

 新火種
2024-11-28
新火種
2024-11-28 


第一個國產(chǎn)中文o1來了,直接數(shù)學競賽題伺候!
家人們,o1大模型,最近著實是有點火啊。
就在今天,昆侖萬維的Skywork o1首發(fā)中文邏輯推理能力,并開啟了邀測。
那一波實測,這不就得安排一下么。
類似o1模型最大的特點就是其強悍的推理能力,因此,我們直接上一道AIME數(shù)學競賽題,看看夠不夠“開門”。
(AIME:美國數(shù)學邀請賽,是介于AMC10、AMC12及美國數(shù)學奧林匹克競賽之間的一個數(shù)學競賽。)

題目翻譯過來是這樣的:
上下滑動查看所有內(nèi)容:

從Skywork o1整體的回答來看,它先是將問題分解為不同場景,通過建立方程組描述步行速度、時間和距離的關系。
隨后利用代數(shù)方法求解,確保了表達式簡化和單位換算的正確性。
而比較重要的一點,是Skywork o1可以代入結(jié)果驗證計算過程的自洽性,并明確得出總時間。
最終,它所給出的答案“204”,與今年AIME這道題的標準答案一致。
接下來,我們再拿今年的高考數(shù)學題做一番測試。
AI請聽題:
對于這個問題,Skywork o1給出的思考和答案如下(上下滑動查看所有內(nèi)容):

AI整體的思路和剛才一樣,都是屬于分步而治之,主打的就是一個step by step。
期間哪怕是遇到“陷阱”,Skywork o1也會及時發(fā)現(xiàn)并提醒自己,整個過程宛如把人類思考的過程復刻并呈現(xiàn)了出來一般。
最終給出的答案也是與標準答案一致。
需要注意的是,Skywork o1其實是一個系列,更具體而言,包括三個細分模型:
Skywork o1 Open:基于Llama 3.1的8B開源模型,解鎖了許多輕量級模型無法解決的復雜數(shù)學任務。Skywork o1 Lite:具備完整的思考能力,具有更好的中文支持和更快的推理和思考速度。Skywork o1 Preview:本次完整版的推理模型,搭配自研的線上推理算法,使推理過程更完善、高質(zhì)量。不僅如此,Skywork o1 Open也參與到了類o1模型Benchmark的比較,能力上可謂是有了大幅的提高。
將Llama-3.1-8B的性能拉到同生態(tài)位SOTA(超越Qwen-2.5-7B-Instruct)。
同時,8B的Skywork o1 Open也解鎖了很多較大量級模型,如GPT 4o,無法完成的數(shù)學推理任務(如24點計算)。
這也為推理模型在輕量級設備上部署提供了可能性。


△
在MATH數(shù)據(jù)集上,Q*(論文地址:https://arxiv.org/abs/2406.14283)幫助Llama-3.1-7B提升并超越了同生態(tài)位的SOTA Qwen2.5-7B-instruct。
同時,昆侖萬維也將開源兩個的推理任務的Process Reward Model(PRM):Skywork o1 Open-PRM-1.5B 和Skywork o1 Open-PRM-7B,相比此前開源的Skywork-Reward-Model僅對整個模型回答進行打分,Skywork o1 Open-PRM能給模型回答中的每個步驟進行打分。
對比開源社區(qū)現(xiàn)有的PRM,Skywork o1 Open-PRM-1.5B能達到開源社區(qū)8B的模型效果,例如RLHFlow的Llama3.1-8B-PRM-Deepseek-Data,OpenR的Math-psa-7B,Skywork o1 Open-PRM-7B能同時在大部分benchamrk上接近/超過10倍量級的Qwen2.5-Math-RM-72B。
Skywork o1 Open-PRM也是第一款適配代碼類任務的開源PRM。下面表格為以Skywork-o1-Open-8B作為基礎模型,使用不同PRM在數(shù)學和代碼評測集上的評估結(jié)果。


詳細技術報告也將在不久后發(fā)布。目前模型和相關介紹已在Huggingface開源 (https://tinyurl.com/skywork-o1)。
那么除了純數(shù)學題之外,Skywork o1在其它推理任務上的表現(xiàn)又會如何?
接下來,我們繼續(xù)用更多維度的測試來考驗一番。
AI自我思考、規(guī)劃和反思9.9和9.11哪個大?首先,我們就用曾經(jīng)難倒一眾AI大模型的經(jīng)典問題“9.9和9.11哪個大”來做一下測試。
雖然現(xiàn)在幾乎所有大模型都能給出正確答案,但在這個測試中,我們將更關注AI思考的過程。

從過程來看,Skywork o1依然采用分而治之的策略。
先比較整數(shù)位,判定二者的整數(shù)位相同;再判斷小數(shù)位,將其轉(zhuǎn)換為相同的格式,即0.90和0.11之間的比較,判定9.9大于9.11。
最后,Skywork o1還是把過程再次驗證了一遍,認定結(jié)果是正確的。
從它的思路來看,和人類比較這兩個數(shù)字的邏輯是一致的。
腦筋急轉(zhuǎn)彎接下來,我們再來一道腦筋急轉(zhuǎn)彎:

對于這樣的腦筋急轉(zhuǎn)彎,很多人思考的過程,會先看下是否符合常理;若是屬于“不按套路出牌”的那種,就會再找找題面有沒有trick了。
那么到了AI這邊,它又會如何思考?

Skywork o1先審視了一下題目,初步判定不符合常理,應當就開始抓細節(jié)了,腦洞大開地想了好幾種可能。
例如又有人放了2個蘋果進去、畫上去的蘋果、光學錯覺、箱子里有鏡子等等……
但上述的想法都被自己給否了,理由是太牽強。
最后,Skywork o1認定,這個題目的trick就在“拿走”這個詞兒身上,給出的解釋也是正解:
加密問題測試大模型的邏輯推理,加密問題可以說是一種非常適合的類型。
因為加密問題往往需要從有限的已知條件推導出未知信息,這需要模型具備強大的邏輯推理能力,能夠在多個條件之間找到關聯(lián)并推導出結(jié)論。
那么,話不多說,AI請聽題:

Skywork o1從已知的加密規(guī)則和密文-明文對中歸納出字符映射關系,并基于映射規(guī)則對新密文進行解碼。
在這個過程中,模型邏輯清晰,分步拆解問題,逐步驗證假設,并在映射不完整的情況下,通過推測加密模式進一步完善解碼方案。
尤其是它對加密規(guī)則的歸納能力,不僅識別了每個字母被映射為兩個字符的規(guī)律,還通過字符位置和字母表的偏移發(fā)現(xiàn)了加密過程的具體算法(奇偶位置的偏移邏輯)。
但也并非完美雖然Skywork o1在目前種種推理任務中表現(xiàn)還算不錯,但當我們把任務難度降到極低的時候,也發(fā)現(xiàn)了一個問題——有點啰嗦了。
例如問它“1+1等于幾”:

Emmmm……繁瑣,著實有點繁瑣了。
但同時,模型考慮到了這道問題是否是在問不同進制情況下的答案,也體現(xiàn)了模型多樣性的思考能力。
不過在與昆侖萬維團隊交流過程中我們得知,對于這樣簡單的問題,團隊后續(xù)也會進一步對Skywork o1的解答做優(yōu)化。
在看完效果之后,接下來的一個問題便是:
怎么做到的?整體來看,Skywork o1之所以能有如此的思考、規(guī)劃及反思能力,主要得益于一個三階段的自研技術方案。
首先第一階段,是一個推理反思能力訓練的過程。
Skywork o1通過自研的多智能體體系構(gòu)造出高質(zhì)量的分步思考、反思和驗證數(shù)據(jù)。
這些多樣化的長思考數(shù)據(jù)用于對基礎模型進行進一步的預訓練和監(jiān)督微調(diào),從而提升了模型在復雜任務中的推理能力。
其次第二階段,是推理能力強化學習。
Skywork o1團隊研發(fā)了Skywork o1 Process Reward Model(PRM),適用于分步推理的強化學習過程。
該模型能夠有效捕捉到復雜推理任務中每一步對最終答案的影響;通過結(jié)合自研的分步推理強化算法,模型的推理和思考能力得到了顯著增強。
PRM的核心在于其對推理過程的精細化獎勵機制。
傳統(tǒng)的強化學習模型往往只關注最終結(jié)果的正確性,而PRM則在每一個推理步驟中引入了獎勵評估,從而確保模型能夠在每一步中不斷優(yōu)化其推理路徑。
PRM能夠?qū)δP偷拿恳粋€思考過程進行評分,從而幫助模型糾正錯誤思維鏈,提升整體推理質(zhì)量。
Skywork o1團隊還在PRM中加入了多任務訓練數(shù)據(jù),使其不僅能夠在單一領域表現(xiàn)出色,同時具備在多樣化任務場景中靈活應用的能力。
通過這種方式,Skywork o1能夠有效應對各類復雜的推理挑戰(zhàn)。
最后,則是推理規(guī)劃(planning)。
這也是昆侖萬維首次將Q*算法應用并公開,用于線上推理。
Q*算法與模型的在線思考能力結(jié)合,能夠?qū)ふ易罴淹评砺窂剑瑥亩@著提高了模型的在線推理能力。
值得一提的是,這也是全球首次實現(xiàn)Q*算法落地,使得Skywork o1的推理能力進一步領先于其他同類模型。
為什么類o1模型重要?早在Sam Altman發(fā)布o1模型之際,他便對此問題做了一些點評:
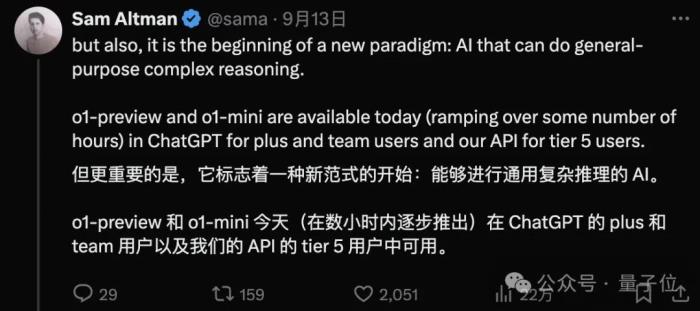
這一趨勢也離不開行業(yè)發(fā)展的大背景,即市場對于具有強大推理能力的模型需求日益增加。
而類o1模型模型的推出,正好滿足了這一需求,尤其是在需要復雜邏輯推理的應用場景中,如科學研究、編程、數(shù)據(jù)分析等領域。
因為它們對性能提升方式不同于傳統(tǒng)的大規(guī)模預訓練方式(通過增加參數(shù)量和數(shù)據(jù)量),是通過增加推理時的算力和時間投入,實現(xiàn)了性能的顯著提升,這為模型的發(fā)展帶來了新的Scaling Law。
并且通過內(nèi)置思維鏈(CoT)逐步解決問題的方式,一定程度上模擬了人類慢思考過程;這種方式使得模型在推理時能夠進行自我糾正,當模型檢測到偏離正確的推理路徑時,它可以回溯并嘗試其他方案。
一言蔽之,是符合市場和行業(yè)硬需求。
而縱觀昆侖萬維在大模型時代這兩年的表現(xiàn),毫不夸張的說,每一次的技術新潮來臨之際,國產(chǎn)選手中定然有它的身影出現(xiàn),而且是屬于早一批的那種。
例如其大底座天工大模型系列,包括天工1.0、天工2.0、天工3.0,以及今天正式邀請測試的「天工大模型4.0」 o1版(Skywork o1)。
其次在其它模態(tài)上,還包括AI搜索(天工AI搜索)、AI音樂(天工SkyMusic)、AI社交(Linky)、AI視頻(AI短劇平臺SkyReels)、實時語音對話助手(Skyo)等。
并且開源,也是從昆侖萬維從一開始布局至今以來的特點之一;正如此次的開源模型Skywork o1 Open,也將加速國內(nèi)開源社區(qū)復現(xiàn)o1的進程。
最后,Skywork o1邀測地址放下面嘍,感興趣的小伙伴快去申請吧~
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
