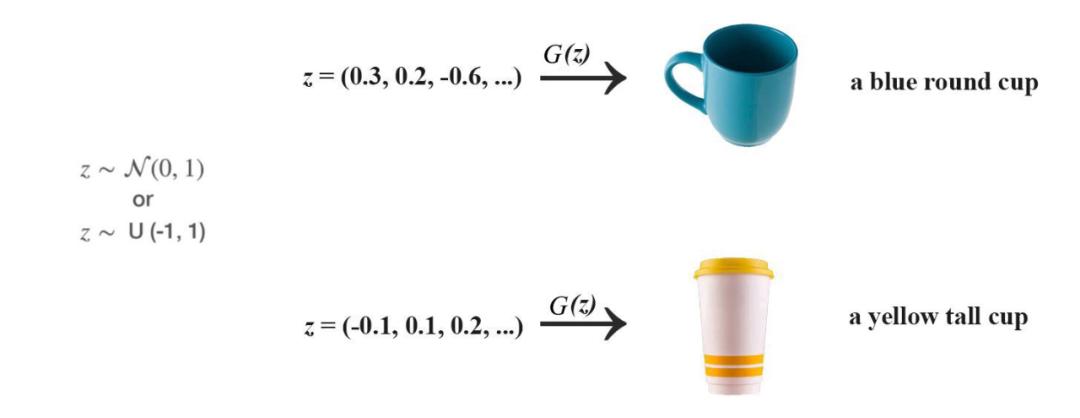
為什么 z 是均勻或正態(tài)分布?
既然 z 包含元信息,那么它是否應(yīng)在每個卷積層生成數(shù)據(jù)的過程中發(fā)揮更主要的作用?(而不是僅作為第一層的輸入)
注意:本文將使用「風(fēng)格」(style)來指代元信息,其包含類型信息和風(fēng)格信息。
下圖是 StyleGAN2 生成的圖像:

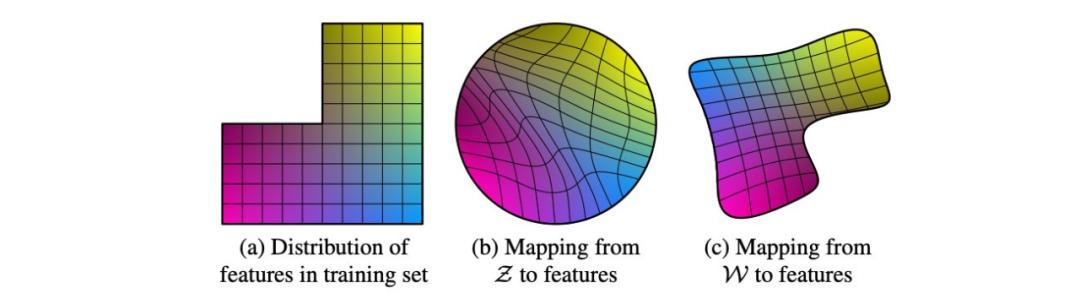
機器學(xué)習(xí)中的潛在因子通常彼此獨立,以簡化模型訓(xùn)練過程。例如,身高和體重具備高度相關(guān)性(個子越高的人通常體重更大)。因此,基于身高、體重計算得到的身體質(zhì)量指數(shù)(body mass index,BMI)較常用于衡量人體肥胖程度,其所需的訓(xùn)練模型復(fù)雜度較低。而彼此獨立的因子使得模型更易于解釋。
在 GAN 中,z 的分布應(yīng)與真實圖像的潛在因子分布類似。如果我們從正態(tài)或均勻分布中采樣 z,則優(yōu)化后的模型可能需要 z 來嵌入類型和風(fēng)格以外的信息。例如,我們?yōu)檐娙松蓤D像,并基于男性化程度和頭發(fā)長度這兩個潛在因子來可視化訓(xùn)練數(shù)據(jù)集的數(shù)據(jù)分布。下圖中缺失的左上角表示男性軍人不允許留長發(fā)。

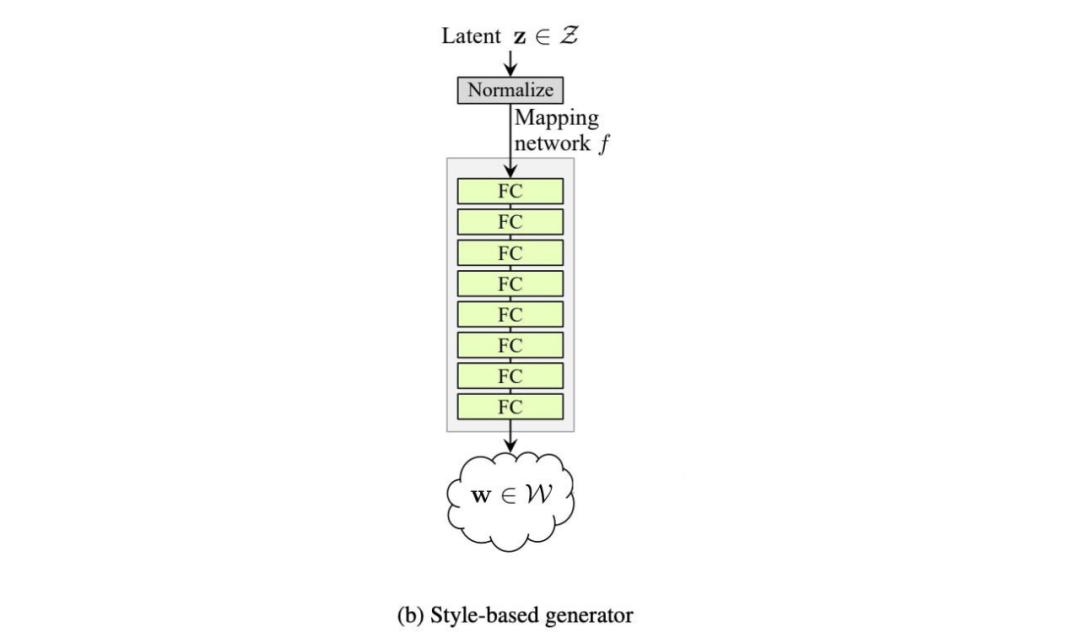
在 logistic 回歸中,我們利用基變換(change of basis)來創(chuàng)建二分類類別的線性邊界。而 StyleGAN 使用一種叫做映射網(wǎng)絡(luò)(mapping network)的深度網(wǎng)絡(luò),將潛在因子 z 轉(zhuǎn)換成中間潛在空間 w。
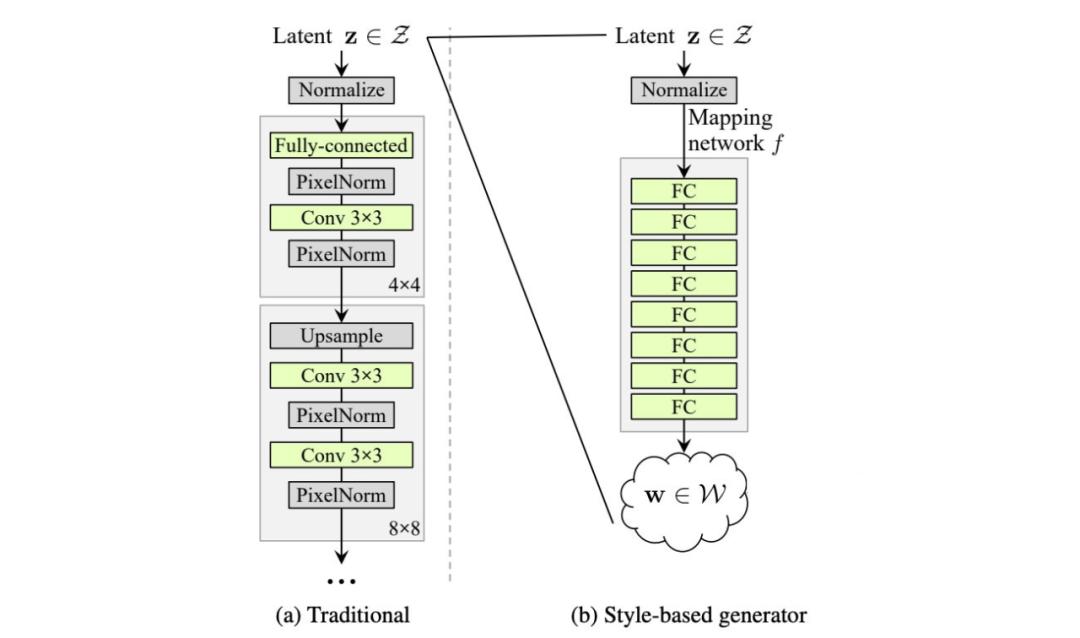
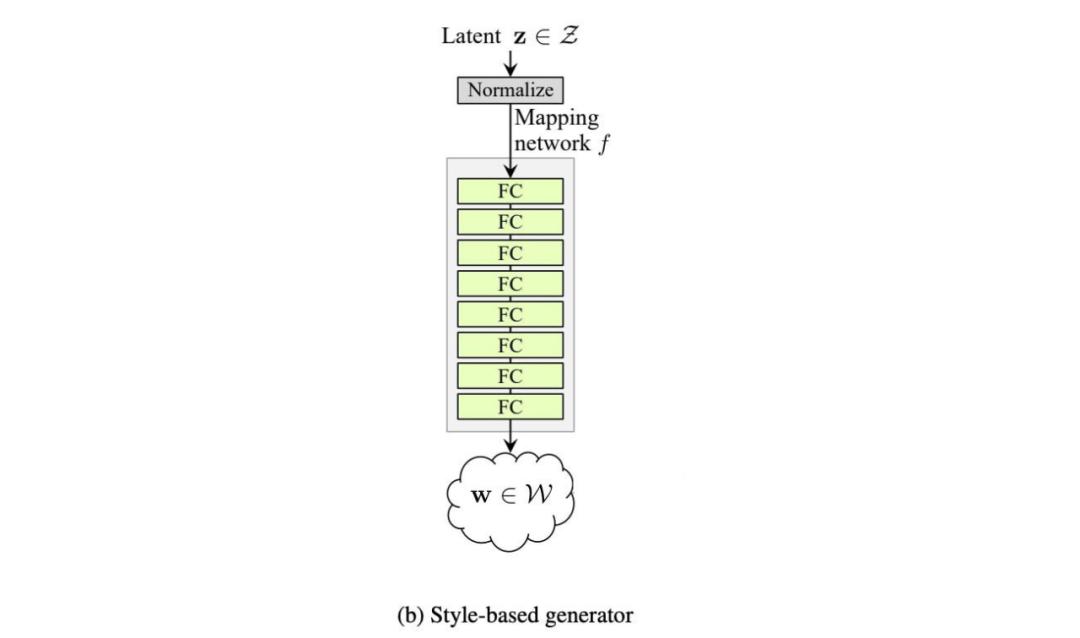
在原版 GAN 中,潛在因子 z 僅作為深度網(wǎng)絡(luò)第一個層的輸入。我們可能認(rèn)為,隨著網(wǎng)絡(luò)的深入,z 的作用會逐漸消失。
而基于風(fēng)格的生成器使用單獨學(xué)得的仿射運算 A 在每一層中轉(zhuǎn)換 w。轉(zhuǎn)換后的 w 將作為風(fēng)格信息作用于空間數(shù)據(jù)。
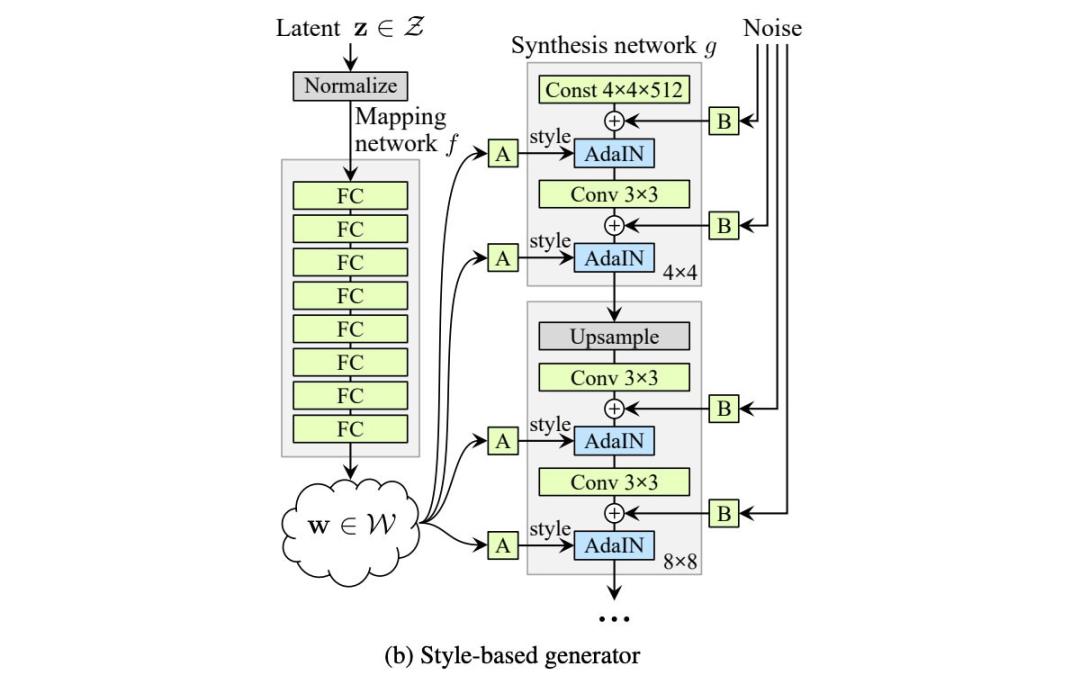
第二個改進(jìn)版本 (C) 添加了映射網(wǎng)絡(luò)和風(fēng)格化(styling)。對于后者,AdaIN(自適應(yīng)實例歸一化)取代 PixelNorm 對空間數(shù)據(jù)執(zhí)行風(fēng)格化處理。
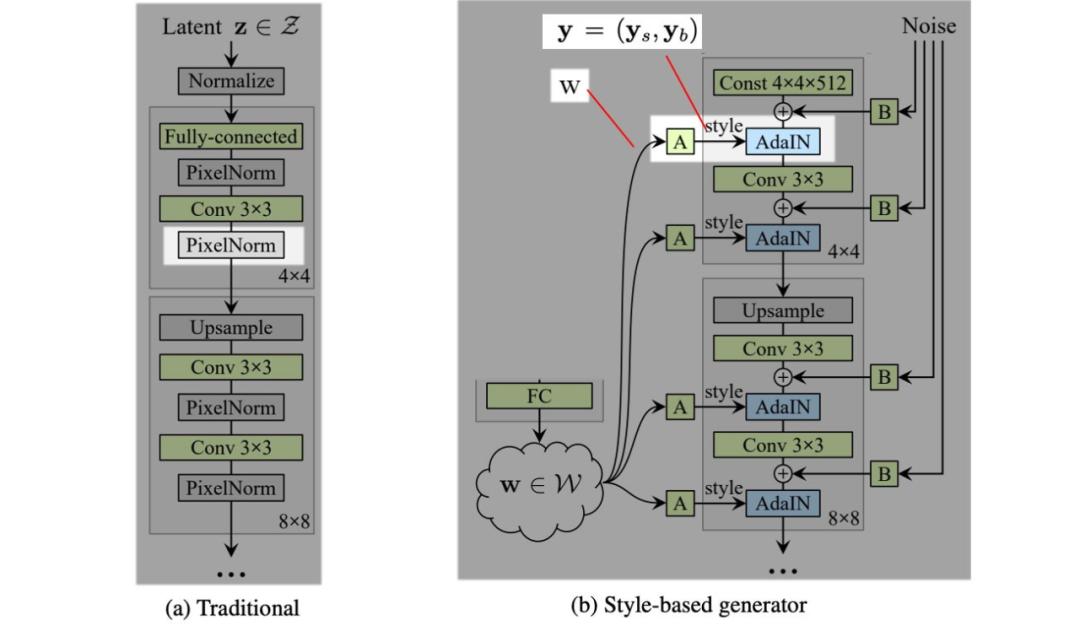
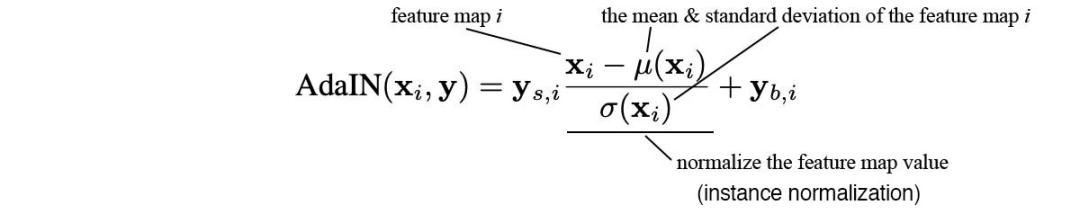
在原版 GAN 中,第一層的輸入是潛在因子 z。實驗結(jié)果表明,向 StyleGAN 第一層添加可變輸入毫無益處,因此將可變輸入替換為常量輸入。
至于改進(jìn)版本 (D),其第一層的輸入被替換為學(xué)得的常數(shù)矩陣,矩陣維度為 4×4×512。
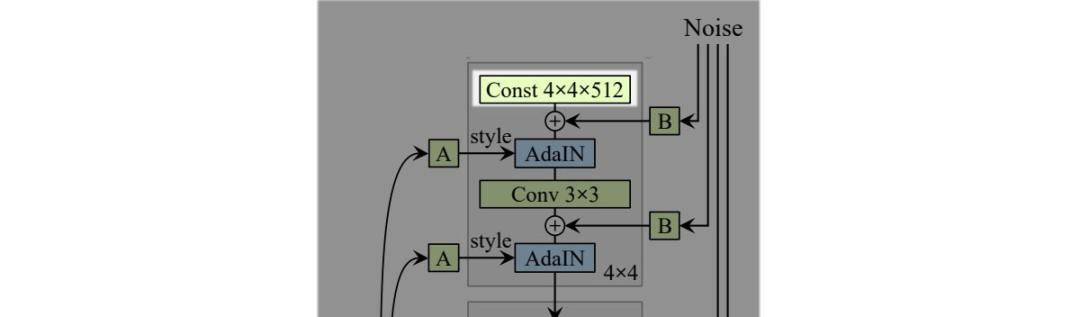



關(guān)于噪聲如何導(dǎo)致不同的圖像渲染結(jié)果,參見以下視頻:
最后一個改進(jìn)版本 (E) 涉及混合正則化。
風(fēng)格混合與混合正則化
之前我們生成潛在因子 z,并作為生成風(fēng)格的單一源頭。而使用混合正則化后,我們轉(zhuǎn)而使用另一個潛在因子 z?,在達(dá)到特定空間分辨率之后再生成風(fēng)格。



訓(xùn)練
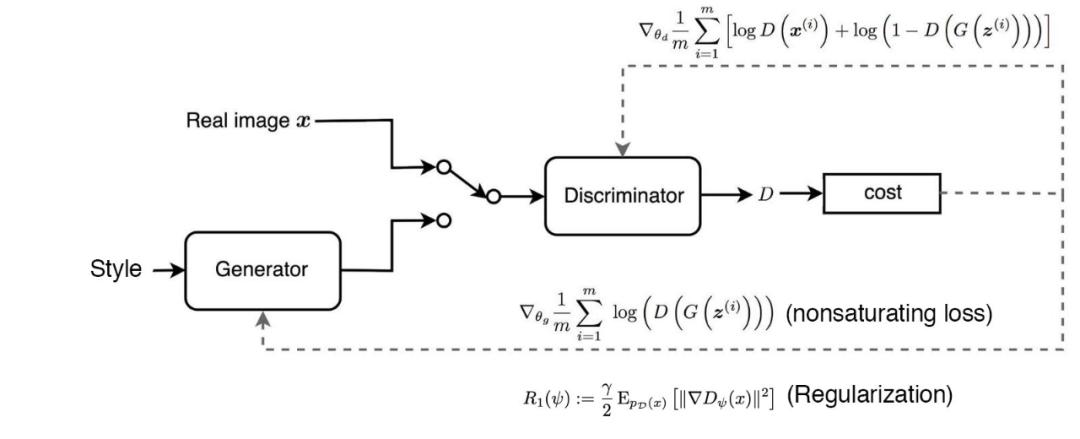
與 CelebA-HQ 數(shù)據(jù)集相比,F(xiàn)FHQ(Flickr-Faces-HQ,高清人臉數(shù)據(jù)集)質(zhì)量更高,覆蓋范圍更大,如年齡、種族、圖像背景以及眼鏡、帽子等配飾。在 StyleGAN 中,CelebA-HQ 數(shù)據(jù)集訓(xùn)練過程中使用 WGAN-GP 作為損失函數(shù),而 FFHQ 數(shù)據(jù)集則使用非飽和 GAN 損失函數(shù)和 R?正則化項,如下所示:
z 或 w 中的低概率密度區(qū)域可能不具備足以準(zhǔn)確學(xué)習(xí)模型的訓(xùn)練數(shù)據(jù)。
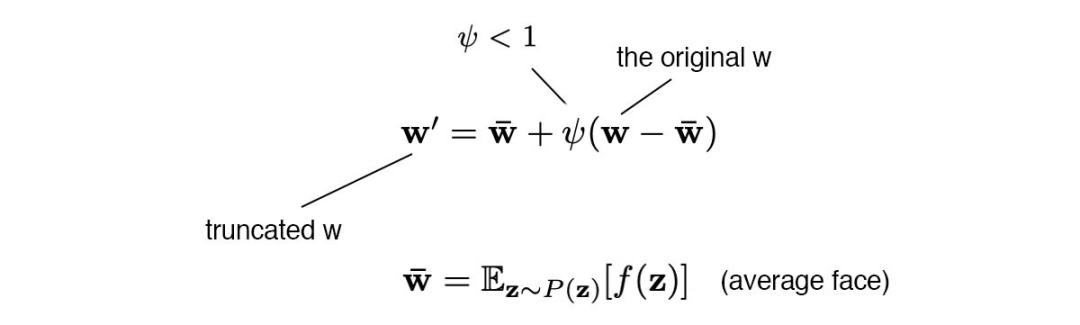
但截斷僅在低分辨率層上執(zhí)行(比如 4×4 至 32×32 空間層,ψ = 0.7)。這可以確保不影響高分辨率細(xì)節(jié)。
當(dāng) ψ 為 0 時,它生成的平均人臉如下圖所示。隨著 ψ 值的調(diào)整,我們可以看到人物視線、眼鏡、年齡、膚色、頭發(fā)長度和性別等屬性的變化,如從戴眼鏡到不戴眼鏡。

StyleGAN 論文還提出一種度量 GAN 性能的新型指標(biāo)——感知路徑長度(perceptual path length)。GAN 逐步改變潛在因子 z 中的某個特定維度,進(jìn)而可視化其語義。

首先,我們使用 VGG16 嵌入來度量兩個圖像之間的感知差異。如果我們將潛在空間插值路徑分割為線性片段,則可以對每個片段添加所有感知差異。差異值越低,則 GAN 圖像的質(zhì)量越高。詳細(xì)數(shù)學(xué)定義參見 StyleGAN 論文。
StyleGAN 中存在的問題
StyleGAN 生成圖像中存在類似水滴的斑狀偽影,在生成器網(wǎng)絡(luò)的中間特征圖中此類偽影更加明顯。這一問題似乎出現(xiàn)在所有 64×64 分辨率特征圖中,且在分辨率更高的特征圖中更為嚴(yán)重。

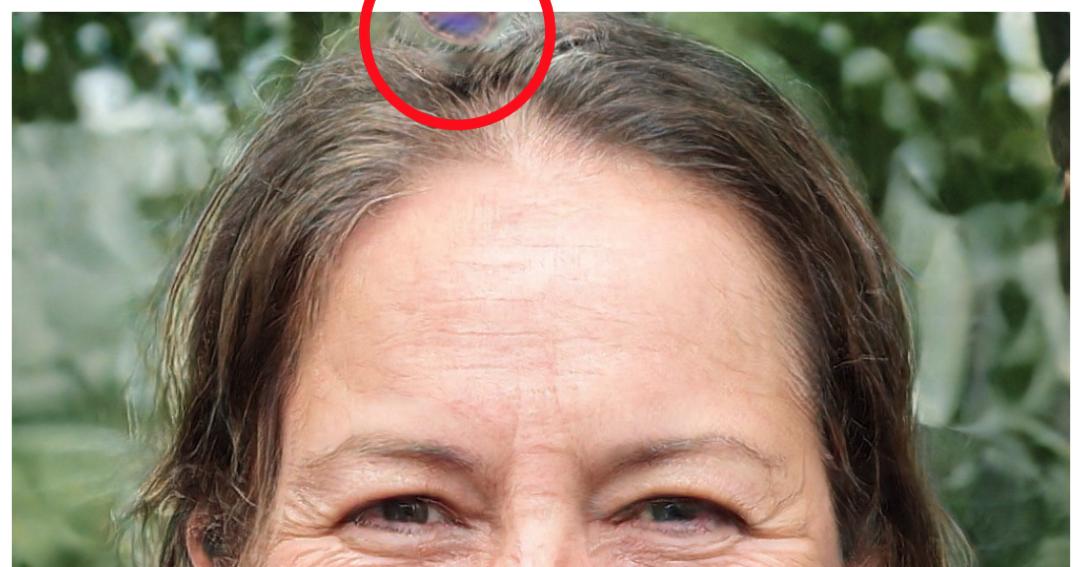
我們認(rèn)為問題出在 AdaIN 運算,它可以分別對每個特征圖的均值和方差執(zhí)行歸一化,由此可能摧毀在特征的幅度中找到的任何彼此相關(guān)的信息。我們假設(shè)這種水滴狀偽影出現(xiàn)的原因是生成器有意將信號強度信息傳遞通過實例歸一化:通過創(chuàng)建主導(dǎo)統(tǒng)計數(shù)據(jù)的強局部尖峰,生成器可以像在其它地方一樣有效縮放該信號。
此外,StyleGAN2 提出一種替代設(shè)計方案來解決漸進(jìn)式增長導(dǎo)致的問題,以穩(wěn)定高分辨率訓(xùn)練。
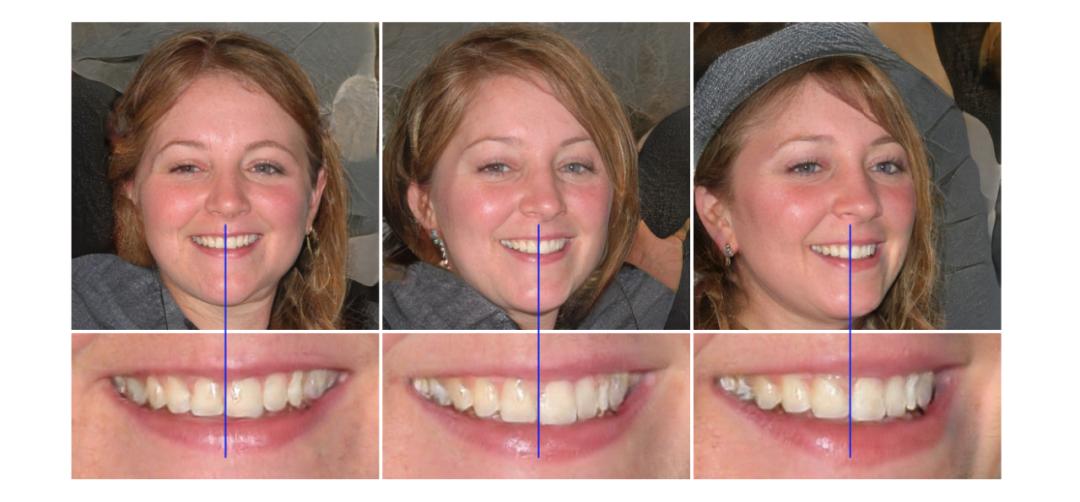
在探討 StyleGAN2 之前,我們先重新繪制 StyleGAN 設(shè)計圖(下圖右)。該設(shè)計的 AdaIN 模塊同樣分為兩個模塊,但此圖添加了偏置,而原始設(shè)計圖中省略了這一項。(注意,目前模型設(shè)計沒有任何改變)
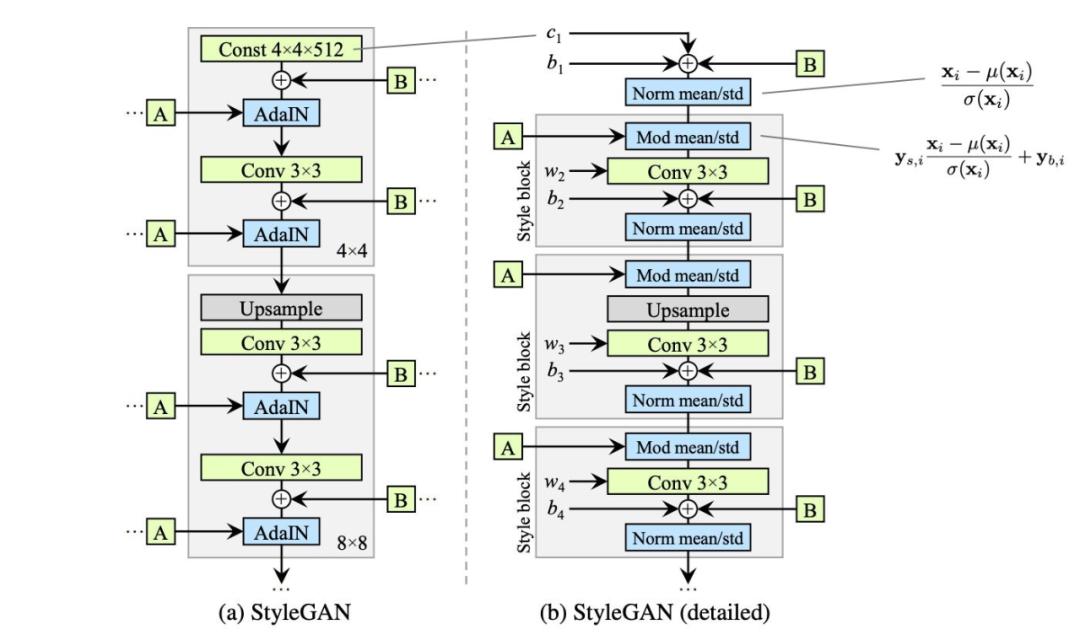
權(quán)重解調(diào)(weight demodulation)
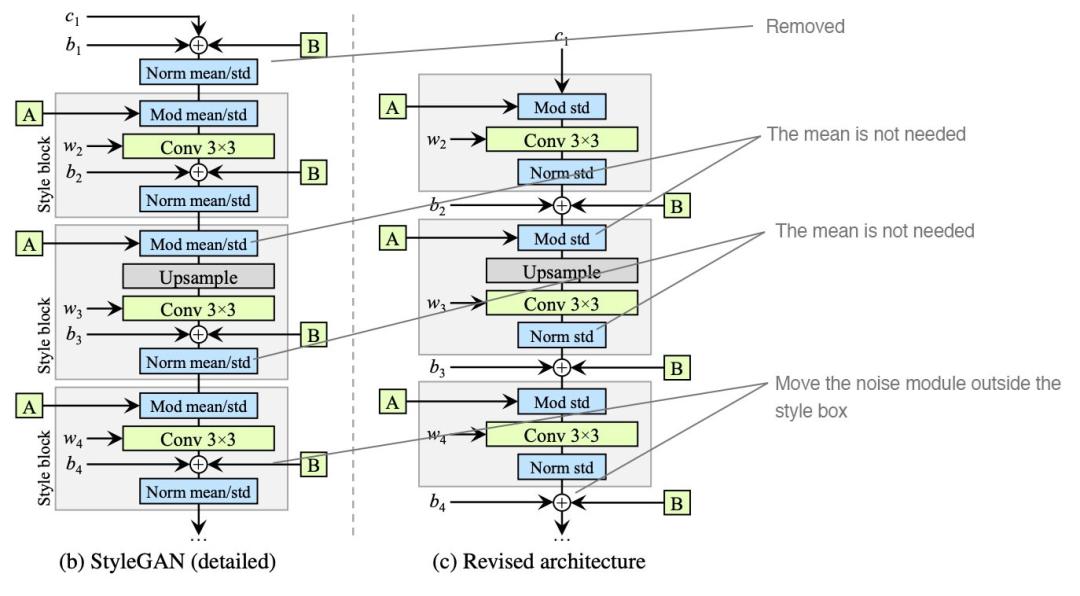
在實驗結(jié)果的支持下,StyleGAN2 做出了以下改變:
移除(簡化)初期處理常數(shù)的方式;
歸一化特征時無需求均值;
將噪聲模塊從風(fēng)格模塊中移出。
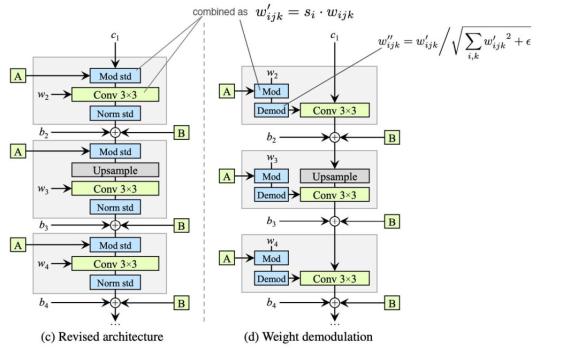
1. 調(diào)制 (mod std) 后是卷積 (Conv 3×3),二者組合起來可用于縮放卷積權(quán)重,并實現(xiàn)為上圖右中的 Mod。(這并未改變模型設(shè)計)
其中 i 是輸入特征圖。
2. 然后用 Demod 對權(quán)重執(zhí)行歸一化:
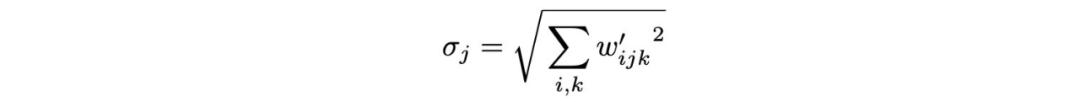
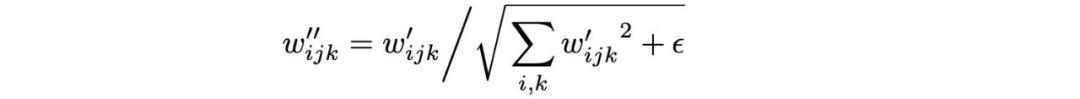
StyleGAN2 做出的改進(jìn)
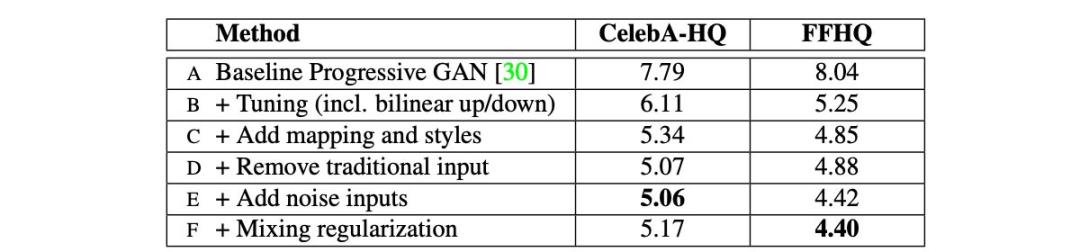
現(xiàn)在,我們來看 StyleGAN2 的改進(jìn)版本。下圖總結(jié)了多種模型改動,以及對應(yīng)的 FID 分?jǐn)?shù)改進(jìn)情況(FID 分?jǐn)?shù)越小,模型性能越好)。

StyleGAN 對 FFHQ 數(shù)據(jù)集應(yīng)用 R?正則化。懶惰式正則化表明,在成本計算過程中忽略大部分正則化成本也不會帶來什么壞處。事實上,即使每 16 個 mini-batch 僅執(zhí)行一次正則化,模型性能也不會受到影響,同時計算成本有所降低。
路徑長度正則化
如前所述,路徑長度可用于度量 GAN 性能。一個可能的麻煩是,插值路徑上不同片段之間的路徑距離變動很大。簡而言之,我們希望連續(xù)的線性插值點之間的圖像距離類似。也就是說,潛在空間中的位移會導(dǎo)致圖像空間中出現(xiàn)同樣幅度的變化,而這與潛在因子的值無關(guān)。因此,我們添加一個正則化項,如下所示:
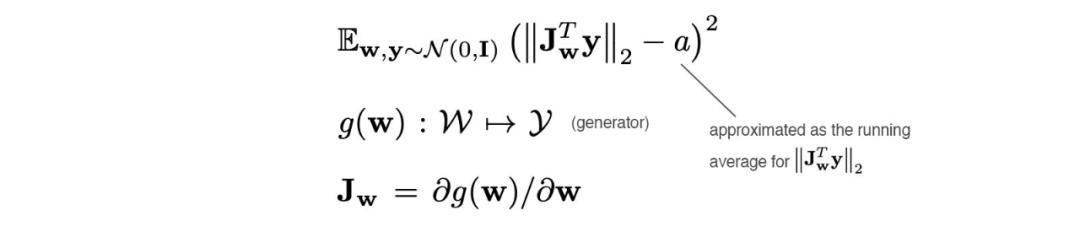
此處不再詳述,代碼參見:https://github.com/NVlabs/stylegan2/blob/7d3145d23013607b987db30736f89fb1d3e10fad/training/loss.py,讀者可以據(jù)此運行 debugger。
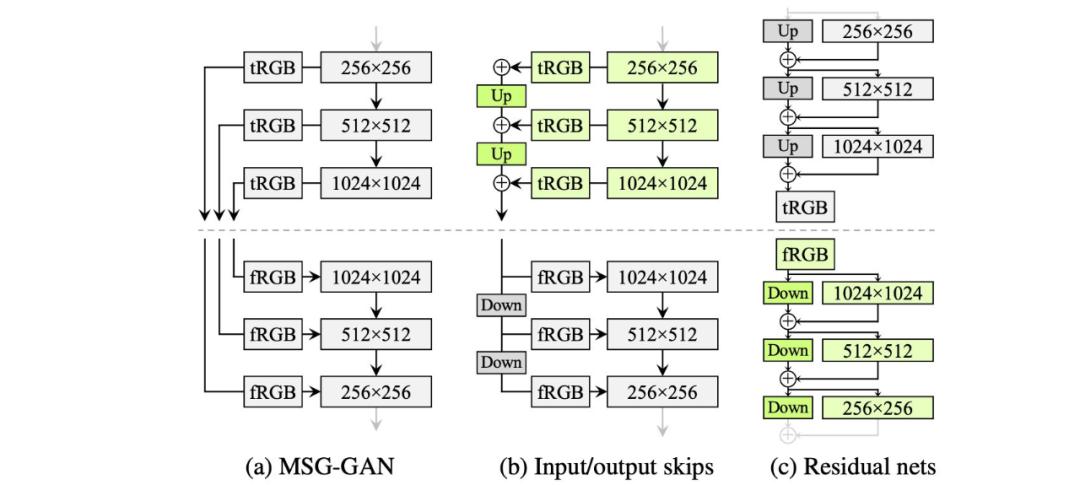
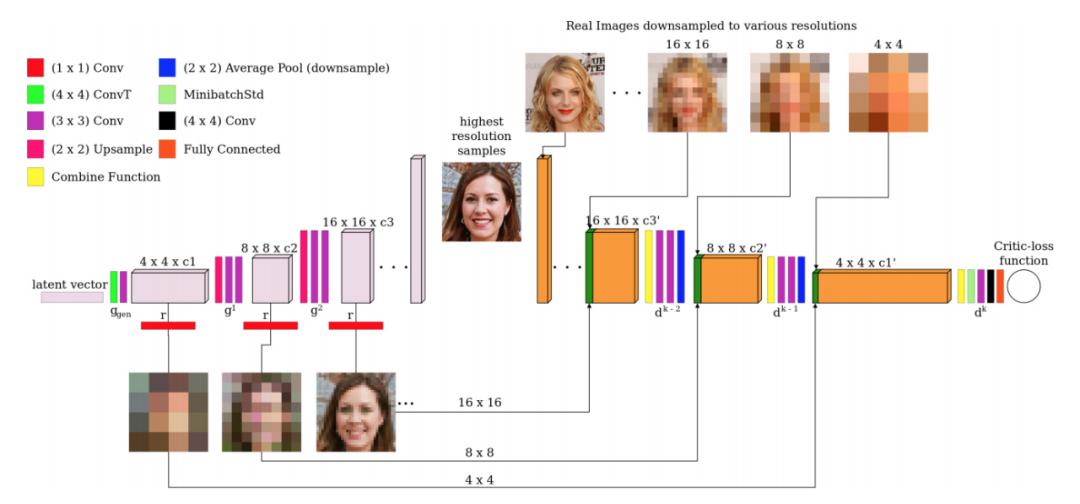
漸進(jìn)式增長
StyleGAN 使用漸進(jìn)式增長來穩(wěn)定高分辨率圖像的訓(xùn)練。上文我們提到了漸進(jìn)式增長的問題,StyleGAN2 尋求一種替代設(shè)計,允許深度較大的網(wǎng)絡(luò)也能具備良好的訓(xùn)練穩(wěn)定性。ResNet 使用殘差連接(skip connection)來實現(xiàn)這一目標(biāo)。因此 StyleGAN2 探索了殘差連接設(shè)計和其它與 ResNet 類似的殘差概念。對于這些設(shè)計,我們使用雙線性濾波器對前一層執(zhí)行上采樣/下采樣,并嘗試學(xué)習(xí)下一層的殘差值。

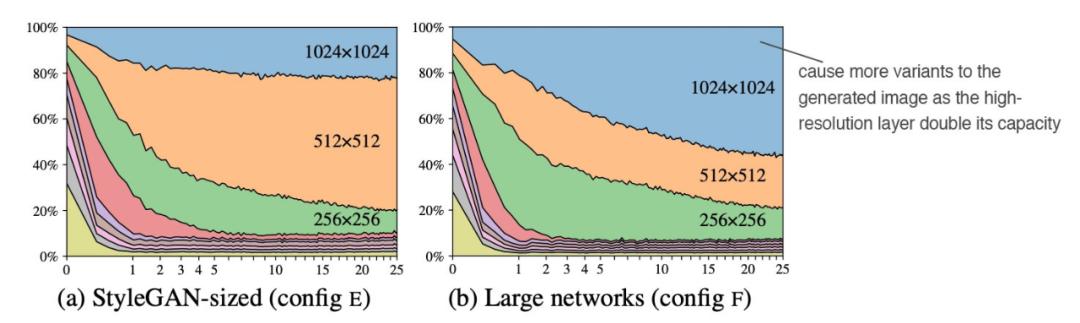
在這些改動之后,我們進(jìn)一步分析了高分辨率層對圖像生成的影響。StyleGAN2 論文度量了不同模型層輸出圖像的變化。下圖左表示每個層對生成圖像的貢獻(xiàn),橫軸表示訓(xùn)練過程。
在訓(xùn)練初期,低分辨率層占主導(dǎo)地位。然而,隨著更多訓(xùn)練迭代的完成,高分辨率層(尤其是 1024 × 1024 層)的貢獻(xiàn)不如預(yù)計的多。研究者懷疑這些層的容量不夠大。事實的確如此,當(dāng)高分辨率層中的特征圖數(shù)量翻倍時,其影響力顯著上升(右圖)。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
