

 新火種
2024-11-27
新火種
2024-11-27 

撞墻還是新起點(diǎn)?自回歸模型在圖像領(lǐng)域展現(xiàn)出Scaling潛力
自回歸方法,在圖像生成中觀(guān)察到了 Scaling Law。 還有人指出,其實(shí),在文本以外的領(lǐng)域,Scaling Law 的蹤跡正在逐漸顯現(xiàn),比如時(shí)間序列預(yù)測(cè)以及圖像、視頻這類(lèi)視覺(jué)領(lǐng)域。下面這張圖來(lái)自投稿給 ICLR 2025 的一篇論文。論文發(fā)現(xiàn),在把類(lèi)似于 GPT 的自回歸模型應(yīng)用于圖像生成時(shí),Scaling Law 同樣可以被觀(guān)察到。具體表現(xiàn)為:隨著模型大小的增加,訓(xùn)練損失會(huì)降低,模型生成性能會(huì)提高,捕捉全局信息的能力也會(huì)增強(qiáng)。
還有人指出,其實(shí),在文本以外的領(lǐng)域,Scaling Law 的蹤跡正在逐漸顯現(xiàn),比如時(shí)間序列預(yù)測(cè)以及圖像、視頻這類(lèi)視覺(jué)領(lǐng)域。下面這張圖來(lái)自投稿給 ICLR 2025 的一篇論文。論文發(fā)現(xiàn),在把類(lèi)似于 GPT 的自回歸模型應(yīng)用于圖像生成時(shí),Scaling Law 同樣可以被觀(guān)察到。具體表現(xiàn)為:隨著模型大小的增加,訓(xùn)練損失會(huì)降低,模型生成性能會(huì)提高,捕捉全局信息的能力也會(huì)增強(qiáng)。 論文標(biāo)題:Elucidating the design space of language models for image generation論文鏈接:https://arxiv.org/pdf/2410.16257代碼與模型:https://github.com/Pepper-lll/LMforImageGeneration論文作者之一、云天勵(lì)飛的齊憲標(biāo)博士在接受機(jī)器之心采訪(fǎng)時(shí)表示:「我們不知道圖像中的 Scaling Law 到底有多強(qiáng),比如如果我們把圖像生成模型也擴(kuò)展到 Llama 7B 這個(gè)規(guī)模,是不是 GPT 那樣的自回歸方法也具有非常大的潛力?」抱著這個(gè)想法,他們進(jìn)行了一些初步實(shí)驗(yàn),發(fā)現(xiàn)只訓(xùn)練到一半的時(shí)候,自回歸模型就已經(jīng)在圖像生成任務(wù)上表現(xiàn)出了很強(qiáng)的 Scaling Law。這讓他們對(duì)自回歸方法在視覺(jué)領(lǐng)域的應(yīng)用充滿(mǎn)信心。可見(jiàn),至少在圖像和視頻生成等領(lǐng)域,Scaling Law 依然強(qiáng)勢(shì),離撞墻還遠(yuǎn)。在另一篇論文中,齊憲標(biāo)等人還發(fā)現(xiàn),其實(shí)在應(yīng)用于圖像領(lǐng)域時(shí),傳統(tǒng)的自回歸方法也有改進(jìn)空間。他們把改進(jìn)后的方法稱(chēng)為「BiGR 」,該方法建立在何愷明等人 MAR(masked autoregressive)工作的基礎(chǔ)之上,并在一些方面實(shí)現(xiàn)了改進(jìn),成為了首個(gè)將生成和判別任務(wù)統(tǒng)一在同一框架內(nèi)的條件生成模型。這意味著,BiGR 不僅是一個(gè)好的圖像生成器,同時(shí)還是一個(gè)強(qiáng)大的特征提取器,二者是相互促進(jìn)的關(guān)系。
論文標(biāo)題:Elucidating the design space of language models for image generation論文鏈接:https://arxiv.org/pdf/2410.16257代碼與模型:https://github.com/Pepper-lll/LMforImageGeneration論文作者之一、云天勵(lì)飛的齊憲標(biāo)博士在接受機(jī)器之心采訪(fǎng)時(shí)表示:「我們不知道圖像中的 Scaling Law 到底有多強(qiáng),比如如果我們把圖像生成模型也擴(kuò)展到 Llama 7B 這個(gè)規(guī)模,是不是 GPT 那樣的自回歸方法也具有非常大的潛力?」抱著這個(gè)想法,他們進(jìn)行了一些初步實(shí)驗(yàn),發(fā)現(xiàn)只訓(xùn)練到一半的時(shí)候,自回歸模型就已經(jīng)在圖像生成任務(wù)上表現(xiàn)出了很強(qiáng)的 Scaling Law。這讓他們對(duì)自回歸方法在視覺(jué)領(lǐng)域的應(yīng)用充滿(mǎn)信心。可見(jiàn),至少在圖像和視頻生成等領(lǐng)域,Scaling Law 依然強(qiáng)勢(shì),離撞墻還遠(yuǎn)。在另一篇論文中,齊憲標(biāo)等人還發(fā)現(xiàn),其實(shí)在應(yīng)用于圖像領(lǐng)域時(shí),傳統(tǒng)的自回歸方法也有改進(jìn)空間。他們把改進(jìn)后的方法稱(chēng)為「BiGR 」,該方法建立在何愷明等人 MAR(masked autoregressive)工作的基礎(chǔ)之上,并在一些方面實(shí)現(xiàn)了改進(jìn),成為了首個(gè)將生成和判別任務(wù)統(tǒng)一在同一框架內(nèi)的條件生成模型。這意味著,BiGR 不僅是一個(gè)好的圖像生成器,同時(shí)還是一個(gè)強(qiáng)大的特征提取器,二者是相互促進(jìn)的關(guān)系。 論文標(biāo)題:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities論文鏈接:https://arxiv.org/pdf/2410.14672代碼與模型:https://github.com/haoosz/BiGR這些工作為研究界繼續(xù)探索自回歸模型在視覺(jué)領(lǐng)域的 Scaling Law 提供了一些啟發(fā)。在這篇文章中,我們將對(duì)這些工作進(jìn)行深入解讀。順帶一提,這兩項(xiàng)研究的代碼和模型都已發(fā)布。自回歸:Diffusion 之外的另一條道路在當(dāng)前的視覺(jué)生成領(lǐng)域,Diffusion 模型是毫無(wú)疑問(wèn)的霸主。這種方法生成的圖像質(zhì)量較高,視頻也越來(lái)越好。但另一方面,以 Transformer 為代表的自回歸模型在文本領(lǐng)域的成功就在眼前,這不禁讓人去想象自回歸模型在視覺(jué)領(lǐng)域的可能性。其實(shí),早在 2018 年,谷歌的一個(gè)團(tuán)隊(duì)(其中大部分是 Transformer 論文作者)就已經(jīng)探索過(guò)用自回歸模型來(lái)生成圖像(參見(jiàn)論文《Image Transformer》)。OpenAI 的初代 DALL?E 模型用的也是基于自回歸的方法。但由于探索初期效果不佳,再加上 Diffusion 模型的強(qiáng)勢(shì)崛起和開(kāi)源,基于自回歸的方法逐漸淡出了大部分研究者的視野。
論文標(biāo)題:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities論文鏈接:https://arxiv.org/pdf/2410.14672代碼與模型:https://github.com/haoosz/BiGR這些工作為研究界繼續(xù)探索自回歸模型在視覺(jué)領(lǐng)域的 Scaling Law 提供了一些啟發(fā)。在這篇文章中,我們將對(duì)這些工作進(jìn)行深入解讀。順帶一提,這兩項(xiàng)研究的代碼和模型都已發(fā)布。自回歸:Diffusion 之外的另一條道路在當(dāng)前的視覺(jué)生成領(lǐng)域,Diffusion 模型是毫無(wú)疑問(wèn)的霸主。這種方法生成的圖像質(zhì)量較高,視頻也越來(lái)越好。但另一方面,以 Transformer 為代表的自回歸模型在文本領(lǐng)域的成功就在眼前,這不禁讓人去想象自回歸模型在視覺(jué)領(lǐng)域的可能性。其實(shí),早在 2018 年,谷歌的一個(gè)團(tuán)隊(duì)(其中大部分是 Transformer 論文作者)就已經(jīng)探索過(guò)用自回歸模型來(lái)生成圖像(參見(jiàn)論文《Image Transformer》)。OpenAI 的初代 DALL?E 模型用的也是基于自回歸的方法。但由于探索初期效果不佳,再加上 Diffusion 模型的強(qiáng)勢(shì)崛起和開(kāi)源,基于自回歸的方法逐漸淡出了大部分研究者的視野。 初代 DALL?E 生成效果云天勵(lì)飛的這些研究更像是一種「重新探索」,而且這次探索有很多可以借鑒的經(jīng)驗(yàn)教訓(xùn)。正如齊憲標(biāo)說(shuō)的那樣:「在我們重新探索這條路的時(shí)候,這些經(jīng)驗(yàn)其實(shí)可以讓我們思考過(guò)去走這條路的時(shí)候可能哪個(gè)地方?jīng)]走好。」關(guān)于這種「重新探索」的動(dòng)機(jī),齊憲標(biāo)分享了幾個(gè)觀(guān)點(diǎn)。第一個(gè)是關(guān)于 Scaling Law 的。正如前面所提到的,自回歸方法的可擴(kuò)展性已經(jīng)在文本領(lǐng)域得到了驗(yàn)證,最大的文本模型已經(jīng)做到了萬(wàn)億參數(shù)。而在圖像領(lǐng)域,這種 Scaling Law 才剛剛顯現(xiàn),未來(lái)還存在巨大的探索空間。第二個(gè)是關(guān)于多模態(tài)理解和生成的統(tǒng)一。在當(dāng)前「scaling law 撞墻」的相關(guān)討論中,多模態(tài)其實(shí)是一個(gè)被寄予厚望的方向。但是,這個(gè)領(lǐng)域目前面臨一個(gè)嚴(yán)峻的挑戰(zhàn),即多模態(tài)的理解和生成是分開(kāi)進(jìn)行的,這就造成理解模型的理解能力強(qiáng)而生成能力弱,生成模型則相反。統(tǒng)一這兩類(lèi)任務(wù),可以促進(jìn)模型學(xué)到更通用的語(yǔ)義表征,還能讓模型更好地探索數(shù)據(jù)中的潛在規(guī)律,從而增強(qiáng)模型在跨模態(tài)任務(wù)中的泛化性。而自回歸方法的好處就在于它有一個(gè) token 化的過(guò)程。無(wú)論什么模態(tài),只要經(jīng)過(guò)了 token 化,生成和理解就可以很容易被統(tǒng)一在一個(gè)框架里面。相比之下,基于 Diffusion 的方法就缺乏這種靈活性。除此之外,自回歸方法用于視覺(jué)任務(wù)還有很多好處,比如模型指令遵循能力更強(qiáng),之前在文本模型領(lǐng)域積累的經(jīng)驗(yàn)、資源可以復(fù)用等等。這些原因驅(qū)使齊憲標(biāo)和他的同事跳出 Diffusion 這條「主路」,走回了自回歸這條已經(jīng)相對(duì)冷門(mén)的路線(xiàn)。在圖像上 Scaling 有效以及生成和判別的統(tǒng)一要理解 BiGR 和 ELM 的意義,我們得從離散化的圖像和文本的 token 分布談起。齊憲標(biāo)表示:「我們得把一個(gè)圖像塊表示成一個(gè)單詞。如果只是單純的硬編碼,我們是做不到的,因?yàn)樗目臻g太大了。所以,我們首先就是想辦法來(lái)表示圖像。這也就是所謂的 token 化。」
初代 DALL?E 生成效果云天勵(lì)飛的這些研究更像是一種「重新探索」,而且這次探索有很多可以借鑒的經(jīng)驗(yàn)教訓(xùn)。正如齊憲標(biāo)說(shuō)的那樣:「在我們重新探索這條路的時(shí)候,這些經(jīng)驗(yàn)其實(shí)可以讓我們思考過(guò)去走這條路的時(shí)候可能哪個(gè)地方?jīng)]走好。」關(guān)于這種「重新探索」的動(dòng)機(jī),齊憲標(biāo)分享了幾個(gè)觀(guān)點(diǎn)。第一個(gè)是關(guān)于 Scaling Law 的。正如前面所提到的,自回歸方法的可擴(kuò)展性已經(jīng)在文本領(lǐng)域得到了驗(yàn)證,最大的文本模型已經(jīng)做到了萬(wàn)億參數(shù)。而在圖像領(lǐng)域,這種 Scaling Law 才剛剛顯現(xiàn),未來(lái)還存在巨大的探索空間。第二個(gè)是關(guān)于多模態(tài)理解和生成的統(tǒng)一。在當(dāng)前「scaling law 撞墻」的相關(guān)討論中,多模態(tài)其實(shí)是一個(gè)被寄予厚望的方向。但是,這個(gè)領(lǐng)域目前面臨一個(gè)嚴(yán)峻的挑戰(zhàn),即多模態(tài)的理解和生成是分開(kāi)進(jìn)行的,這就造成理解模型的理解能力強(qiáng)而生成能力弱,生成模型則相反。統(tǒng)一這兩類(lèi)任務(wù),可以促進(jìn)模型學(xué)到更通用的語(yǔ)義表征,還能讓模型更好地探索數(shù)據(jù)中的潛在規(guī)律,從而增強(qiáng)模型在跨模態(tài)任務(wù)中的泛化性。而自回歸方法的好處就在于它有一個(gè) token 化的過(guò)程。無(wú)論什么模態(tài),只要經(jīng)過(guò)了 token 化,生成和理解就可以很容易被統(tǒng)一在一個(gè)框架里面。相比之下,基于 Diffusion 的方法就缺乏這種靈活性。除此之外,自回歸方法用于視覺(jué)任務(wù)還有很多好處,比如模型指令遵循能力更強(qiáng),之前在文本模型領(lǐng)域積累的經(jīng)驗(yàn)、資源可以復(fù)用等等。這些原因驅(qū)使齊憲標(biāo)和他的同事跳出 Diffusion 這條「主路」,走回了自回歸這條已經(jīng)相對(duì)冷門(mén)的路線(xiàn)。在圖像上 Scaling 有效以及生成和判別的統(tǒng)一要理解 BiGR 和 ELM 的意義,我們得從離散化的圖像和文本的 token 分布談起。齊憲標(biāo)表示:「我們得把一個(gè)圖像塊表示成一個(gè)單詞。如果只是單純的硬編碼,我們是做不到的,因?yàn)樗目臻g太大了。所以,我們首先就是想辦法來(lái)表示圖像。這也就是所謂的 token 化。」 圖像的 token 化通常需要一個(gè)編碼器 ENC、一個(gè)量化算法 QUANT 和一個(gè)解碼器 DEC。目前,主流的圖像 token 化方案有兩種:VQGAN 和 BAE;它們的主要區(qū)別是離散化隱向量的方式 。經(jīng)過(guò) token 化處理之后,圖像也就變成了類(lèi)似文本的 token 序列。如此一來(lái),理論上看,自回歸(AR)模型和掩碼式語(yǔ)言模型(MLM)等用于建模文本的方法也就可以用于處理圖像了。即便如此,經(jīng)過(guò)離散和 token 化處理的圖像序列與文本序列之間依然存在固有的差異。下表給出了 ImageNet、OpenWebText 和 Shakespeare(后兩個(gè)是文本數(shù)據(jù)集)的 token 分布的 KL 距離。
圖像的 token 化通常需要一個(gè)編碼器 ENC、一個(gè)量化算法 QUANT 和一個(gè)解碼器 DEC。目前,主流的圖像 token 化方案有兩種:VQGAN 和 BAE;它們的主要區(qū)別是離散化隱向量的方式 。經(jīng)過(guò) token 化處理之后,圖像也就變成了類(lèi)似文本的 token 序列。如此一來(lái),理論上看,自回歸(AR)模型和掩碼式語(yǔ)言模型(MLM)等用于建模文本的方法也就可以用于處理圖像了。即便如此,經(jīng)過(guò)離散和 token 化處理的圖像序列與文本序列之間依然存在固有的差異。下表給出了 ImageNet、OpenWebText 和 Shakespeare(后兩個(gè)是文本數(shù)據(jù)集)的 token 分布的 KL 距離。 基于此,可以得到兩點(diǎn)觀(guān)察:圖像數(shù)據(jù)缺乏語(yǔ)言數(shù)據(jù)常有的那種內(nèi)在結(jié)構(gòu)和序列順序。這種圖像 token 分布的隨機(jī)性表明圖像生成并不依賴(lài)嚴(yán)格的序列模式。接近均勻的 token 分布表明生成任務(wù)對(duì)錯(cuò)誤的容忍度更高。由于所有 token 的概率幾乎相等,因此該模型可以容忍不太精確的 token 預(yù)測(cè),同時(shí)還不會(huì)顯著影響輸出的質(zhì)量。基于這些觀(guān)察和進(jìn)一步的實(shí)驗(yàn),云天勵(lì)飛得到了一個(gè)結(jié)論:在圖像生成方面,自回歸(AR)方法并不比掩碼式語(yǔ)言模型(MLM)差,甚至可能還更好一點(diǎn)。雖然在語(yǔ)言領(lǐng)域,AR 優(yōu)于 MLM 已經(jīng)得到了許多研究成果的驗(yàn)證(實(shí)際上當(dāng)今的大多數(shù) LLM 都是 AR 范式),但在圖像領(lǐng)域,這算是一個(gè)有些讓人意外的結(jié)果,畢竟掩碼機(jī)制似乎和圖像任務(wù)有著天然的親和力。在此基礎(chǔ)上,云天勵(lì)飛團(tuán)隊(duì)更進(jìn)一步,初步發(fā)現(xiàn)了 AR 模型在圖像生成任務(wù)上的 Scaling Law。越大越強(qiáng),AR 或在圖像生成上再次成功Scaling Law 的概念其實(shí)并不復(fù)雜,簡(jiǎn)單總結(jié)起來(lái)就是模型越大越好,數(shù)據(jù)越多越好,算力越強(qiáng)越好。研究 Scaling Law 之所以重要,是因?yàn)檫@能為后續(xù)的研究探索指引方向。在此之前,雖然已經(jīng)有不少研究團(tuán)隊(duì)嘗試過(guò)使用 Transformer 來(lái)生成圖像,但還少有人嚴(yán)肅地探索過(guò)自回歸 Transformer 在圖像生成任務(wù)上的 Scaling Law。
基于此,可以得到兩點(diǎn)觀(guān)察:圖像數(shù)據(jù)缺乏語(yǔ)言數(shù)據(jù)常有的那種內(nèi)在結(jié)構(gòu)和序列順序。這種圖像 token 分布的隨機(jī)性表明圖像生成并不依賴(lài)嚴(yán)格的序列模式。接近均勻的 token 分布表明生成任務(wù)對(duì)錯(cuò)誤的容忍度更高。由于所有 token 的概率幾乎相等,因此該模型可以容忍不太精確的 token 預(yù)測(cè),同時(shí)還不會(huì)顯著影響輸出的質(zhì)量。基于這些觀(guān)察和進(jìn)一步的實(shí)驗(yàn),云天勵(lì)飛得到了一個(gè)結(jié)論:在圖像生成方面,自回歸(AR)方法并不比掩碼式語(yǔ)言模型(MLM)差,甚至可能還更好一點(diǎn)。雖然在語(yǔ)言領(lǐng)域,AR 優(yōu)于 MLM 已經(jīng)得到了許多研究成果的驗(yàn)證(實(shí)際上當(dāng)今的大多數(shù) LLM 都是 AR 范式),但在圖像領(lǐng)域,這算是一個(gè)有些讓人意外的結(jié)果,畢竟掩碼機(jī)制似乎和圖像任務(wù)有著天然的親和力。在此基礎(chǔ)上,云天勵(lì)飛團(tuán)隊(duì)更進(jìn)一步,初步發(fā)現(xiàn)了 AR 模型在圖像生成任務(wù)上的 Scaling Law。越大越強(qiáng),AR 或在圖像生成上再次成功Scaling Law 的概念其實(shí)并不復(fù)雜,簡(jiǎn)單總結(jié)起來(lái)就是模型越大越好,數(shù)據(jù)越多越好,算力越強(qiáng)越好。研究 Scaling Law 之所以重要,是因?yàn)檫@能為后續(xù)的研究探索指引方向。在此之前,雖然已經(jīng)有不少研究團(tuán)隊(duì)嘗試過(guò)使用 Transformer 來(lái)生成圖像,但還少有人嚴(yán)肅地探索過(guò)自回歸 Transformer 在圖像生成任務(wù)上的 Scaling Law。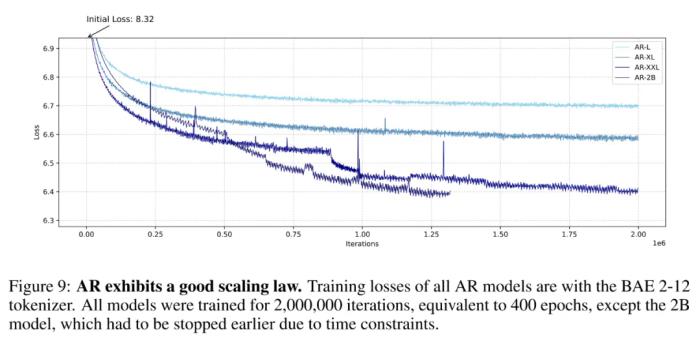 自回歸模型的 Scaling Law,其中 2B 模型由于時(shí)間限制并未完成 200 萬(wàn)次迭代,但其趨勢(shì)依然很明顯云天勵(lì)飛的這項(xiàng)研究無(wú)疑是一支強(qiáng)心劑。具體來(lái)說(shuō),他們發(fā)現(xiàn),隨著模型規(guī)模增大,AR 模型在圖像生成任務(wù)上的訓(xùn)練損失越低、生成性能越好、也能更好地捕獲圖像中的全局信息。他們基于這些觀(guān)察構(gòu)建了一個(gè)可生成圖像的闡述式語(yǔ)言模型(ELM/elucidate language model),并在 ImageNet 256×256 基準(zhǔn)上實(shí)現(xiàn)了 SOTA。
自回歸模型的 Scaling Law,其中 2B 模型由于時(shí)間限制并未完成 200 萬(wàn)次迭代,但其趨勢(shì)依然很明顯云天勵(lì)飛的這項(xiàng)研究無(wú)疑是一支強(qiáng)心劑。具體來(lái)說(shuō),他們發(fā)現(xiàn),隨著模型規(guī)模增大,AR 模型在圖像生成任務(wù)上的訓(xùn)練損失越低、生成性能越好、也能更好地捕獲圖像中的全局信息。他們基于這些觀(guān)察構(gòu)建了一個(gè)可生成圖像的闡述式語(yǔ)言模型(ELM/elucidate language model),并在 ImageNet 256×256 基準(zhǔn)上實(shí)現(xiàn)了 SOTA。 ELM-2B 生成的一些不同類(lèi)別的圖像至于注意力模式,不同大小的模型的差別倒是不大:L 大小的模型主要關(guān)注局部信息,難以捕獲長(zhǎng)程信息。相較之下,更大的 XL 和 XXL 模型的某些層表現(xiàn)出了更長(zhǎng)程的注意力,這說(shuō)明它們也能學(xué)習(xí)全局特征。為了進(jìn)一步確認(rèn) AR 模型確實(shí)能理解圖像任務(wù),該團(tuán)隊(duì)對(duì)不同 AR 模型的注意力圖(attention map)進(jìn)行了可視化,結(jié)果發(fā)現(xiàn)其注意力機(jī)制確實(shí)會(huì)關(guān)注圖像的某些局部區(qū)域,這說(shuō)明自回歸 Transformer 模型確實(shí)可以有效學(xué)習(xí)局部模式對(duì)于圖像生成的重要性。這一結(jié)果又進(jìn)一步凸顯了自回歸 Transformer 在不同領(lǐng)域的強(qiáng)大性能。
ELM-2B 生成的一些不同類(lèi)別的圖像至于注意力模式,不同大小的模型的差別倒是不大:L 大小的模型主要關(guān)注局部信息,難以捕獲長(zhǎng)程信息。相較之下,更大的 XL 和 XXL 模型的某些層表現(xiàn)出了更長(zhǎng)程的注意力,這說(shuō)明它們也能學(xué)習(xí)全局特征。為了進(jìn)一步確認(rèn) AR 模型確實(shí)能理解圖像任務(wù),該團(tuán)隊(duì)對(duì)不同 AR 模型的注意力圖(attention map)進(jìn)行了可視化,結(jié)果發(fā)現(xiàn)其注意力機(jī)制確實(shí)會(huì)關(guān)注圖像的某些局部區(qū)域,這說(shuō)明自回歸 Transformer 模型確實(shí)可以有效學(xué)習(xí)局部模式對(duì)于圖像生成的重要性。這一結(jié)果又進(jìn)一步凸顯了自回歸 Transformer 在不同領(lǐng)域的強(qiáng)大性能。 AR 模型的注意力圖,可以明顯看到其中對(duì)局部模式的關(guān)注掩碼式 AR:判別與生成任務(wù)的創(chuàng)新性統(tǒng)一云天勵(lì)飛在另一項(xiàng)研究中更深度地探索了 AR 模型在圖像領(lǐng)域的可能性。這一次,AR 模型不僅被用來(lái)執(zhí)行圖像生成任務(wù),還在圖像判別任務(wù)上大展拳腳。
AR 模型的注意力圖,可以明顯看到其中對(duì)局部模式的關(guān)注掩碼式 AR:判別與生成任務(wù)的創(chuàng)新性統(tǒng)一云天勵(lì)飛在另一項(xiàng)研究中更深度地探索了 AR 模型在圖像領(lǐng)域的可能性。這一次,AR 模型不僅被用來(lái)執(zhí)行圖像生成任務(wù),還在圖像判別任務(wù)上大展拳腳。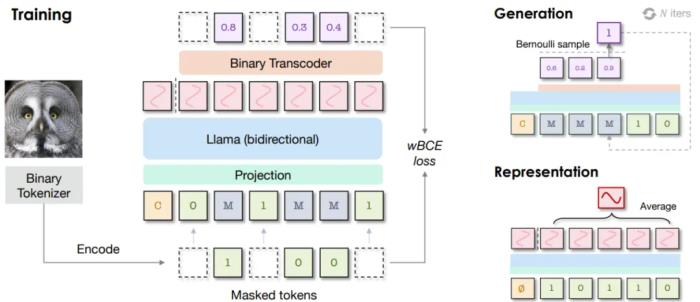 BiGR 框架的簡(jiǎn)化示意圖為此,他們構(gòu)建了一個(gè)名為 BiGR 的新框架。該框架包含 3 個(gè)主要組件:一個(gè)二元 token 化器,其作用是將像素圖像轉(zhuǎn)換成二元隱碼構(gòu)成的序列;一個(gè)僅解碼器 Transformer,并配備了完整的雙向注意力;一個(gè)二元轉(zhuǎn)碼器(binary transcoder),作用是將連續(xù)特征轉(zhuǎn)換成伯努利分布的二元編碼。不僅如此,BiGR 的訓(xùn)練完全是重建 token 的生成過(guò)程,無(wú)需依賴(lài)任何判別損失。那 BiGR 是如何將圖像的生成與判別統(tǒng)一在一起的呢?其關(guān)鍵在于掩碼機(jī)制與自回歸模型的深度融合!具體來(lái)說(shuō),他們使用的骨干網(wǎng)絡(luò)是基于 Transformer 的語(yǔ)言模型 Llama。由于圖像和文本 token 的不同性質(zhì),他們沒(méi)有使用語(yǔ)言模型常用的因果注意力,而是使用了雙向注意力。模型的預(yù)測(cè)目標(biāo)也不再是下一 token,而是被遮掩的 token。在輸入空間,他們的做法也不再是查找有某個(gè) token 索引的嵌入向量,而是使用一個(gè)簡(jiǎn)單的線(xiàn)性層來(lái)將二元編碼投射到嵌入空間。在訓(xùn)練過(guò)程中,會(huì)使用一個(gè)可學(xué)習(xí)的掩碼 token 遮蔽掉一部分圖像 token。然后僅計(jì)算被遮蔽位置的損失,其中模型的預(yù)測(cè)目標(biāo)是被遮掩的 token 的值。之后,再使用二元轉(zhuǎn)碼器,通過(guò)一個(gè)伯努利擴(kuò)散過(guò)程,將模型的輸出轉(zhuǎn)換成二元編碼。而在訓(xùn)練時(shí),語(yǔ)言模型和擴(kuò)散網(wǎng)絡(luò)是聯(lián)合優(yōu)化的。訓(xùn)練完成后,模型本身就會(huì)具備強(qiáng)大的視覺(jué)表征能力:對(duì)于輸入的圖像,可以不帶任何掩碼地提供給模型,并附加一個(gè)無(wú)條件 token。然后,在連續(xù)值的特征上執(zhí)行平均池化,推斷給定圖像的全局表征。他們得到了一個(gè)有趣的觀(guān)察:最具判別性的表征還不是來(lái)自最后一層,而是 Transformer 模塊內(nèi)的中間層!因此,他們便將這些中間特征用作了最終的圖像表征。對(duì)于圖像生成任務(wù),他們?cè)O(shè)計(jì)了一種采樣策略,使模型可以根據(jù)完全掩蔽的序列迭代地預(yù)測(cè) token。不同于訓(xùn)練階段(每一步的掩碼位置都是隨機(jī)選取的),在采樣階段,會(huì)按照一個(gè)預(yù)定義的標(biāo)準(zhǔn)按順序去除 token 的掩碼。最終得到的模型可說(shuō)是圖像生成能力與判別能力俱佳,算是首個(gè)做到這一點(diǎn)的條件生成模型,并且同時(shí)還具備統(tǒng)一、高效、靈活、可擴(kuò)展四大優(yōu)勢(shì)。
BiGR 框架的簡(jiǎn)化示意圖為此,他們構(gòu)建了一個(gè)名為 BiGR 的新框架。該框架包含 3 個(gè)主要組件:一個(gè)二元 token 化器,其作用是將像素圖像轉(zhuǎn)換成二元隱碼構(gòu)成的序列;一個(gè)僅解碼器 Transformer,并配備了完整的雙向注意力;一個(gè)二元轉(zhuǎn)碼器(binary transcoder),作用是將連續(xù)特征轉(zhuǎn)換成伯努利分布的二元編碼。不僅如此,BiGR 的訓(xùn)練完全是重建 token 的生成過(guò)程,無(wú)需依賴(lài)任何判別損失。那 BiGR 是如何將圖像的生成與判別統(tǒng)一在一起的呢?其關(guān)鍵在于掩碼機(jī)制與自回歸模型的深度融合!具體來(lái)說(shuō),他們使用的骨干網(wǎng)絡(luò)是基于 Transformer 的語(yǔ)言模型 Llama。由于圖像和文本 token 的不同性質(zhì),他們沒(méi)有使用語(yǔ)言模型常用的因果注意力,而是使用了雙向注意力。模型的預(yù)測(cè)目標(biāo)也不再是下一 token,而是被遮掩的 token。在輸入空間,他們的做法也不再是查找有某個(gè) token 索引的嵌入向量,而是使用一個(gè)簡(jiǎn)單的線(xiàn)性層來(lái)將二元編碼投射到嵌入空間。在訓(xùn)練過(guò)程中,會(huì)使用一個(gè)可學(xué)習(xí)的掩碼 token 遮蔽掉一部分圖像 token。然后僅計(jì)算被遮蔽位置的損失,其中模型的預(yù)測(cè)目標(biāo)是被遮掩的 token 的值。之后,再使用二元轉(zhuǎn)碼器,通過(guò)一個(gè)伯努利擴(kuò)散過(guò)程,將模型的輸出轉(zhuǎn)換成二元編碼。而在訓(xùn)練時(shí),語(yǔ)言模型和擴(kuò)散網(wǎng)絡(luò)是聯(lián)合優(yōu)化的。訓(xùn)練完成后,模型本身就會(huì)具備強(qiáng)大的視覺(jué)表征能力:對(duì)于輸入的圖像,可以不帶任何掩碼地提供給模型,并附加一個(gè)無(wú)條件 token。然后,在連續(xù)值的特征上執(zhí)行平均池化,推斷給定圖像的全局表征。他們得到了一個(gè)有趣的觀(guān)察:最具判別性的表征還不是來(lái)自最后一層,而是 Transformer 模塊內(nèi)的中間層!因此,他們便將這些中間特征用作了最終的圖像表征。對(duì)于圖像生成任務(wù),他們?cè)O(shè)計(jì)了一種采樣策略,使模型可以根據(jù)完全掩蔽的序列迭代地預(yù)測(cè) token。不同于訓(xùn)練階段(每一步的掩碼位置都是隨機(jī)選取的),在采樣階段,會(huì)按照一個(gè)預(yù)定義的標(biāo)準(zhǔn)按順序去除 token 的掩碼。最終得到的模型可說(shuō)是圖像生成能力與判別能力俱佳,算是首個(gè)做到這一點(diǎn)的條件生成模型,并且同時(shí)還具備統(tǒng)一、高效、靈活、可擴(kuò)展四大優(yōu)勢(shì)。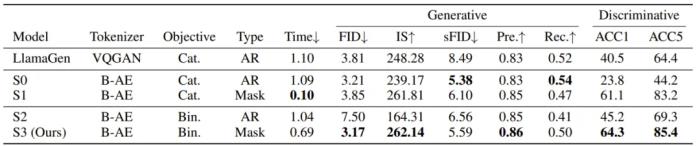 從上表的結(jié)果中我們可以得出以下結(jié)論:通過(guò)比較 LlamaGen 和 S0,可知相比于使用 VQGAN,使用二元自動(dòng)編碼器可以帶來(lái)更好的生成性能,但判別性能會(huì)下降一些。對(duì)于生成任務(wù),AR 建模更適合分類(lèi)損失,而掩碼建模更適合二元損失。對(duì)于判別任務(wù),不管哪種損失,掩碼建模都大幅優(yōu)于 AR 建模,而二元損失能進(jìn)一步提升性能。與 AR 建模相比,掩碼建模由于采樣迭代次數(shù)較少,因此推理速度明顯更快,而二元目標(biāo)的擴(kuò)散過(guò)程需要更多時(shí)間。這種生成與判別的統(tǒng)一能帶來(lái)什么好處呢?齊憲標(biāo)舉了兩個(gè)例子,如果我們想讓模型生成一張「飛翔的熊貓」圖,那么這種自回歸 Transformer 方法可以直接完成從語(yǔ)言理解到圖像生成的全過(guò)程,而無(wú)需調(diào)用 Stable Diffusion 等外部接口。另外,它也能幫助我們理解并進(jìn)一步加工圖像,比如可以在多張圖片中找到我們想要的文本信息并將其抹除。
從上表的結(jié)果中我們可以得出以下結(jié)論:通過(guò)比較 LlamaGen 和 S0,可知相比于使用 VQGAN,使用二元自動(dòng)編碼器可以帶來(lái)更好的生成性能,但判別性能會(huì)下降一些。對(duì)于生成任務(wù),AR 建模更適合分類(lèi)損失,而掩碼建模更適合二元損失。對(duì)于判別任務(wù),不管哪種損失,掩碼建模都大幅優(yōu)于 AR 建模,而二元損失能進(jìn)一步提升性能。與 AR 建模相比,掩碼建模由于采樣迭代次數(shù)較少,因此推理速度明顯更快,而二元目標(biāo)的擴(kuò)散過(guò)程需要更多時(shí)間。這種生成與判別的統(tǒng)一能帶來(lái)什么好處呢?齊憲標(biāo)舉了兩個(gè)例子,如果我們想讓模型生成一張「飛翔的熊貓」圖,那么這種自回歸 Transformer 方法可以直接完成從語(yǔ)言理解到圖像生成的全過(guò)程,而無(wú)需調(diào)用 Stable Diffusion 等外部接口。另外,它也能幫助我們理解并進(jìn)一步加工圖像,比如可以在多張圖片中找到我們想要的文本信息并將其抹除。 BiGR 的一些生成結(jié)果而通過(guò)實(shí)驗(yàn)不同大小的模型,我們同樣看見(jiàn)了 Scaling Law 存在的蹤跡。
BiGR 的一些生成結(jié)果而通過(guò)實(shí)驗(yàn)不同大小的模型,我們同樣看見(jiàn)了 Scaling Law 存在的蹤跡。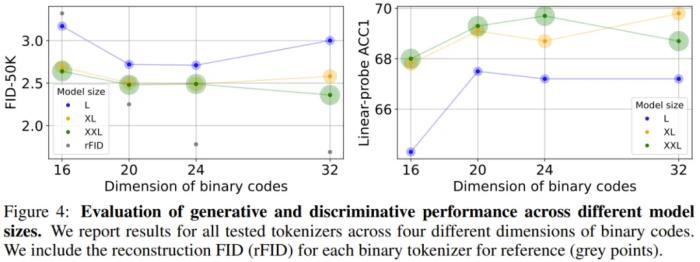 雖然云天勵(lì)飛的論文中沒(méi)有明說(shuō),但 Transformer 在這些不同視覺(jué)任務(wù)的成功或許意味著,在眾說(shuō)紛紜、似乎即將到來(lái)的 AGI 中,自回歸 Transformer 或許至少有一席之地。當(dāng)然,自回歸范式在圖像領(lǐng)域的成功也并非對(duì) Diffusion 的否定,正如齊憲標(biāo)說(shuō)的那樣:「基于自回歸的方法的一個(gè)特別大的特點(diǎn)是它的指令服從能力非常強(qiáng),而基于 Diffusion 的方法的生成質(zhì)量可能更高,細(xì)節(jié)會(huì)更豐富一些,但是它對(duì)于指令的控制能力有的時(shí)候會(huì)偏弱一些。」另外,也應(yīng)當(dāng)指出,基于時(shí)間和成本的考量,這兩項(xiàng)研究更側(cè)重于對(duì)前沿技術(shù)和可能性的探索,想要開(kāi)發(fā)基于 Transformer 的圖像生成應(yīng)用,還有待進(jìn)一步的工程開(kāi)發(fā)。而相關(guān)的 Scaling Law 也有待進(jìn)一步的探索完善,比如,齊憲標(biāo)指出,基于自回歸方法和基于 Diffusion 方法的 Scaling Law 之間的差異就是一個(gè)非常有價(jià)值的研究課題。「我更想知道 transformer 為什么會(huì) work」將自回歸模型應(yīng)用于視覺(jué)生成并不是一條擁擠的賽道,因?yàn)楸娝苤胍芡ㄟ@條路線(xiàn)需要克服很多難點(diǎn),比如生成速度慢、長(zhǎng)程依賴(lài)難建模、高分辨率擴(kuò)展性差、生成質(zhì)量受限等。但出于對(duì) Scaling Law 探索的渴望,云天勵(lì)飛的研究團(tuán)隊(duì)依然選擇走出了這一步。這可能也是非常有前瞻性的一步。這種前瞻性一方面與公司的人才密度(研發(fā)人員占公司總?cè)藬?shù)比例高達(dá)64.08%)密不可分,另一方面也在于公司給予人才的探索空間和算力支持(千億參數(shù)模型訓(xùn)練能力)。齊憲標(biāo)提到,這幾點(diǎn)其實(shí)也是他當(dāng)初選擇云天勵(lì)飛的關(guān)鍵原因。此外,齊憲標(biāo)還談到了自己頗為敬佩的云天勵(lì)飛首席科學(xué)家、曾在微軟工作 17 年的算法大牛肖嶸,稱(chēng)肖嶸是一個(gè)對(duì)公司整體戰(zhàn)略把握非常清晰,同時(shí)又喜歡追問(wèn)技術(shù)細(xì)節(jié)的人,比如他會(huì)讓大家把學(xué)習(xí)曲線(xiàn)拉出來(lái),看看 loss 為什么會(huì)飛掉,學(xué)習(xí)率設(shè)置對(duì)不對(duì),數(shù)據(jù)有沒(méi)有清洗干凈。在這樣的團(tuán)隊(duì)氛圍中,云天勵(lì)飛近年來(lái)在多個(gè)方向取得了一些研究成果,其中包括多項(xiàng)對(duì)大模型加速的工作這些工作探索了大模型端側(cè)加速的方法,能夠大大提升大模型端側(cè)部署推理速度。考慮到云天勵(lì)飛本身就有自有芯片,所以可為大模型的端側(cè)落地提供「軟硬一體的解決方案」。同時(shí),云天勵(lì)飛科研團(tuán)隊(duì)還有多項(xiàng)研究成果投稿到 ICLR 2025 會(huì)議。其中有兩項(xiàng)是關(guān)于Transformer 基礎(chǔ)理論的研究。一項(xiàng)探索了大模型訓(xùn)練崩潰的根本原因,他們歸結(jié)于
雖然云天勵(lì)飛的論文中沒(méi)有明說(shuō),但 Transformer 在這些不同視覺(jué)任務(wù)的成功或許意味著,在眾說(shuō)紛紜、似乎即將到來(lái)的 AGI 中,自回歸 Transformer 或許至少有一席之地。當(dāng)然,自回歸范式在圖像領(lǐng)域的成功也并非對(duì) Diffusion 的否定,正如齊憲標(biāo)說(shuō)的那樣:「基于自回歸的方法的一個(gè)特別大的特點(diǎn)是它的指令服從能力非常強(qiáng),而基于 Diffusion 的方法的生成質(zhì)量可能更高,細(xì)節(jié)會(huì)更豐富一些,但是它對(duì)于指令的控制能力有的時(shí)候會(huì)偏弱一些。」另外,也應(yīng)當(dāng)指出,基于時(shí)間和成本的考量,這兩項(xiàng)研究更側(cè)重于對(duì)前沿技術(shù)和可能性的探索,想要開(kāi)發(fā)基于 Transformer 的圖像生成應(yīng)用,還有待進(jìn)一步的工程開(kāi)發(fā)。而相關(guān)的 Scaling Law 也有待進(jìn)一步的探索完善,比如,齊憲標(biāo)指出,基于自回歸方法和基于 Diffusion 方法的 Scaling Law 之間的差異就是一個(gè)非常有價(jià)值的研究課題。「我更想知道 transformer 為什么會(huì) work」將自回歸模型應(yīng)用于視覺(jué)生成并不是一條擁擠的賽道,因?yàn)楸娝苤胍芡ㄟ@條路線(xiàn)需要克服很多難點(diǎn),比如生成速度慢、長(zhǎng)程依賴(lài)難建模、高分辨率擴(kuò)展性差、生成質(zhì)量受限等。但出于對(duì) Scaling Law 探索的渴望,云天勵(lì)飛的研究團(tuán)隊(duì)依然選擇走出了這一步。這可能也是非常有前瞻性的一步。這種前瞻性一方面與公司的人才密度(研發(fā)人員占公司總?cè)藬?shù)比例高達(dá)64.08%)密不可分,另一方面也在于公司給予人才的探索空間和算力支持(千億參數(shù)模型訓(xùn)練能力)。齊憲標(biāo)提到,這幾點(diǎn)其實(shí)也是他當(dāng)初選擇云天勵(lì)飛的關(guān)鍵原因。此外,齊憲標(biāo)還談到了自己頗為敬佩的云天勵(lì)飛首席科學(xué)家、曾在微軟工作 17 年的算法大牛肖嶸,稱(chēng)肖嶸是一個(gè)對(duì)公司整體戰(zhàn)略把握非常清晰,同時(shí)又喜歡追問(wèn)技術(shù)細(xì)節(jié)的人,比如他會(huì)讓大家把學(xué)習(xí)曲線(xiàn)拉出來(lái),看看 loss 為什么會(huì)飛掉,學(xué)習(xí)率設(shè)置對(duì)不對(duì),數(shù)據(jù)有沒(méi)有清洗干凈。在這樣的團(tuán)隊(duì)氛圍中,云天勵(lì)飛近年來(lái)在多個(gè)方向取得了一些研究成果,其中包括多項(xiàng)對(duì)大模型加速的工作這些工作探索了大模型端側(cè)加速的方法,能夠大大提升大模型端側(cè)部署推理速度。考慮到云天勵(lì)飛本身就有自有芯片,所以可為大模型的端側(cè)落地提供「軟硬一體的解決方案」。同時(shí),云天勵(lì)飛科研團(tuán)隊(duì)還有多項(xiàng)研究成果投稿到 ICLR 2025 會(huì)議。其中有兩項(xiàng)是關(guān)于Transformer 基礎(chǔ)理論的研究。一項(xiàng)探索了大模型訓(xùn)練崩潰的根本原因,他們歸結(jié)于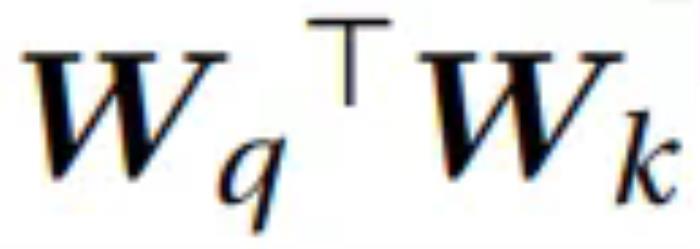 的譜能量集中。另外一項(xiàng)則是設(shè)計(jì)了高效且穩(wěn)定的 Transformer 模塊。「谷歌在訓(xùn)練 PaLM 模型的時(shí)候,訓(xùn)練的 loss 飛掉了 20 多次。Meta 訓(xùn)練 Llama 3 的時(shí)候因?yàn)楦鞣N問(wèn)題崩潰了四百多次。這其中很多問(wèn)題可能都跟我們對(duì) Transformer 的底層理解有關(guān)。也就是說(shuō),我們對(duì)于 Transformer 的應(yīng)用已經(jīng)做了很多,但對(duì) Transformer 理論的理解相對(duì)來(lái)說(shuō)還不夠透徹。我更想知道 Transformer 為什么會(huì) work,為什么會(huì)出現(xiàn)問(wèn)題。」齊憲標(biāo)在談及這個(gè)方向的研究動(dòng)機(jī)時(shí)說(shuō)道。結(jié)語(yǔ)這幾天,關(guān)于 Scaling Law 是否撞墻的討論還在繼續(xù),齊憲標(biāo)顯然并不認(rèn)可 Scaling Law 已經(jīng)撞墻的說(shuō)法 —— 不管是圖像還是文本,Scaling 都還能帶來(lái)明顯的提升。不過(guò),他也指出,對(duì)于 Scaling Law 的探索注定是一項(xiàng)長(zhǎng)期工作,需要從多個(gè)方向找突破口,云天勵(lì)飛也將持續(xù)探索。據(jù)了解,今年云天勵(lì)飛一直在強(qiáng)調(diào)「邊緣 AI」戰(zhàn)略。為此,他們選擇了從軟硬件兩個(gè)方向同時(shí)前進(jìn),即 AI 芯片和大模型。在此基礎(chǔ)上,他們進(jìn)入了「算法芯片化」這一賽道。云天勵(lì)飛表示,他們已經(jīng)打造出了一些面向消費(fèi)者、企業(yè)和城市的大模型相關(guān)產(chǎn)品和解決方案。據(jù)了解,今年底云天勵(lì)飛還會(huì)推出兩款基于大模型打造的智能硬件產(chǎn)品。2024 年被許多人稱(chēng)為「人工智能應(yīng)用的真正元年」。AI 開(kāi)始走出開(kāi)發(fā)者和愛(ài)好者的圈子,向普羅大眾更廣泛地滲透。通過(guò)在底層技術(shù)創(chuàng)新和應(yīng)用開(kāi)發(fā)兩方面持續(xù)發(fā)力,云天勵(lì)飛能否在已然卷成紅海的 AI 行業(yè)博取一塊蛋糕?還有待進(jìn)一步觀(guān)察。不過(guò),考慮云天勵(lì)飛在 AI 的軟件和硬件兩方面都已經(jīng)有了相當(dāng)厚實(shí)的技術(shù)沉淀,做到這一點(diǎn)應(yīng)該并不難。
的譜能量集中。另外一項(xiàng)則是設(shè)計(jì)了高效且穩(wěn)定的 Transformer 模塊。「谷歌在訓(xùn)練 PaLM 模型的時(shí)候,訓(xùn)練的 loss 飛掉了 20 多次。Meta 訓(xùn)練 Llama 3 的時(shí)候因?yàn)楦鞣N問(wèn)題崩潰了四百多次。這其中很多問(wèn)題可能都跟我們對(duì) Transformer 的底層理解有關(guān)。也就是說(shuō),我們對(duì)于 Transformer 的應(yīng)用已經(jīng)做了很多,但對(duì) Transformer 理論的理解相對(duì)來(lái)說(shuō)還不夠透徹。我更想知道 Transformer 為什么會(huì) work,為什么會(huì)出現(xiàn)問(wèn)題。」齊憲標(biāo)在談及這個(gè)方向的研究動(dòng)機(jī)時(shí)說(shuō)道。結(jié)語(yǔ)這幾天,關(guān)于 Scaling Law 是否撞墻的討論還在繼續(xù),齊憲標(biāo)顯然并不認(rèn)可 Scaling Law 已經(jīng)撞墻的說(shuō)法 —— 不管是圖像還是文本,Scaling 都還能帶來(lái)明顯的提升。不過(guò),他也指出,對(duì)于 Scaling Law 的探索注定是一項(xiàng)長(zhǎng)期工作,需要從多個(gè)方向找突破口,云天勵(lì)飛也將持續(xù)探索。據(jù)了解,今年云天勵(lì)飛一直在強(qiáng)調(diào)「邊緣 AI」戰(zhàn)略。為此,他們選擇了從軟硬件兩個(gè)方向同時(shí)前進(jìn),即 AI 芯片和大模型。在此基礎(chǔ)上,他們進(jìn)入了「算法芯片化」這一賽道。云天勵(lì)飛表示,他們已經(jīng)打造出了一些面向消費(fèi)者、企業(yè)和城市的大模型相關(guān)產(chǎn)品和解決方案。據(jù)了解,今年底云天勵(lì)飛還會(huì)推出兩款基于大模型打造的智能硬件產(chǎn)品。2024 年被許多人稱(chēng)為「人工智能應(yīng)用的真正元年」。AI 開(kāi)始走出開(kāi)發(fā)者和愛(ài)好者的圈子,向普羅大眾更廣泛地滲透。通過(guò)在底層技術(shù)創(chuàng)新和應(yīng)用開(kāi)發(fā)兩方面持續(xù)發(fā)力,云天勵(lì)飛能否在已然卷成紅海的 AI 行業(yè)博取一塊蛋糕?還有待進(jìn)一步觀(guān)察。不過(guò),考慮云天勵(lì)飛在 AI 的軟件和硬件兩方面都已經(jīng)有了相當(dāng)厚實(shí)的技術(shù)沉淀,做到這一點(diǎn)應(yīng)該并不難。
「Scaling Law 撞墻了?」這恐怕是 AI 社區(qū)最近討論熱度最高的話(huà)題。
該話(huà)題始于 The Information 的一篇文章。這篇文章透露,OpenAI 下一代旗艦?zāi)P偷馁|(zhì)量提升幅度不及前兩款旗艦?zāi)P椭g的質(zhì)量提升,因?yàn)楦哔|(zhì)量文本和其他數(shù)據(jù)的供應(yīng)量正在減少,原本的 Scaling Law(用更多的數(shù)據(jù)訓(xùn)練更大的模型)可能無(wú)以為繼。
文章發(fā)布后,很多人反駁了這一觀(guān)點(diǎn),認(rèn)為 Scaling Law 還沒(méi)到撞墻的地步,畢竟很多訓(xùn)練大模型的團(tuán)隊(duì)依然能夠看到模型能力的持續(xù)提升。而且,我們現(xiàn)在所說(shuō)的 Scaling Law 更多是指訓(xùn)練階段,而推理階段的 Scaling Law 還未被充分挖掘,借助測(cè)試時(shí)間計(jì)算等方法,大模型的能力還能更上一層樓。
還有人指出,其實(shí),在文本以外的領(lǐng)域,Scaling Law 的蹤跡正在逐漸顯現(xiàn),比如時(shí)間序列預(yù)測(cè)以及圖像、視頻這類(lèi)視覺(jué)領(lǐng)域。下面這張圖來(lái)自投稿給 ICLR 2025 的一篇論文。論文發(fā)現(xiàn),在把類(lèi)似于 GPT 的自回歸模型應(yīng)用于圖像生成時(shí),Scaling Law 同樣可以被觀(guān)察到。具體表現(xiàn)為:隨著模型大小的增加,訓(xùn)練損失會(huì)降低,模型生成性能會(huì)提高,捕捉全局信息的能力也會(huì)增強(qiáng)。論文標(biāo)題:Elucidating the design space of language models for image generation論文鏈接:https://arxiv.org/pdf/2410.16257代碼與模型:https://github.com/Pepper-lll/LMforImageGeneration論文作者之一、云天勵(lì)飛的齊憲標(biāo)博士在接受機(jī)器之心采訪(fǎng)時(shí)表示:「我們不知道圖像中的 Scaling Law 到底有多強(qiáng),比如如果我們把圖像生成模型也擴(kuò)展到 Llama 7B 這個(gè)規(guī)模,是不是 GPT 那樣的自回歸方法也具有非常大的潛力?」抱著這個(gè)想法,他們進(jìn)行了一些初步實(shí)驗(yàn),發(fā)現(xiàn)只訓(xùn)練到一半的時(shí)候,自回歸模型就已經(jīng)在圖像生成任務(wù)上表現(xiàn)出了很強(qiáng)的 Scaling Law。這讓他們對(duì)自回歸方法在視覺(jué)領(lǐng)域的應(yīng)用充滿(mǎn)信心。可見(jiàn),至少在圖像和視頻生成等領(lǐng)域,Scaling Law 依然強(qiáng)勢(shì),離撞墻還遠(yuǎn)。在另一篇論文中,齊憲標(biāo)等人還發(fā)現(xiàn),其實(shí)在應(yīng)用于圖像領(lǐng)域時(shí),傳統(tǒng)的自回歸方法也有改進(jìn)空間。他們把改進(jìn)后的方法稱(chēng)為「BiGR 」,該方法建立在何愷明等人 MAR(masked autoregressive)工作的基礎(chǔ)之上,并在一些方面實(shí)現(xiàn)了改進(jìn),成為了首個(gè)將生成和判別任務(wù)統(tǒng)一在同一框架內(nèi)的條件生成模型。這意味著,BiGR 不僅是一個(gè)好的圖像生成器,同時(shí)還是一個(gè)強(qiáng)大的特征提取器,二者是相互促進(jìn)的關(guān)系。論文標(biāo)題:BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities論文鏈接:https://arxiv.org/pdf/2410.14672代碼與模型:https://github.com/haoosz/BiGR這些工作為研究界繼續(xù)探索自回歸模型在視覺(jué)領(lǐng)域的 Scaling Law 提供了一些啟發(fā)。在這篇文章中,我們將對(duì)這些工作進(jìn)行深入解讀。順帶一提,這兩項(xiàng)研究的代碼和模型都已發(fā)布。自回歸:Diffusion 之外的另一條道路在當(dāng)前的視覺(jué)生成領(lǐng)域,Diffusion 模型是毫無(wú)疑問(wèn)的霸主。這種方法生成的圖像質(zhì)量較高,視頻也越來(lái)越好。但另一方面,以 Transformer 為代表的自回歸模型在文本領(lǐng)域的成功就在眼前,這不禁讓人去想象自回歸模型在視覺(jué)領(lǐng)域的可能性。其實(shí),早在 2018 年,谷歌的一個(gè)團(tuán)隊(duì)(其中大部分是 Transformer 論文作者)就已經(jīng)探索過(guò)用自回歸模型來(lái)生成圖像(參見(jiàn)論文《Image Transformer》)。OpenAI 的初代 DALL?E 模型用的也是基于自回歸的方法。但由于探索初期效果不佳,再加上 Diffusion 模型的強(qiáng)勢(shì)崛起和開(kāi)源,基于自回歸的方法逐漸淡出了大部分研究者的視野。 初代 DALL?E 生成效果云天勵(lì)飛的這些研究更像是一種「重新探索」,而且這次探索有很多可以借鑒的經(jīng)驗(yàn)教訓(xùn)。正如齊憲標(biāo)說(shuō)的那樣:「在我們重新探索這條路的時(shí)候,這些經(jīng)驗(yàn)其實(shí)可以讓我們思考過(guò)去走這條路的時(shí)候可能哪個(gè)地方?jīng)]走好。」關(guān)于這種「重新探索」的動(dòng)機(jī),齊憲標(biāo)分享了幾個(gè)觀(guān)點(diǎn)。第一個(gè)是關(guān)于 Scaling Law 的。正如前面所提到的,自回歸方法的可擴(kuò)展性已經(jīng)在文本領(lǐng)域得到了驗(yàn)證,最大的文本模型已經(jīng)做到了萬(wàn)億參數(shù)。而在圖像領(lǐng)域,這種 Scaling Law 才剛剛顯現(xiàn),未來(lái)還存在巨大的探索空間。第二個(gè)是關(guān)于多模態(tài)理解和生成的統(tǒng)一。在當(dāng)前「scaling law 撞墻」的相關(guān)討論中,多模態(tài)其實(shí)是一個(gè)被寄予厚望的方向。但是,這個(gè)領(lǐng)域目前面臨一個(gè)嚴(yán)峻的挑戰(zhàn),即多模態(tài)的理解和生成是分開(kāi)進(jìn)行的,這就造成理解模型的理解能力強(qiáng)而生成能力弱,生成模型則相反。統(tǒng)一這兩類(lèi)任務(wù),可以促進(jìn)模型學(xué)到更通用的語(yǔ)義表征,還能讓模型更好地探索數(shù)據(jù)中的潛在規(guī)律,從而增強(qiáng)模型在跨模態(tài)任務(wù)中的泛化性。而自回歸方法的好處就在于它有一個(gè) token 化的過(guò)程。無(wú)論什么模態(tài),只要經(jīng)過(guò)了 token 化,生成和理解就可以很容易被統(tǒng)一在一個(gè)框架里面。相比之下,基于 Diffusion 的方法就缺乏這種靈活性。除此之外,自回歸方法用于視覺(jué)任務(wù)還有很多好處,比如模型指令遵循能力更強(qiáng),之前在文本模型領(lǐng)域積累的經(jīng)驗(yàn)、資源可以復(fù)用等等。這些原因驅(qū)使齊憲標(biāo)和他的同事跳出 Diffusion 這條「主路」,走回了自回歸這條已經(jīng)相對(duì)冷門(mén)的路線(xiàn)。在圖像上 Scaling 有效以及生成和判別的統(tǒng)一要理解 BiGR 和 ELM 的意義,我們得從離散化的圖像和文本的 token 分布談起。齊憲標(biāo)表示:「我們得把一個(gè)圖像塊表示成一個(gè)單詞。如果只是單純的硬編碼,我們是做不到的,因?yàn)樗目臻g太大了。所以,我們首先就是想辦法來(lái)表示圖像。這也就是所謂的 token 化。」圖像的 token 化通常需要一個(gè)編碼器 ENC、一個(gè)量化算法 QUANT 和一個(gè)解碼器 DEC。目前,主流的圖像 token 化方案有兩種:VQGAN 和 BAE;它們的主要區(qū)別是離散化隱向量的方式 。經(jīng)過(guò) token 化處理之后,圖像也就變成了類(lèi)似文本的 token 序列。如此一來(lái),理論上看,自回歸(AR)模型和掩碼式語(yǔ)言模型(MLM)等用于建模文本的方法也就可以用于處理圖像了。即便如此,經(jīng)過(guò)離散和 token 化處理的圖像序列與文本序列之間依然存在固有的差異。下表給出了 ImageNet、OpenWebText 和 Shakespeare(后兩個(gè)是文本數(shù)據(jù)集)的 token 分布的 KL 距離。基于此,可以得到兩點(diǎn)觀(guān)察:圖像數(shù)據(jù)缺乏語(yǔ)言數(shù)據(jù)常有的那種內(nèi)在結(jié)構(gòu)和序列順序。這種圖像 token 分布的隨機(jī)性表明圖像生成并不依賴(lài)嚴(yán)格的序列模式。接近均勻的 token 分布表明生成任務(wù)對(duì)錯(cuò)誤的容忍度更高。由于所有 token 的概率幾乎相等,因此該模型可以容忍不太精確的 token 預(yù)測(cè),同時(shí)還不會(huì)顯著影響輸出的質(zhì)量。基于這些觀(guān)察和進(jìn)一步的實(shí)驗(yàn),云天勵(lì)飛得到了一個(gè)結(jié)論:在圖像生成方面,自回歸(AR)方法并不比掩碼式語(yǔ)言模型(MLM)差,甚至可能還更好一點(diǎn)。雖然在語(yǔ)言領(lǐng)域,AR 優(yōu)于 MLM 已經(jīng)得到了許多研究成果的驗(yàn)證(實(shí)際上當(dāng)今的大多數(shù) LLM 都是 AR 范式),但在圖像領(lǐng)域,這算是一個(gè)有些讓人意外的結(jié)果,畢竟掩碼機(jī)制似乎和圖像任務(wù)有著天然的親和力。在此基礎(chǔ)上,云天勵(lì)飛團(tuán)隊(duì)更進(jìn)一步,初步發(fā)現(xiàn)了 AR 模型在圖像生成任務(wù)上的 Scaling Law。越大越強(qiáng),AR 或在圖像生成上再次成功Scaling Law 的概念其實(shí)并不復(fù)雜,簡(jiǎn)單總結(jié)起來(lái)就是模型越大越好,數(shù)據(jù)越多越好,算力越強(qiáng)越好。研究 Scaling Law 之所以重要,是因?yàn)檫@能為后續(xù)的研究探索指引方向。在此之前,雖然已經(jīng)有不少研究團(tuán)隊(duì)嘗試過(guò)使用 Transformer 來(lái)生成圖像,但還少有人嚴(yán)肅地探索過(guò)自回歸 Transformer 在圖像生成任務(wù)上的 Scaling Law。 自回歸模型的 Scaling Law,其中 2B 模型由于時(shí)間限制并未完成 200 萬(wàn)次迭代,但其趨勢(shì)依然很明顯云天勵(lì)飛的這項(xiàng)研究無(wú)疑是一支強(qiáng)心劑。具體來(lái)說(shuō),他們發(fā)現(xiàn),隨著模型規(guī)模增大,AR 模型在圖像生成任務(wù)上的訓(xùn)練損失越低、生成性能越好、也能更好地捕獲圖像中的全局信息。他們基于這些觀(guān)察構(gòu)建了一個(gè)可生成圖像的闡述式語(yǔ)言模型(ELM/elucidate language model),并在 ImageNet 256×256 基準(zhǔn)上實(shí)現(xiàn)了 SOTA。 ELM-2B 生成的一些不同類(lèi)別的圖像至于注意力模式,不同大小的模型的差別倒是不大:L 大小的模型主要關(guān)注局部信息,難以捕獲長(zhǎng)程信息。相較之下,更大的 XL 和 XXL 模型的某些層表現(xiàn)出了更長(zhǎng)程的注意力,這說(shuō)明它們也能學(xué)習(xí)全局特征。為了進(jìn)一步確認(rèn) AR 模型確實(shí)能理解圖像任務(wù),該團(tuán)隊(duì)對(duì)不同 AR 模型的注意力圖(attention map)進(jìn)行了可視化,結(jié)果發(fā)現(xiàn)其注意力機(jī)制確實(shí)會(huì)關(guān)注圖像的某些局部區(qū)域,這說(shuō)明自回歸 Transformer 模型確實(shí)可以有效學(xué)習(xí)局部模式對(duì)于圖像生成的重要性。這一結(jié)果又進(jìn)一步凸顯了自回歸 Transformer 在不同領(lǐng)域的強(qiáng)大性能。 AR 模型的注意力圖,可以明顯看到其中對(duì)局部模式的關(guān)注掩碼式 AR:判別與生成任務(wù)的創(chuàng)新性統(tǒng)一云天勵(lì)飛在另一項(xiàng)研究中更深度地探索了 AR 模型在圖像領(lǐng)域的可能性。這一次,AR 模型不僅被用來(lái)執(zhí)行圖像生成任務(wù),還在圖像判別任務(wù)上大展拳腳。 BiGR 框架的簡(jiǎn)化示意圖為此,他們構(gòu)建了一個(gè)名為 BiGR 的新框架。該框架包含 3 個(gè)主要組件:一個(gè)二元 token 化器,其作用是將像素圖像轉(zhuǎn)換成二元隱碼構(gòu)成的序列;一個(gè)僅解碼器 Transformer,并配備了完整的雙向注意力;一個(gè)二元轉(zhuǎn)碼器(binary transcoder),作用是將連續(xù)特征轉(zhuǎn)換成伯努利分布的二元編碼。不僅如此,BiGR 的訓(xùn)練完全是重建 token 的生成過(guò)程,無(wú)需依賴(lài)任何判別損失。那 BiGR 是如何將圖像的生成與判別統(tǒng)一在一起的呢?其關(guān)鍵在于掩碼機(jī)制與自回歸模型的深度融合!具體來(lái)說(shuō),他們使用的骨干網(wǎng)絡(luò)是基于 Transformer 的語(yǔ)言模型 Llama。由于圖像和文本 token 的不同性質(zhì),他們沒(méi)有使用語(yǔ)言模型常用的因果注意力,而是使用了雙向注意力。模型的預(yù)測(cè)目標(biāo)也不再是下一 token,而是被遮掩的 token。在輸入空間,他們的做法也不再是查找有某個(gè) token 索引的嵌入向量,而是使用一個(gè)簡(jiǎn)單的線(xiàn)性層來(lái)將二元編碼投射到嵌入空間。在訓(xùn)練過(guò)程中,會(huì)使用一個(gè)可學(xué)習(xí)的掩碼 token 遮蔽掉一部分圖像 token。然后僅計(jì)算被遮蔽位置的損失,其中模型的預(yù)測(cè)目標(biāo)是被遮掩的 token 的值。之后,再使用二元轉(zhuǎn)碼器,通過(guò)一個(gè)伯努利擴(kuò)散過(guò)程,將模型的輸出轉(zhuǎn)換成二元編碼。而在訓(xùn)練時(shí),語(yǔ)言模型和擴(kuò)散網(wǎng)絡(luò)是聯(lián)合優(yōu)化的。訓(xùn)練完成后,模型本身就會(huì)具備強(qiáng)大的視覺(jué)表征能力:對(duì)于輸入的圖像,可以不帶任何掩碼地提供給模型,并附加一個(gè)無(wú)條件 token。然后,在連續(xù)值的特征上執(zhí)行平均池化,推斷給定圖像的全局表征。他們得到了一個(gè)有趣的觀(guān)察:最具判別性的表征還不是來(lái)自最后一層,而是 Transformer 模塊內(nèi)的中間層!因此,他們便將這些中間特征用作了最終的圖像表征。對(duì)于圖像生成任務(wù),他們?cè)O(shè)計(jì)了一種采樣策略,使模型可以根據(jù)完全掩蔽的序列迭代地預(yù)測(cè) token。不同于訓(xùn)練階段(每一步的掩碼位置都是隨機(jī)選取的),在采樣階段,會(huì)按照一個(gè)預(yù)定義的標(biāo)準(zhǔn)按順序去除 token 的掩碼。最終得到的模型可說(shuō)是圖像生成能力與判別能力俱佳,算是首個(gè)做到這一點(diǎn)的條件生成模型,并且同時(shí)還具備統(tǒng)一、高效、靈活、可擴(kuò)展四大優(yōu)勢(shì)。從上表的結(jié)果中我們可以得出以下結(jié)論:通過(guò)比較 LlamaGen 和 S0,可知相比于使用 VQGAN,使用二元自動(dòng)編碼器可以帶來(lái)更好的生成性能,但判別性能會(huì)下降一些。對(duì)于生成任務(wù),AR 建模更適合分類(lèi)損失,而掩碼建模更適合二元損失。對(duì)于判別任務(wù),不管哪種損失,掩碼建模都大幅優(yōu)于 AR 建模,而二元損失能進(jìn)一步提升性能。與 AR 建模相比,掩碼建模由于采樣迭代次數(shù)較少,因此推理速度明顯更快,而二元目標(biāo)的擴(kuò)散過(guò)程需要更多時(shí)間。這種生成與判別的統(tǒng)一能帶來(lái)什么好處呢?齊憲標(biāo)舉了兩個(gè)例子,如果我們想讓模型生成一張「飛翔的熊貓」圖,那么這種自回歸 Transformer 方法可以直接完成從語(yǔ)言理解到圖像生成的全過(guò)程,而無(wú)需調(diào)用 Stable Diffusion 等外部接口。另外,它也能幫助我們理解并進(jìn)一步加工圖像,比如可以在多張圖片中找到我們想要的文本信息并將其抹除。 BiGR 的一些生成結(jié)果而通過(guò)實(shí)驗(yàn)不同大小的模型,我們同樣看見(jiàn)了 Scaling Law 存在的蹤跡。雖然云天勵(lì)飛的論文中沒(méi)有明說(shuō),但 Transformer 在這些不同視覺(jué)任務(wù)的成功或許意味著,在眾說(shuō)紛紜、似乎即將到來(lái)的 AGI 中,自回歸 Transformer 或許至少有一席之地。當(dāng)然,自回歸范式在圖像領(lǐng)域的成功也并非對(duì) Diffusion 的否定,正如齊憲標(biāo)說(shuō)的那樣:「基于自回歸的方法的一個(gè)特別大的特點(diǎn)是它的指令服從能力非常強(qiáng),而基于 Diffusion 的方法的生成質(zhì)量可能更高,細(xì)節(jié)會(huì)更豐富一些,但是它對(duì)于指令的控制能力有的時(shí)候會(huì)偏弱一些。」另外,也應(yīng)當(dāng)指出,基于時(shí)間和成本的考量,這兩項(xiàng)研究更側(cè)重于對(duì)前沿技術(shù)和可能性的探索,想要開(kāi)發(fā)基于 Transformer 的圖像生成應(yīng)用,還有待進(jìn)一步的工程開(kāi)發(fā)。而相關(guān)的 Scaling Law 也有待進(jìn)一步的探索完善,比如,齊憲標(biāo)指出,基于自回歸方法和基于 Diffusion 方法的 Scaling Law 之間的差異就是一個(gè)非常有價(jià)值的研究課題。「我更想知道 transformer 為什么會(huì) work」將自回歸模型應(yīng)用于視覺(jué)生成并不是一條擁擠的賽道,因?yàn)楸娝苤胍芡ㄟ@條路線(xiàn)需要克服很多難點(diǎn),比如生成速度慢、長(zhǎng)程依賴(lài)難建模、高分辨率擴(kuò)展性差、生成質(zhì)量受限等。但出于對(duì) Scaling Law 探索的渴望,云天勵(lì)飛的研究團(tuán)隊(duì)依然選擇走出了這一步。這可能也是非常有前瞻性的一步。這種前瞻性一方面與公司的人才密度(研發(fā)人員占公司總?cè)藬?shù)比例高達(dá)64.08%)密不可分,另一方面也在于公司給予人才的探索空間和算力支持(千億參數(shù)模型訓(xùn)練能力)。齊憲標(biāo)提到,這幾點(diǎn)其實(shí)也是他當(dāng)初選擇云天勵(lì)飛的關(guān)鍵原因。此外,齊憲標(biāo)還談到了自己頗為敬佩的云天勵(lì)飛首席科學(xué)家、曾在微軟工作 17 年的算法大牛肖嶸,稱(chēng)肖嶸是一個(gè)對(duì)公司整體戰(zhàn)略把握非常清晰,同時(shí)又喜歡追問(wèn)技術(shù)細(xì)節(jié)的人,比如他會(huì)讓大家把學(xué)習(xí)曲線(xiàn)拉出來(lái),看看 loss 為什么會(huì)飛掉,學(xué)習(xí)率設(shè)置對(duì)不對(duì),數(shù)據(jù)有沒(méi)有清洗干凈。在這樣的團(tuán)隊(duì)氛圍中,云天勵(lì)飛近年來(lái)在多個(gè)方向取得了一些研究成果,其中包括多項(xiàng)對(duì)大模型加速的工作這些工作探索了大模型端側(cè)加速的方法,能夠大大提升大模型端側(cè)部署推理速度。考慮到云天勵(lì)飛本身就有自有芯片,所以可為大模型的端側(cè)落地提供「軟硬一體的解決方案」。同時(shí),云天勵(lì)飛科研團(tuán)隊(duì)還有多項(xiàng)研究成果投稿到 ICLR 2025 會(huì)議。其中有兩項(xiàng)是關(guān)于Transformer 基礎(chǔ)理論的研究。一項(xiàng)探索了大模型訓(xùn)練崩潰的根本原因,他們歸結(jié)于的譜能量集中。另外一項(xiàng)則是設(shè)計(jì)了高效且穩(wěn)定的 Transformer 模塊。「谷歌在訓(xùn)練 PaLM 模型的時(shí)候,訓(xùn)練的 loss 飛掉了 20 多次。Meta 訓(xùn)練 Llama 3 的時(shí)候因?yàn)楦鞣N問(wèn)題崩潰了四百多次。這其中很多問(wèn)題可能都跟我們對(duì) Transformer 的底層理解有關(guān)。也就是說(shuō),我們對(duì)于 Transformer 的應(yīng)用已經(jīng)做了很多,但對(duì) Transformer 理論的理解相對(duì)來(lái)說(shuō)還不夠透徹。我更想知道 Transformer 為什么會(huì) work,為什么會(huì)出現(xiàn)問(wèn)題。」齊憲標(biāo)在談及這個(gè)方向的研究動(dòng)機(jī)時(shí)說(shuō)道。結(jié)語(yǔ)這幾天,關(guān)于 Scaling Law 是否撞墻的討論還在繼續(xù),齊憲標(biāo)顯然并不認(rèn)可 Scaling Law 已經(jīng)撞墻的說(shuō)法 —— 不管是圖像還是文本,Scaling 都還能帶來(lái)明顯的提升。不過(guò),他也指出,對(duì)于 Scaling Law 的探索注定是一項(xiàng)長(zhǎng)期工作,需要從多個(gè)方向找突破口,云天勵(lì)飛也將持續(xù)探索。據(jù)了解,今年云天勵(lì)飛一直在強(qiáng)調(diào)「邊緣 AI」戰(zhàn)略。為此,他們選擇了從軟硬件兩個(gè)方向同時(shí)前進(jìn),即 AI 芯片和大模型。在此基礎(chǔ)上,他們進(jìn)入了「算法芯片化」這一賽道。云天勵(lì)飛表示,他們已經(jīng)打造出了一些面向消費(fèi)者、企業(yè)和城市的大模型相關(guān)產(chǎn)品和解決方案。據(jù)了解,今年底云天勵(lì)飛還會(huì)推出兩款基于大模型打造的智能硬件產(chǎn)品。2024 年被許多人稱(chēng)為「人工智能應(yīng)用的真正元年」。AI 開(kāi)始走出開(kāi)發(fā)者和愛(ài)好者的圈子,向普羅大眾更廣泛地滲透。通過(guò)在底層技術(shù)創(chuàng)新和應(yīng)用開(kāi)發(fā)兩方面持續(xù)發(fā)力,云天勵(lì)飛能否在已然卷成紅海的 AI 行業(yè)博取一塊蛋糕?還有待進(jìn)一步觀(guān)察。不過(guò),考慮云天勵(lì)飛在 AI 的軟件和硬件兩方面都已經(jīng)有了相當(dāng)厚實(shí)的技術(shù)沉淀,做到這一點(diǎn)應(yīng)該并不難。 相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀(guān)點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀(guān)點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴(lài)本文觀(guān)點(diǎn)而產(chǎn)生的任何金錢(qián)損失負(fù)任何責(zé)任。
