

 新火種
2024-12-13
新火種
2024-12-13 


NeurIPSSpotlight|從分類到生成:無訓練的可控擴散生成
論文一作為斯坦福大學計算機博士葉皓天,指導老師為斯坦福大學 Stefano Ermon 與 James Zou 教授。北京大學博士林昊葦、斯坦福大學博士韓家琦為共同第一作者。
近年來,擴散模型(Diffusion Models)已成為生成模型領域的研究前沿,它們在圖像生成、視頻生成、分子設計、音頻生成等眾多領域展現出強大的能力。然而,生成符合特定條件(如標簽、屬性或能量分布)的樣本,通常需要為每個目標訓練專門的生成模型,這種方法不僅耗費資源,還嚴重制約了擴散模型作為未來基座模型實際應用潛力。
為了解決這一難題,斯坦福大學、北京大學、清華大學等機構的研究團隊聯合提出了一種全新的統一算法框架,名為無訓練指導(Training-Free Guidance, 簡稱 TFG)。這一框架無縫整合現有的無訓練指導方法,憑借理論創新和大規模實驗驗證,成為擴散模型條件生成領域的重要里程碑,目前已經被 NeurIPS 2024 接收為 Spotlight。

問題背景:擴散模型的條件生成難題
擴散模型以其漸進降噪生成樣本的特性,逐漸被廣泛應用于從圖像到視頻到音頻、從分子到 3D 結構等多領域。然而,條件生成的需求(如生成特定類別的圖像或滿足特定能量約束的分子結構)對模型提出了更高要求。
傳統條件生成方法依賴 “基于分類器的指導”(classifier-guidance)或 “無分類器指導”(classifier-free)技術。這些方法通常需要為這一類事先確定的目標屬性訓練一個生成 + 預測模型或是帶標簽的生成模型。一旦訓練完成,該模型就難以被運用到同一領域的其他條件生成任務中,因而難以推廣至多目標或新目標場景。與之相比,無訓練指導旨在利用現成的目標預測器(如預訓練分類器、能量函數、損失函數等)直接為擴散模型生成提供指導,避免了額外的訓練步驟。然而,現有無訓練方法存在以下顯著問題:
TFG 框架的核心創新
1. 統一設計空間(unified design space)
TFG 提出了一個通用的無訓練指導設計空間,將現有算法視為其特殊情況。這種統一視角不僅簡化了對不同算法的比較,還通過擴展設計空間提升了性能。具體而言,TFG 基于多維超參數設計,涵蓋了多種指導方法的變體,為任務適配提供了靈活性。
2. 高效超參數搜索策略(efficient searching strategy)
為了應對多目標、多樣化任務場景,TFG 引入了一種高效的超參數搜索策略。在此框架下,用戶無需復雜的調參過程,通過自動化策略即可快速確定最優超參數組合,適配多種下游任務。
3. 全面基準測試(comprehensive benchmark)
TFG 框架在 7 種擴散模型上開展了廣泛的實驗,包括圖像、分子、音頻等 16 項任務和 40 個具體目標。實驗結果顯示,TFG 平均性能提升 8.5%,在多個任務中均超越現有最佳方法。
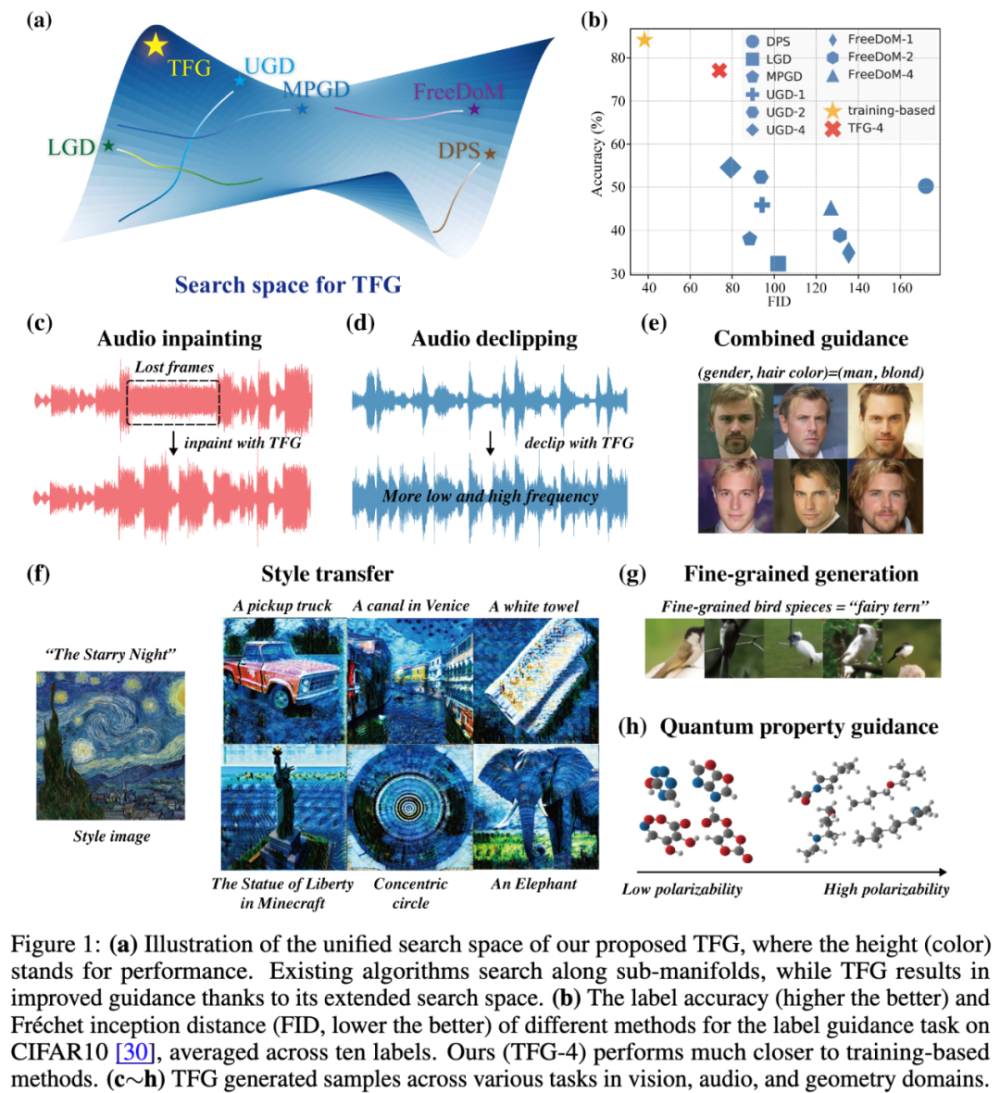
方法概述:TFG 如何實現無訓練指導?

實現 TFG 的核心是利用 Tweedie’s formula,通過預訓練的擴散模型預測當前噪聲樣本對應的干凈樣本分布均值,再用判別器進行打分,將可微的分數進行反向傳播,從而指導噪聲樣本的去噪過程。基于以上思路,TFG 提出了一個統一的算法框架,精細設計了四大關鍵機制來提升條件生成任務的表現:Mean Guidance、Variance Guidance、Implicit Dynamics 和 Recurrence。以下是各部分的詳細介紹:
1. Mean Guidance(均值指導)
Mean Guidance 利用預測樣本的均值梯度來引導生成過程,核心思想是對生成樣本的目標屬性進行直接優化。在每一步去噪過程中,模型會根據當前的預測樣本 計算目標預測器(如分類器)的梯度。這些梯度被用于調整樣本,使其逐漸向高目標密度區域移動。Mean guidance 的優點是簡單直接,易于實現。但在目標空間的低概率區域中,梯度可能不穩定,導致生成的樣本質量下降。為此,TFG 通過 recurrence(遞歸)和動態調整梯度強度來改進這一不足。
2. Variance Guidance(方差指導)
Variance Guidance 利用預測樣本的方差信息,通過對梯度進行協方差調整,進一步優化生成方向。通過在噪聲樣本空間計算梯度,而非直接作用于預測樣本 ,引入了更多高階信息。根據梯度與樣本協方差矩陣的相互作用,對樣本生成方向進行動態調整。文章中證明了這種方法等價于對梯度進行了協方差加權,增強了生成過程中目標屬性之間的協同作用。例如,正相關的目標特性會被相互加強,而負相關的特性會被弱化。
3. Implicit Dynamics(隱式動態)
隱式動態通過為目標預測器引入高斯核平滑,形成了一種漸進式的 “動態噪聲引導”。在每一步生成中,對目標函數進行高斯平滑,逐步增加噪聲,并通過噪聲樣本計算梯度。這種操作使得樣本更容易跳出低概率區域,收斂至高目標密度區域。即使采用少量的采樣樣本,也能顯著提升生成樣本的多樣性和精度。
4. Recurrence(遞歸機制)
遞歸機制通過重復應用前述指導步驟來逐步強化生成結果。每一步去噪的中間結果被不斷 “回滾” 并重新生成,類似于一個動態優化的循環過程。每次遞歸的目的是修正前一輪生成的誤差,同時引入更多的指導信息。在標準的標簽指導任務(如 CIFAR10 和 ImageNet)中,遞歸次數的增加顯著提升了樣本準確率。例如,在 CIFAR10 數據集上,將遞歸次數從 1 增加到 4,準確率從 52% 提升到 77%,縮小了與基于訓練的指導方法的性能差距。
本文從理論上證明,已有的一些無訓練指導算法(例如 UGD,FreeDoM,MPGD,DPS,LGD)都是 TFG 的特例。TFG 構建了一個全面的超參數搜索空間,而已有的算法本質上都是在這個空間的某個子空間進行搜索。所以,TFG 將免訓練指導算法設計的問題轉化為:如何進行高效有效的超參數搜索?
設計空間的構建
TFG 框架的一個核心創新在于其設計空間(Design Space)的構建與超參數優化策略的提出。研究團隊對這一問題進行了系統分析,并提出了一種高效的通用搜索方法,具體由以下幾個超參數組成:
1. 時間相關向量:包括 ρ(Variance Guidance 強度) 和 μ(Mean Guidance 強度),分別控制梯度的影響力度及其在每個時間步的分布。
2. 時間無關標量:
這些參數的組合定義了 TFG 的設計空間 。研究表明,現有的無訓練指導方法(如 DPS、FreeDoM、UGD 等)可以被視為該設計空間的特殊情況,這意味著 TFG 實現了對這些方法的統一與擴展。為了更好地分析和使用設計空間,研究團隊提出了分解方法,將時間相關的向量(如 ρ 和 μ)分解為:
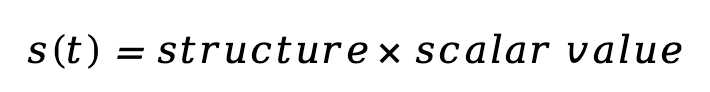
在設計空間中定義了三種結構:
1. Increase(遞增結構):如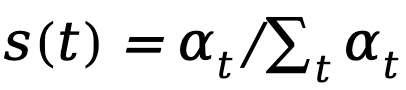 ,權重隨時間步逐漸增加。2. Decrease(遞減結構):如
,權重隨時間步逐漸增加。2. Decrease(遞減結構):如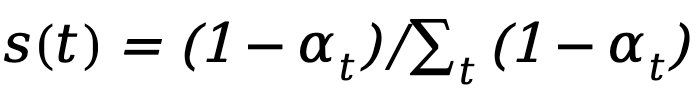 ,權重隨時間步逐漸減小。3. Constant(恒定結構):權重在每個時間步均相同。
,權重隨時間步逐漸減小。3. Constant(恒定結構):權重在每個時間步均相同。
通過實驗對比,研究團隊發現:ρ 和 μ 的遞增結構在多個任務中表現最佳,生成樣本的準確率和質量顯著提高;這一結果極大地簡化了設計空間的優化過程,為不同任務選擇合適的超參數提供了明確的指導。
高效超參數搜索策略
為了在廣泛的任務中實現高效優化,研究團隊設計了一種通用的超參數搜索策略,包括以下核心步驟:
1. 初始值設定:從較小的初始超參數值開始(如 ρ =μ=0.25),模擬無條件生成的效果。
2. 分步搜索:
3. 選擇最佳配置:將表現最優的配置加入候選集,并重復搜索,直至搜索結果穩定或達到預設的迭代次數。
該搜索方法將生成樣本數量顯著減少,保證在合理的計算成本內完成優化。在計算資源有限的情況下,研究團隊建議將遞歸次數和迭代次數分別限制在 4 次以內,既能保證性能,又能控制計算復雜度。
實驗亮點:TFG 的廣泛適用性和卓越表現
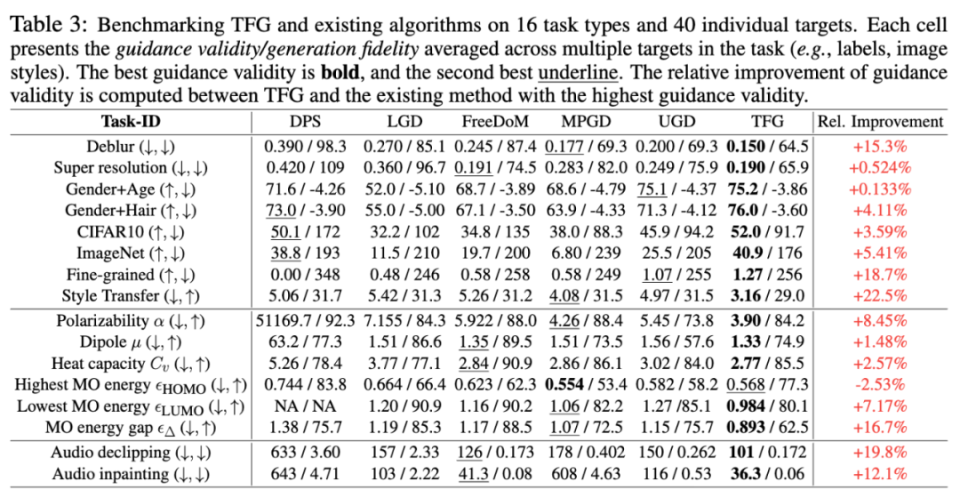
1. 精細類別生成任務
精細類別指導(Fine-Grained Label Guidance)是一種比傳統標簽指導更具挑戰性的任務,旨在為擴散模型生成出滿足更細致條件的樣本。在這項研究中,TFG 首次將無訓練指導方法成功應用于超越訓練分布的細粒度標簽生成任務。
研究團隊選擇了鳥類圖像的細粒度標簽指導任務(例如基于鳥類的物種特征生成圖像)。這類任務的挑戰在于:
TFG 通過其遞歸增強(Recurrence)機制顯著提升了生成性能。在實驗中,TFG 成功生成了具有 2.24% 準確率的目標樣本,相比無條件生成(0% 準確率)是一個巨大飛躍。盡管絕對精度仍有提升空間,但這標志著無訓練指導方法在細粒度標簽生成領域的重要突破。
2. 分子生成任務
TFG 首次應用于分子生成任務的無訓練指導,利用無訓練指導優化分子屬性(如極化率、電偶極矩等)。實驗結果顯示,TFG 在有效性上顯著領先于現有方法,進一步拓展了擴散模型的應用邊界。
3. 多目標條件生成
TFG 在多屬性指導任務(如生成特定性別和發色組合的人臉)中展示了顯著的均衡性和適配性。通過對生成樣本進行詳細分析,研究團隊發現 TFG 有效緩解了由于訓練數據分布不平衡導致的生成偏差問題。例如,在 “男性 + 金發” 這一稀有目標組合中,TFG 的生成準確率高達 46.7%,遠高于原始數據分布中的 1%。
4. 音頻生成任務
在少有探索的音頻生成領域,TFG 同樣表現出色。實驗涵蓋了音頻修復(去剪裁、補全)等任務,相比其他方法,TFG 的相對性能提升超過 15%。
TFG 的未來展望:重新定義擴散模型的可能性
近年來,擴散模型(Diffusion Models)已成為生成模型領域的研究前沿,它們在圖像生成、視頻生成、分子設計、音頻生成等眾多領域展現出強大的能力。然而,生成符合特定條件(如標簽、屬性或能量分布)的樣本,通常需要為每個目標訓練專門的生成模型,這種方法不僅耗費資源,還嚴重制約了擴散模型作為未來基座模型實際應用潛力。
為了解決這一難題,斯坦福大學、北京大學、清華大學等機構的研究團隊聯合提出了一種全新的統一算法框架,名為無訓練指導(Training-Free Guidance, 簡稱 TFG)。這一框架無縫整合現有的無訓練指導方法,憑借理論創新和大規模實驗驗證,成為擴散模型條件生成領域的重要里程碑,目前已經被 NeurIPS 2024 接收為 Spotlight。
- 論文標題:TFG: Unified Training-Free Guidance for Diffusion Models
- 論文鏈接:https://arxiv.org/abs/2409.15761
- 項目地址:https://github.com/YWolfeee/Training-Free-Guidance
問題背景:擴散模型的條件生成難題
擴散模型以其漸進降噪生成樣本的特性,逐漸被廣泛應用于從圖像到視頻到音頻、從分子到 3D 結構等多領域。然而,條件生成的需求(如生成特定類別的圖像或滿足特定能量約束的分子結構)對模型提出了更高要求。
傳統條件生成方法依賴 “基于分類器的指導”(classifier-guidance)或 “無分類器指導”(classifier-free)技術。這些方法通常需要為這一類事先確定的目標屬性訓練一個生成 + 預測模型或是帶標簽的生成模型。一旦訓練完成,該模型就難以被運用到同一領域的其他條件生成任務中,因而難以推廣至多目標或新目標場景。與之相比,無訓練指導旨在利用現成的目標預測器(如預訓練分類器、能量函數、損失函數等)直接為擴散模型生成提供指導,避免了額外的訓練步驟。然而,現有無訓練方法存在以下顯著問題:
- 缺乏系統性理論支持和設計指導;
- 即使在簡單任務中表現也不穩定,容易失敗;
- 難以高效選擇適合的超參數。
TFG 框架的核心創新
1. 統一設計空間(unified design space)
TFG 提出了一個通用的無訓練指導設計空間,將現有算法視為其特殊情況。這種統一視角不僅簡化了對不同算法的比較,還通過擴展設計空間提升了性能。具體而言,TFG 基于多維超參數設計,涵蓋了多種指導方法的變體,為任務適配提供了靈活性。
2. 高效超參數搜索策略(efficient searching strategy)
為了應對多目標、多樣化任務場景,TFG 引入了一種高效的超參數搜索策略。在此框架下,用戶無需復雜的調參過程,通過自動化策略即可快速確定最優超參數組合,適配多種下游任務。
3. 全面基準測試(comprehensive benchmark)
TFG 框架在 7 種擴散模型上開展了廣泛的實驗,包括圖像、分子、音頻等 16 項任務和 40 個具體目標。實驗結果顯示,TFG 平均性能提升 8.5%,在多個任務中均超越現有最佳方法。
方法概述:TFG 如何實現無訓練指導?
實現 TFG 的核心是利用 Tweedie’s formula,通過預訓練的擴散模型預測當前噪聲樣本對應的干凈樣本分布均值,再用判別器進行打分,將可微的分數進行反向傳播,從而指導噪聲樣本的去噪過程。基于以上思路,TFG 提出了一個統一的算法框架,精細設計了四大關鍵機制來提升條件生成任務的表現:Mean Guidance、Variance Guidance、Implicit Dynamics 和 Recurrence。以下是各部分的詳細介紹:
1. Mean Guidance(均值指導)
Mean Guidance 利用預測樣本的均值梯度來引導生成過程,核心思想是對生成樣本的目標屬性進行直接優化。在每一步去噪過程中,模型會根據當前的預測樣本 計算目標預測器(如分類器)的梯度。這些梯度被用于調整樣本,使其逐漸向高目標密度區域移動。Mean guidance 的優點是簡單直接,易于實現。但在目標空間的低概率區域中,梯度可能不穩定,導致生成的樣本質量下降。為此,TFG 通過 recurrence(遞歸)和動態調整梯度強度來改進這一不足。
2. Variance Guidance(方差指導)
Variance Guidance 利用預測樣本的方差信息,通過對梯度進行協方差調整,進一步優化生成方向。通過在噪聲樣本空間計算梯度,而非直接作用于預測樣本 ,引入了更多高階信息。根據梯度與樣本協方差矩陣的相互作用,對樣本生成方向進行動態調整。文章中證明了這種方法等價于對梯度進行了協方差加權,增強了生成過程中目標屬性之間的協同作用。例如,正相關的目標特性會被相互加強,而負相關的特性會被弱化。
3. Implicit Dynamics(隱式動態)
隱式動態通過為目標預測器引入高斯核平滑,形成了一種漸進式的 “動態噪聲引導”。在每一步生成中,對目標函數進行高斯平滑,逐步增加噪聲,并通過噪聲樣本計算梯度。這種操作使得樣本更容易跳出低概率區域,收斂至高目標密度區域。即使采用少量的采樣樣本,也能顯著提升生成樣本的多樣性和精度。
4. Recurrence(遞歸機制)
遞歸機制通過重復應用前述指導步驟來逐步強化生成結果。每一步去噪的中間結果被不斷 “回滾” 并重新生成,類似于一個動態優化的循環過程。每次遞歸的目的是修正前一輪生成的誤差,同時引入更多的指導信息。在標準的標簽指導任務(如 CIFAR10 和 ImageNet)中,遞歸次數的增加顯著提升了樣本準確率。例如,在 CIFAR10 數據集上,將遞歸次數從 1 增加到 4,準確率從 52% 提升到 77%,縮小了與基于訓練的指導方法的性能差距。
本文從理論上證明,已有的一些無訓練指導算法(例如 UGD,FreeDoM,MPGD,DPS,LGD)都是 TFG 的特例。TFG 構建了一個全面的超參數搜索空間,而已有的算法本質上都是在這個空間的某個子空間進行搜索。所以,TFG 將免訓練指導算法設計的問題轉化為:如何進行高效有效的超參數搜索?
設計空間的構建
TFG 框架的一個核心創新在于其設計空間(Design Space)的構建與超參數優化策略的提出。研究團隊對這一問題進行了系統分析,并提出了一種高效的通用搜索方法,具體由以下幾個超參數組成:
1. 時間相關向量:包括 ρ(Variance Guidance 強度) 和 μ(Mean Guidance 強度),分別控制梯度的影響力度及其在每個時間步的分布。
2. 時間無關標量:
:遞歸次數,決定了每個時間步的重復優化程度。
:梯度計算迭代次數,用于控制 Mean Guidance 的漸進式優化。
:用于 Implicit Dynamics 的高斯平滑參數。
這些參數的組合定義了 TFG 的設計空間 。研究表明,現有的無訓練指導方法(如 DPS、FreeDoM、UGD 等)可以被視為該設計空間的特殊情況,這意味著 TFG 實現了對這些方法的統一與擴展。為了更好地分析和使用設計空間,研究團隊提出了分解方法,將時間相關的向量(如 ρ 和 μ)分解為:
在設計空間中定義了三種結構:
1. Increase(遞增結構):如
通過實驗對比,研究團隊發現:ρ 和 μ 的遞增結構在多個任務中表現最佳,生成樣本的準確率和質量顯著提高;這一結果極大地簡化了設計空間的優化過程,為不同任務選擇合適的超參數提供了明確的指導。
高效超參數搜索策略
為了在廣泛的任務中實現高效優化,研究團隊設計了一種通用的超參數搜索策略,包括以下核心步驟:
1. 初始值設定:從較小的初始超參數值開始(如 ρ =μ=0.25),模擬無條件生成的效果。
2. 分步搜索:
- 在每次迭代中,分別對進行倍增(如從 0.25 增加到 0.5),生成多個新配置。
- 使用小規模的生成樣本測試新配置,評估其表現(例如 FID 和準確率)。
3. 選擇最佳配置:將表現最優的配置加入候選集,并重復搜索,直至搜索結果穩定或達到預設的迭代次數。
該搜索方法將生成樣本數量顯著減少,保證在合理的計算成本內完成優化。在計算資源有限的情況下,研究團隊建議將遞歸次數和迭代次數分別限制在 4 次以內,既能保證性能,又能控制計算復雜度。
實驗亮點:TFG 的廣泛適用性和卓越表現
1. 精細類別生成任務
精細類別指導(Fine-Grained Label Guidance)是一種比傳統標簽指導更具挑戰性的任務,旨在為擴散模型生成出滿足更細致條件的樣本。在這項研究中,TFG 首次將無訓練指導方法成功應用于超越訓練分布的細粒度標簽生成任務。
研究團隊選擇了鳥類圖像的細粒度標簽指導任務(例如基于鳥類的物種特征生成圖像)。這類任務的挑戰在于:
- 數據分布超出訓練模型的常見分布范圍,導致生成的樣本極易偏離目標特性。
- 即使對于成熟的文本 - 圖像生成模型(如 DALL-E),該問題也難以解決。
TFG 通過其遞歸增強(Recurrence)機制顯著提升了生成性能。在實驗中,TFG 成功生成了具有 2.24% 準確率的目標樣本,相比無條件生成(0% 準確率)是一個巨大飛躍。盡管絕對精度仍有提升空間,但這標志著無訓練指導方法在細粒度標簽生成領域的重要突破。
2. 分子生成任務
TFG 首次應用于分子生成任務的無訓練指導,利用無訓練指導優化分子屬性(如極化率、電偶極矩等)。實驗結果顯示,TFG 在有效性上顯著領先于現有方法,進一步拓展了擴散模型的應用邊界。
3. 多目標條件生成
TFG 在多屬性指導任務(如生成特定性別和發色組合的人臉)中展示了顯著的均衡性和適配性。通過對生成樣本進行詳細分析,研究團隊發現 TFG 有效緩解了由于訓練數據分布不平衡導致的生成偏差問題。例如,在 “男性 + 金發” 這一稀有目標組合中,TFG 的生成準確率高達 46.7%,遠高于原始數據分布中的 1%。
4. 音頻生成任務
在少有探索的音頻生成領域,TFG 同樣表現出色。實驗涵蓋了音頻修復(去剪裁、補全)等任務,相比其他方法,TFG 的相對性能提升超過 15%。
TFG 的未來展望:重新定義擴散模型的可能性
TFG 不僅為無訓練指導提供了統一理論基礎和實用工具,也為擴散模型在不同領域的拓展應用提供了新的思路。其核心優勢包括:
- 高效適應性:無需為每個任務額外訓練模型,顯著降低了條件生成的門檻;
- 廣泛兼容性:框架適用于從圖像到音頻、從分子到多目標生成的多種任務;
- 性能優越性:通過理論與實驗的結合,顯著提升了生成的準確性和質量。
未來,TFG 有望在藥物設計、精準醫學、復雜音頻生成、高級圖像編輯等領域進一步發揮作用。研究團隊還計劃優化框架,進一步縮小與基于訓練方法的性能差距。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
