

 新火種
2024-12-03
新火種
2024-12-03 


NeurIPS2024|數(shù)學推理場景下,首個分布外檢測研究成果來了
 AIxiv專欄是機器之心發(fā)布學術(shù)、技術(shù)內(nèi)容的欄目。過去數(shù)年,機器之心AIxiv專欄接收報道了2000多篇內(nèi)容,覆蓋全球各大高校與企業(yè)的頂級實驗室,有效促進了學術(shù)交流與傳播。如果您有優(yōu)秀的工作想要分享,歡迎投稿或者聯(lián)系報道。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com本文將介紹數(shù)學推理場景下的首個分布外檢測研究成果。
AIxiv專欄是機器之心發(fā)布學術(shù)、技術(shù)內(nèi)容的欄目。過去數(shù)年,機器之心AIxiv專欄接收報道了2000多篇內(nèi)容,覆蓋全球各大高校與企業(yè)的頂級實驗室,有效促進了學術(shù)交流與傳播。如果您有優(yōu)秀的工作想要分享,歡迎投稿或者聯(lián)系報道。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com本文將介紹數(shù)學推理場景下的首個分布外檢測研究成果。
該篇論文已被 NeurIPS 2024 接收,第一作者王一鳴是上海交通大學計算機系的二年級博士生,研究方向為語言模型生成、推理,以及可解釋、可信大模型。該工作由上海交通大學和阿里巴巴通義實驗室共同完成。
論文題目:Embedding Trajectory for Out-of-Distribution Detection in Mathematical Reasoning
論文地址:https://arxiv.org/abs/2405.14039
OpenReview: https://openreview.net/forum?id=hYMxyeyEc5
代碼倉庫:https://github.com/Alsace08/OOD-Math-Reasoning
背景與挑戰(zhàn)分布外(Out-of-Distribution, OOD)檢測是防止深度網(wǎng)絡模型遭遇分布偏移數(shù)據(jù)時產(chǎn)生不可控輸出的重要手段,它對模型在現(xiàn)實世界中的部署安全起到了關鍵的作用。隨著語言模型的發(fā)展,復雜生成序列的錯誤傳播會使得 OOD 數(shù)據(jù)帶來的負面影響更加嚴重,因此語言模型下的 OOD 檢測算法變得至關重要。常規(guī)的檢測方法主要面向傳統(tǒng)生成任務(例如翻譯、摘要),它們直接計算樣本在輸入 / 輸出空間中的 Embedding 和分布內(nèi)(In-Distribution,ID)數(shù)據(jù)的 Embedding 分布之間的馬氏距離(Mahalanobis Distance)。然而,在數(shù)學推理場景下,這種靜態(tài) Embedding 方法遭遇了不可行性。研究團隊可視化比較了數(shù)學推理和傳統(tǒng)文本生成任務在不同域上的輸入 / 輸出空間: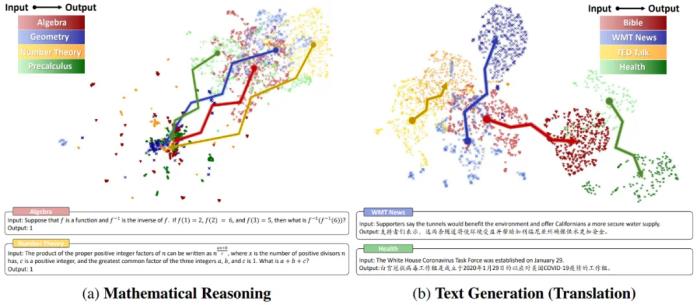
相比于文本生成,數(shù)學推理場景下不同域的輸入空間的聚類特征并不明顯,這意味著 Embedding 可能難以捕獲數(shù)學問題的復雜度;
更重要地,數(shù)學推理下的輸出空間呈現(xiàn)出高密度疊加特性。研究團隊將這種特性稱作 “模式坍縮”,它的出現(xiàn)主要有兩個原因:
(1) 數(shù)學推理的輸出空間是標量化的,這會增大不同域上的數(shù)學問題產(chǎn)生同樣答案的可能性。例如 和 這兩個問題的結(jié)果都等于 4;
(2) 語言模型的建模是分詞化的,這使得在數(shù)學意義上差別很大的表達式在經(jīng)過分詞操作后,共享大量的 token(數(shù)字 0-9 和有限的操作符)。研究團隊量化了這一觀察,其中表示出現(xiàn)的所有 token 數(shù),表示出現(xiàn)過的 token 種類, 表示 token 重復率,表示 token 種類在詞表中的占比,發(fā)現(xiàn)在一些簡單的算術(shù)場景下,token 重復率達到了驚人的 99.9%!
 為了應對這個挑戰(zhàn),研究團隊跳出了靜態(tài) Embedding 的方法框架,提出了一種全新的基于動態(tài) Embedding 軌跡 的 OOD 檢測算法,稱作 “TV Score”,以應對數(shù)學推理場景下的 OOD 檢測問題。動機與方法1. 定義:什么是 Embedding 軌跡?假設語言模型有 L 層,輸出文本包含 T 個 token,則第 t 個位置的 token 在第 l 層的 Embedding 輸出表示為
為了應對這個挑戰(zhàn),研究團隊跳出了靜態(tài) Embedding 的方法框架,提出了一種全新的基于動態(tài) Embedding 軌跡 的 OOD 檢測算法,稱作 “TV Score”,以應對數(shù)學推理場景下的 OOD 檢測問題。動機與方法1. 定義:什么是 Embedding 軌跡?假設語言模型有 L 層,輸出文本包含 T 個 token,則第 t 個位置的 token 在第 l 層的 Embedding 輸出表示為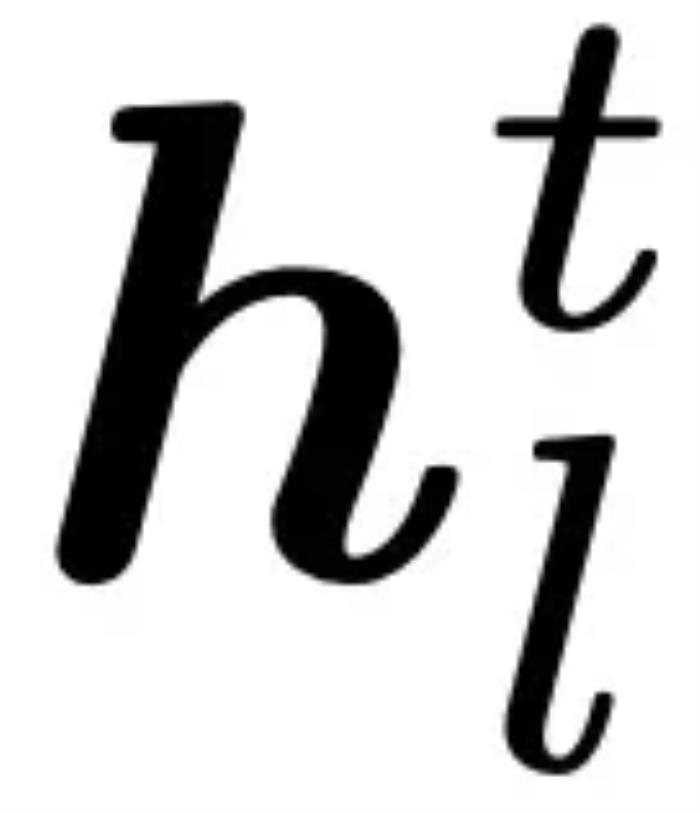 。現(xiàn)將每一層的平均 Embedding
。現(xiàn)將每一層的平均 Embedding 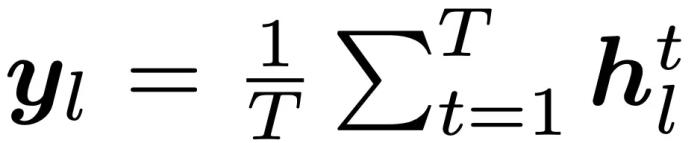 稱為第 l 層的句子 Embedding 表征,則動態(tài) Embedding 軌跡可形式化為一個遞進的 Embedding 鏈:
稱為第 l 層的句子 Embedding 表征,則動態(tài) Embedding 軌跡可形式化為一個遞進的 Embedding 鏈: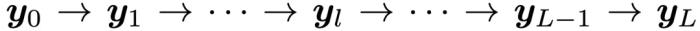 2. 動機:為什么用 Embedding 軌跡?
2. 動機:為什么用 Embedding 軌跡?理論直覺
在數(shù)學推理場景下,輸出空間具有顯著的高密度模式坍縮特征,這使得在輸入空間相差較大的兩個起始點,通過隱藏層轉(zhuǎn)移至輸出空間后,將收斂到非常近的距離。這個 “終點收斂” 現(xiàn)象將增大不同樣本的 Embedding 軌跡之間產(chǎn)生差異的可能性,如下圖所示。該理論分析的數(shù)學建模和證明詳見論文。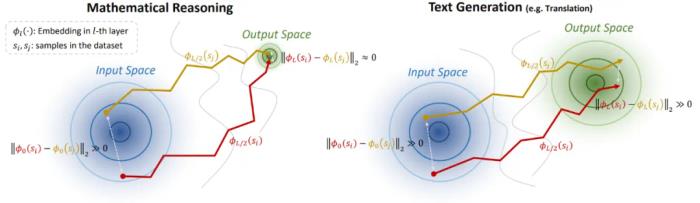
經(jīng)驗分析
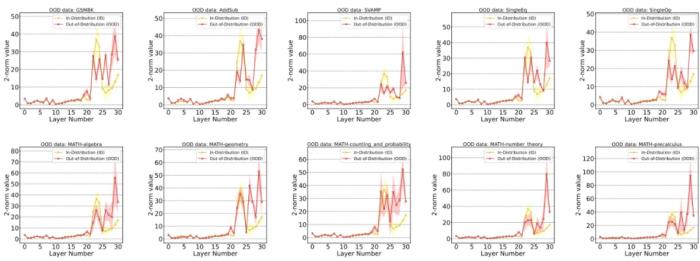
在初步獲取了使用 Embedding 軌跡作為測度的理論直覺后,需要繼續(xù)深入分析 ID 和 OOD 樣本的 Embedding 軌跡之間會產(chǎn)生怎樣的個性化差異。研究團隊在 Llama2-7B 模型上統(tǒng)計了不同的 ID 和 OOD 數(shù)據(jù)集下的 Embedding 軌跡特征。其中,橫坐標表示層數(shù),縱坐標表示該層與其鄰接層的 Embedding 之間的差值 2 - 范數(shù),數(shù)值越大表示這兩個鄰接層之間的 Embedding 轉(zhuǎn)換幅度越大。通過統(tǒng)計數(shù)據(jù)得出如下發(fā)現(xiàn):在 20 層之前,ID 和 OOD 樣本都幾乎沒有波動;在 20 層之后,ID 樣本的 Embedding 變化幅度先增大后又被逐漸抑制,而 OOD 樣本的 Embedding 變化幅度一直保持在相對較高的范圍;
通過這個觀察,可以得出 ID 樣本的 “過早穩(wěn)定” 現(xiàn)象:ID 樣本在中后層完成大量的推理過程,而后僅需做簡單的適應;而 OOD 樣本的推理過程始終沒有很好地完成 —— 這意味著 ID 樣本的 Embedding 轉(zhuǎn)換相對平滑。
 3. 方法:怎么用 Embedding 軌跡?基于上述發(fā)現(xiàn),研究團隊提出了 TV Score,它可以衡量一個樣本屬于 ID 或 OOD 類別的可能性。受到靜態(tài) Embedding 方法的啟發(fā),文章希望通過計算新樣本的 Embedding 軌跡和 ID 樣本的 Embedding 軌跡分布之間的距離來獲取測度,但軌跡分布和軌跡距離的計算并不直觀。因此,文章將 TV Score 的計算分為了三個步驟:
3. 方法:怎么用 Embedding 軌跡?基于上述發(fā)現(xiàn),研究團隊提出了 TV Score,它可以衡量一個樣本屬于 ID 或 OOD 類別的可能性。受到靜態(tài) Embedding 方法的啟發(fā),文章希望通過計算新樣本的 Embedding 軌跡和 ID 樣本的 Embedding 軌跡分布之間的距離來獲取測度,但軌跡分布和軌跡距離的計算并不直觀。因此,文章將 TV Score 的計算分為了三個步驟:首先,將每一層 l 的 ID Embedding 擬合為一個高斯分布:
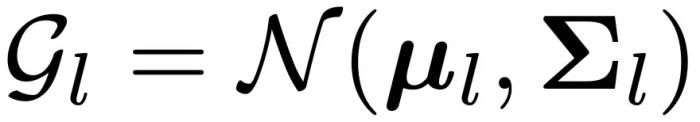
其次,對于一個新樣本,在獲取了每一層的 Embedding  后,計算它和該層高斯分布之間的馬氏距離:
后,計算它和該層高斯分布之間的馬氏距離:
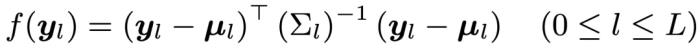
最后,將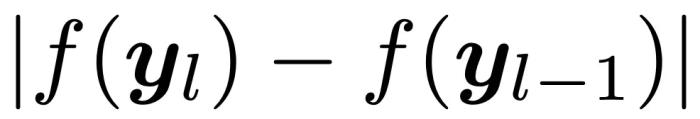 視為新樣本的相鄰層波動率,并取所有相鄰層波動率的平均值作為該樣本的最終軌跡波動率得分:
視為新樣本的相鄰層波動率,并取所有相鄰層波動率的平均值作為該樣本的最終軌跡波動率得分:
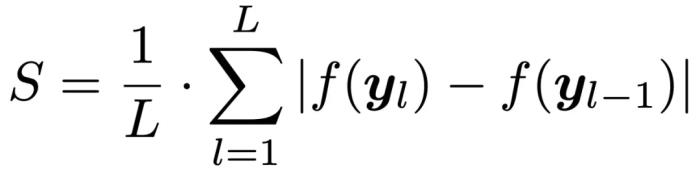
 進一步地,考慮到軌跡中的異常點可能會影響特征提取的精度,研究團隊在此基礎上加入了差分平滑技術(shù) (Differential Smoothing, DiSmo):
進一步地,考慮到軌跡中的異常點可能會影響特征提取的精度,研究團隊在此基礎上加入了差分平滑技術(shù) (Differential Smoothing, DiSmo):首先,定義每一層的 k 階 Embedding 和高斯分布:
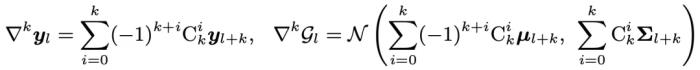
其次,計算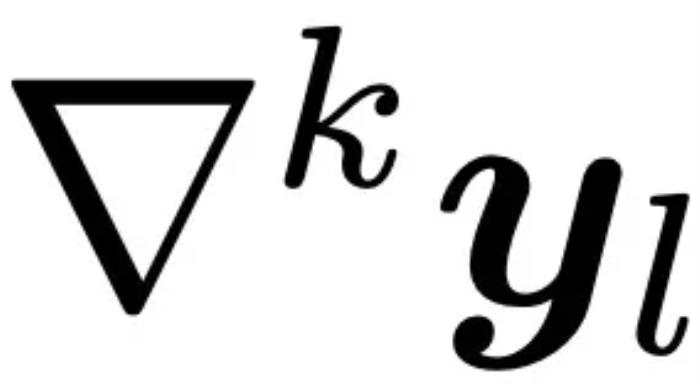 和
和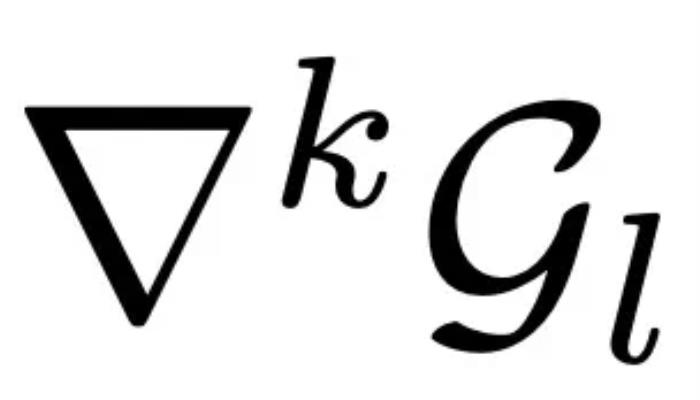 之間的馬氏距離:
之間的馬氏距離:
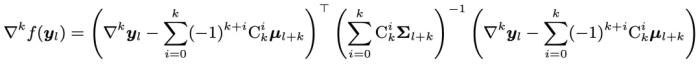
最后,類似 TV Score 定義差分平滑后的得分:
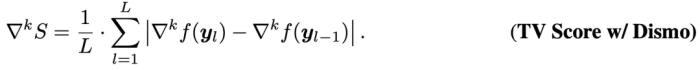 實驗與結(jié)果研究團隊使用了 11 個數(shù)學推理數(shù)據(jù)集(其中 1 個 ID 數(shù)據(jù)集和 10 個 OOD 數(shù)據(jù)集)在兩個不同規(guī)模的語言模型(Llama2-7B 和 GPT2-XL)上進行了實驗。根據(jù)和 ID 數(shù)據(jù)集之間的難度差異大小,這 10 個 OOD 數(shù)據(jù)集被分為兩組,分別代表 Far-shift OOD 和 Near-shift OOD。實驗在離線檢測和在線檢測這兩個場景下進行:離線檢測場景:給定一組 ID 和 OOD 樣本的混合集合,檢測 TV Score 對這兩類樣本的區(qū)分精度(本質(zhì)上是一個判別任務)。評估指標采用 AUROC 和 FPR95。
實驗與結(jié)果研究團隊使用了 11 個數(shù)學推理數(shù)據(jù)集(其中 1 個 ID 數(shù)據(jù)集和 10 個 OOD 數(shù)據(jù)集)在兩個不同規(guī)模的語言模型(Llama2-7B 和 GPT2-XL)上進行了實驗。根據(jù)和 ID 數(shù)據(jù)集之間的難度差異大小,這 10 個 OOD 數(shù)據(jù)集被分為兩組,分別代表 Far-shift OOD 和 Near-shift OOD。實驗在離線檢測和在線檢測這兩個場景下進行:離線檢測場景:給定一組 ID 和 OOD 樣本的混合集合,檢測 TV Score 對這兩類樣本的區(qū)分精度(本質(zhì)上是一個判別任務)。評估指標采用 AUROC 和 FPR95。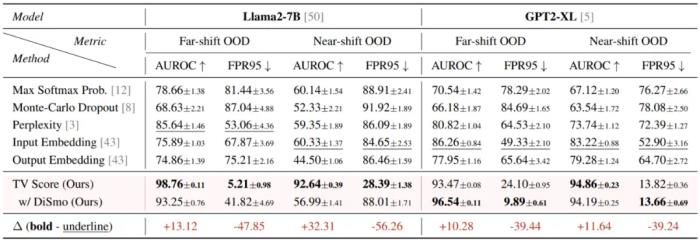
在 Far-shift OOD 場景下:AUROC 指標提高了 10 個點以上,F(xiàn)PR95 指標更是降低了超過 80%;
在 Near-shift OOD 場景下:TV Score 展現(xiàn)出更強的魯棒性。Baseline 方法從 Far-shift 轉(zhuǎn)移到 Near-shift 場景后,性能出現(xiàn)明顯下降,而 TV Score 仍然保持卓越的性能。這說明對于更精細的 OOD 檢測場景,TV Score 表現(xiàn)出更強的適應性。
在線檢測場景:在離線檢測場景中獲取一個分類閾值,之后面對新的開放世界樣本時,可以通過和閾值的大小比較自動判定屬于 ID 或 OOD 類別。評估指標采用 Accuracy。結(jié)果表明,TV Score 在開放世界場景下仍然具有十分優(yōu)秀的判別準確度。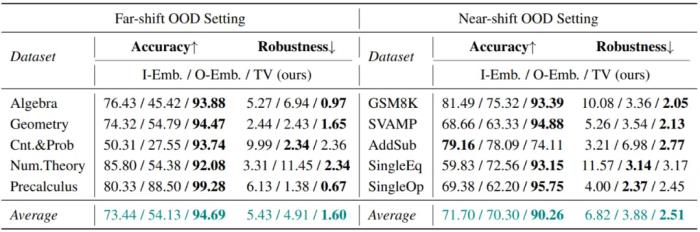 泛化性測試研究團隊還對 TV Score 的泛化性進行了進一步的測試,主要分為任務泛化和場景泛化兩個方面:任務泛化:測試了 OOD 場景下的生成質(zhì)量估計,使用 Kendall 和 Spearman 相關系數(shù)來計算 TV Score 和模型回答正確性之間的相關性。結(jié)果表明,TV Score 在該任務下仍然展現(xiàn)出了最優(yōu)性能。
泛化性測試研究團隊還對 TV Score 的泛化性進行了進一步的測試,主要分為任務泛化和場景泛化兩個方面:任務泛化:測試了 OOD 場景下的生成質(zhì)量估計,使用 Kendall 和 Spearman 相關系數(shù)來計算 TV Score 和模型回答正確性之間的相關性。結(jié)果表明,TV Score 在該任務下仍然展現(xiàn)出了最優(yōu)性能。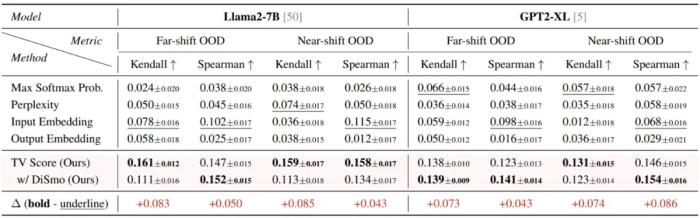 場景泛化:研究團隊認為,TV Score 可以被推廣到所有輸出空間滿足 “模式坍縮” 特性的場景,例如多項選擇題,因為它的輸出空間僅包含 ABCD 等選項。文章選取了 MMLU 數(shù)據(jù)集,從中挑選了 8 個域的子集,依次作為 ID 子集來將剩余 7 個域作為 OOD 檢測目標。結(jié)果表明,TV Score 仍然展現(xiàn)出良好的性能,這驗證了它在更豐富場景下的使用價值。
場景泛化:研究團隊認為,TV Score 可以被推廣到所有輸出空間滿足 “模式坍縮” 特性的場景,例如多項選擇題,因為它的輸出空間僅包含 ABCD 等選項。文章選取了 MMLU 數(shù)據(jù)集,從中挑選了 8 個域的子集,依次作為 ID 子集來將剩余 7 個域作為 OOD 檢測目標。結(jié)果表明,TV Score 仍然展現(xiàn)出良好的性能,這驗證了它在更豐富場景下的使用價值。 總結(jié)本文是 OOD 檢測算法在數(shù)學推理場景下的首次探索。該工作不僅揭示了傳統(tǒng)檢測算法在數(shù)學推理場景下的不適用性,還提出了一種全新的基于動態(tài) Embedding 軌跡的檢測算法,可以精準適配數(shù)學推理場景。隨著大模型的發(fā)展,模型的應用場景越來越廣泛,而這些場景也越來越具有挑戰(zhàn)性,早已不局限于最傳統(tǒng)的文本生成任務。因此,傳統(tǒng)安全算法在新興場景下的跟進也是維護大模型在真實世界中穩(wěn)定且安全地發(fā)揮作用的不可或缺的一環(huán)。
總結(jié)本文是 OOD 檢測算法在數(shù)學推理場景下的首次探索。該工作不僅揭示了傳統(tǒng)檢測算法在數(shù)學推理場景下的不適用性,還提出了一種全新的基于動態(tài) Embedding 軌跡的檢測算法,可以精準適配數(shù)學推理場景。隨著大模型的發(fā)展,模型的應用場景越來越廣泛,而這些場景也越來越具有挑戰(zhàn)性,早已不局限于最傳統(tǒng)的文本生成任務。因此,傳統(tǒng)安全算法在新興場景下的跟進也是維護大模型在真實世界中穩(wěn)定且安全地發(fā)揮作用的不可或缺的一環(huán)。 相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
