

 新火種
2024-12-05
新火種
2024-12-05 


NeurIPS2024最佳論文揭曉!北大字節獲最佳論文,清華廈大為亞軍
就在剛剛,NeurIPS 2024最佳論文出爐!
4篇獲獎論文中,有3篇為華人一作,分別來自北大、新國立、廈大清華等。
據了解,NeurIPS 2024將于12月10日(星期二)至12月15日(星期日)在溫哥華舉辦。
和去年相比,今年能夠獲獎的難度再次升級——
本屆共收到15671篇有效論文投稿,比去年又增長了27%,但最后接收率僅有25.8%(去年為26.1%),大概4043篇左右。
接下來,快來康康獲獎論文有哪些吧~
兩篇最佳論文(Best Paper)1、《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》(視覺自回歸建模:通過Next-Scale預測生成可擴展圖像)
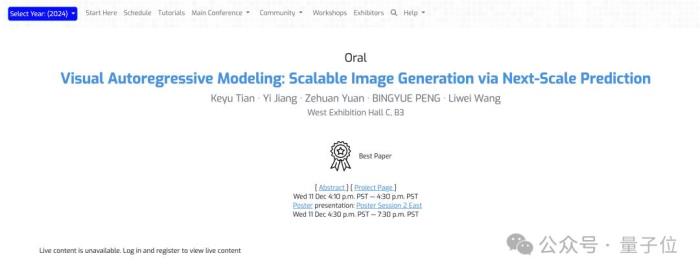
本文由北京大學、字節跳動研究者共同完成。
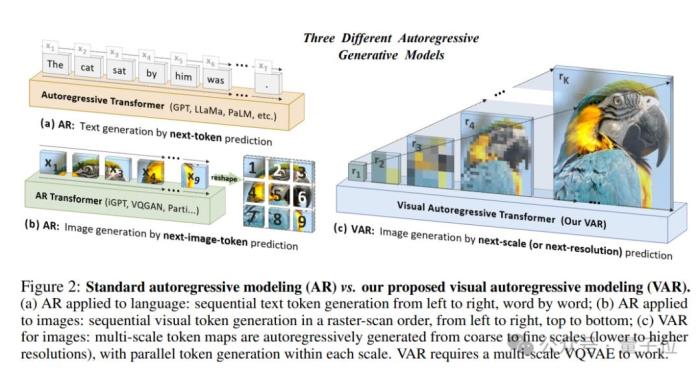
論文核心提出了一種新的圖像生成框架Visual Autoregressive modeling (VAR),首次使基于GPT風格的自回歸模型在圖像生成任務中超越了擴散模型,并驗證了VAR模型的可擴展性和零樣本泛化能力。
具體而言,論文引入了一種多尺度的自回歸策略。與傳統的按像素或token順序生成圖像的方法不同,VAR模型通過從低到高分辨的多尺度token圖進行自回歸生成,每一尺度的token圖都依賴于前一尺度的結果。
這種方法的一個關鍵優勢是,它能夠顯著減少生成高分辨率圖像時所需的自回歸步驟,從而降低了計算復雜度,提高了生成速度。
最終,VAR模型在ImageNet數據集上的驗證表明,它能顯著超越現有的自回歸模型和一些擴散模型,并且還表現出了視覺生成領域的Scaling Laws。
2、《Stochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators》(隨機泰勒導數估計器:任意微分算子的有效攤銷)

本文由新加坡國立大學、 Sea AI Lab研究者共同完成,論文一作為Zekun Shi。
論文核心介紹了一種名為Stochastic Taylor Derivative Estimator (STDE)?的高效算法,用于優化包含高維和高階微分算子的神經網絡損失函數,特別是在物理信息神經網絡(PINNs)中。
具體而言,研究展示了如何通過正確構造單變量高階AD輸入切線(input tangent),有效地對多元函數的任意階導數張量進行任意收縮,這可用于有效地隨機化任何微分算子。
當應用于PINNs時,與使用一階AD進行隨機化相比,本文方法提供了1000倍以上的速度提升和30倍以上的內存減少,而且現在可以在單個NVIDIA A100 GPU上,8分鐘內解決100萬維的偏微分方程(PDEs)。
總之,這項工作開啟了在大規模問題中使用高階微分算子的可能性。
 兩篇Best Paper Runner-up
兩篇Best Paper Runner-up(Best Paper Runner-up通常授予在某個領域表現杰出但未能獲得最佳論文的研究工作,大眾通常認為其水平代表亞軍)
1、《Not All Tokens Are What You Need for Pretraining》(并非所有token都是預訓練所需的)
本文由廈門大學、清華大學、微軟研究者共同完成,論文共同一作為Zhenghao Lin和Zhibin Gou(茍志斌)。
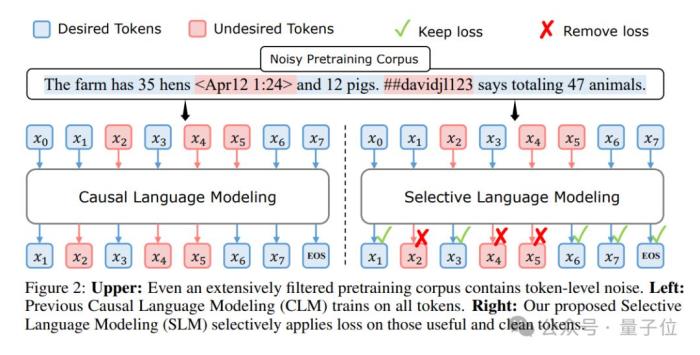
論文核心提出了一種新的名為RHO-1的語言模型預訓練方法,它挑戰了傳統的預訓練方法,即對所有訓練tokens應用下一個token預測損失。其主要觀點是,并非所有語料庫中的tokens對于語言模型訓練都同等重要。
通過分析不同tokens的訓練動態,論文發現不同tokens的損失模式存在差異,并且有些tokens的損失減少是顯著的,而有些則不然。
基于這些發現,論文引入了一種稱為選擇性語言建模(Selective Language Modeling, SLM)的新方法。SLM通過使用一個參考模型對tokens進行評分,然后只對評分較高的tokens進行訓練,從而選擇性地訓練有用的tokens。
這種方法在15B OpenWebMath語料庫上的持續預訓練中,使得RHO-1在9個數學任務上的少數樣本準確率(few-shot accuracy)實現了高達30%的絕對提升。在MATH數據集上,經過微調后,RHO-1的1B和7B模型分別達到了40.6%和51.8%的準確率,僅使用了DeepSeekMath所需預訓練tokens的3%。
此外,在對80B通用token進行持續預訓練時,RHO-1在15個不同任務上實現了6.8%的平均提升,數據效率和語言模型預訓練的性能都得到了提升。
不僅如此,論文還展示了SLM在數學和通用領域的有效性,并通過實驗和分析強調了在大語言模型預訓練過程中考慮token級別的重要性。
2、《Guiding a Diffusion Model with a Bad Version of Itself》(使用擴散模型的一個糟糕版本引導其自身)
本文由英偉達和阿爾托大學共同完成,論文一作為Tero Karras。
論文核心提出了一種名為自引導(autoguidance)的方法,通過使用主模型自身的一個較小、較少訓練的版本作為引導模型,來提高圖像生成質量。
論文指出,常見的無分類器引導方法是使用無條件模型來引導條件模型,這樣既能實現更好的提示詞對齊,也能得到更高質量的圖像,但代價是多變程度下降。而自引導方法通過引導模型的不完美性,能夠在不減少多樣性的情況下提高圖像質量。
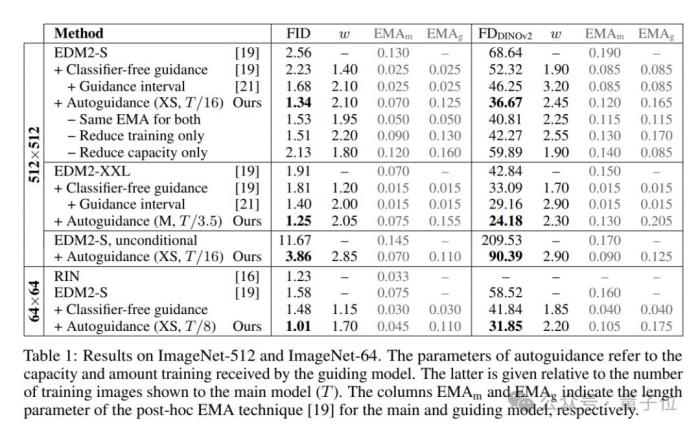
實驗表明,這能顯著提升ImageNet生成效果。論文使用公開可用的網絡,為64×64分辨率下的生成創造了1.01的FID記錄,為512×512創造了1.25的FID記錄。此外,該方法也適用于無條件擴散模型,可極大提高其質量。

最后,感興趣的家人們可以進一步查閱原論文~
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
