

 新火種
2024-11-16
新火種
2024-11-16 


強化學習之父RichardSutton給出一個簡單思路,大幅增強所有RL算法
在獎勵中減去平均獎勵
在當今的大模型時代,以 RLHF 為代表的強化學習方法具有無可替代的重要性,甚至成為了 OpenAI ο1 等模型實現(xiàn)強大推理能力的關(guān)鍵。
但這些強化學習方法仍有改進空間。近日,強化學習之父、阿爾伯塔大學教授 Richard Sutton 的團隊低調(diào)更新了一篇論文,其中提出了一種新的通用思想 Reward Centering,并稱該思想適用于幾乎所有強化學習算法。這里我們將其譯為「獎勵聚中」。
該論文是首屆強化學習會議(RLC 2024)的入選論文之一。一作 Abhishek Naik 剛剛從阿爾伯塔大學獲得博士學位,他是 Sutton 教授的第 12 位博士畢業(yè)生。
下面我們簡要看看 Reward Centering 有何創(chuàng)新之處。
論文標題:Reward Centering
論文地址:https://arxiv.org/pdf/2405.09999
獎勵聚中理論
智能體和環(huán)境之間的交互可以表述為一個有限馬爾可夫決策過程(MDP)(S, A, R, p),其中 S 表示狀態(tài)集,A 表示動作集,R 表示獎勵集,p : S × R × S × A → [0, 1] 表示轉(zhuǎn)換的動態(tài)。在時間步驟 t,智能體處于狀態(tài) S_t,使用行為策略 b : A × S → [0, 1] 采取行動 A_t,然后根據(jù)轉(zhuǎn)換動態(tài):
觀察下一個狀態(tài) S_{t+1} 和獎勵 R_{t+1}。
這里研究的問題是持續(xù)性問題,即智能體和環(huán)境的交互會無限地進行。智能體的目標是最大化長期獲得的平均獎勵。為此,該團隊考慮了估計每個狀態(tài)的預(yù)期折扣獎勵總和的方法:
這里,折扣因子不是問題的一部分,而是一個算法參數(shù)。
獎勵聚中思想很簡單:從獎勵中減去實際觀察到的獎勵的平均值。這樣做會讓修改后的獎勵看起來以均值為中心。
這種以均值為中心的獎勵在 bandit 設(shè)置中很常見。舉個例子,Sutton 和 Barto 在 2018 年的一篇論文中表明,根據(jù)觀察到的獎勵估計和減去平均獎勵可以顯著提高學習速度。
而這里,該團隊證明所有強化學習算法都能享受到這種好處,并且當折現(xiàn)因子 γ 接近 1 時,好處會更大。
獎勵聚中之所以這么好,一個底層原因可通過折現(xiàn)價值函數(shù)的羅朗級數(shù)(Laurent Series)分解來揭示。
折現(xiàn)價值函數(shù)可被分解成兩部分。其中一部分是一個常數(shù),并不依賴狀態(tài)或動作,因此并不參與動作選取。
用數(shù)學表示的話,對于與折現(xiàn)因子 γ 對應(yīng)的策略 π 的表格折現(xiàn)價值函數(shù):
其中 r(π) 是策略 π 獲得的獨立于狀態(tài)的平均獎勵,是狀態(tài) s 的微分值。它們各自對于遍歷 MDP 的定義為:
則是一個誤差項,當折現(xiàn)因子變?yōu)?1 時變?yōu)榱恪顟B(tài)值的這種分解也意味著狀態(tài)-動作值有類似的分解。
這種 Laurent 級數(shù)分解能解釋獎勵聚中為何有助于解決 bandit 問題。
在完整的強化學習問題中,與狀態(tài)無關(guān)的偏移可能會相當大。舉個例子,圖 2 中展示的三狀態(tài)馬爾科夫獎勵過程。如果狀態(tài)從 A 變成 B,則獎勵是 +3,否則都是 0。平均獎勵為 r(π) = 1。右側(cè)表中給出了三個折現(xiàn)因子的折現(xiàn)狀態(tài)值。
現(xiàn)在,從每個狀態(tài)中減去常數(shù)偏移的折現(xiàn)值,也被稱為聚中折現(xiàn)值。
可以看到,這個已經(jīng)聚中的值在幅度上要小得多,并且當折現(xiàn)因子增大時,也只會發(fā)生輕微變化。這里還給出了微分值以供參考。
這些趨勢普遍成立:對于任意問題,折現(xiàn)值的幅度都會隨著折現(xiàn)因子接近 1 而急劇增加,而聚中折現(xiàn)值則變化不大,并接近微分值。
從數(shù)學上看,聚中折現(xiàn)值是平均聚中獎勵的預(yù)期折現(xiàn)和:
其中 γ ∈ [0, 1]。當 γ = 1 時,聚中折現(xiàn)值與微分值相同。更一般地說,聚中折現(xiàn)值是微分值加上來自羅朗級數(shù)分解的誤差項,如上圖右側(cè)所示。
因此,獎勵聚中能夠通過兩個組件(恒定平均獎勵和聚中折現(xiàn)值函數(shù))捕獲折現(xiàn)值函數(shù)中的所有信息。這種分解非常有價值:
當γ→1時,折現(xiàn)值趨于爆炸,但聚中折現(xiàn)值仍然很小且易于處理。
如果問題的獎勵偏移了一個常數(shù) c,那么折現(xiàn)值的幅度就會增加 c/(1 ? γ),但聚中折現(xiàn)值會保持不變,因為平均獎勵也會增加 c。
使用獎勵聚中時,還可以設(shè)計出在智能體的生命周期內(nèi)可以改變折現(xiàn)因子(算法參數(shù))的算法。對于標準折現(xiàn)算法來說,這通常是低效或無效的,因為它們的非聚中值可能會發(fā)生巨大變化。相比之下,聚中值可能變化不大,當折現(xiàn)因子接近 1 時,變化會變得微不足道。
當然,為了獲得這些潛在好處,首先需要基于數(shù)據(jù)估計出平均獎勵。
簡單獎勵聚中以及基于價值的獎勵聚中
估計平均獎勵最簡單的方法是根據(jù)之前已經(jīng)觀察到的獎勵估計平均值。也就是說,如果表示 t 個時間步驟后的平均獎勵估計,則。更一般地,可以使用步長參數(shù) βt 來更新該估計:
該團隊表示,這種簡單的聚中方法適用于幾乎任何強化學習算法。舉個例子,獎勵聚中可以與傳統(tǒng)的時間差分(TD)學習組合起來學習一個狀態(tài)-價值函數(shù)估計:
此外,他們還提出了基于價值的獎勵聚中。這種方法的靈感來自強化學習的平均獎勵公式。Wan et al. (2021) 表明,使用時間差分(TD)誤差(而不是 (4) 中的傳統(tǒng)誤差)可以對表格離策略設(shè)置中的獎勵率進行無偏估計。事實證明,平均獎勵公式中的這個思路在折扣獎勵公式中也非常有效。
該團隊表明,如果行為策略采取目標策略所做的所有操作,那么可以使用 TD 誤差很好地近似目標策略的平均獎勵:
由于這種聚中方法除了獎勵之外還涉及價值,因此他們將其稱為基于價值的聚中。不同于簡單的獎勵聚中,現(xiàn)在平均獎勵估計和價值估計的收斂是相互依賴的。
實驗
該團隊實驗了 (5) 式的四種算法變體版本,并測試了不同的折現(xiàn)因子。詳細過程請閱讀原論文,這里我們簡單看看結(jié)果。
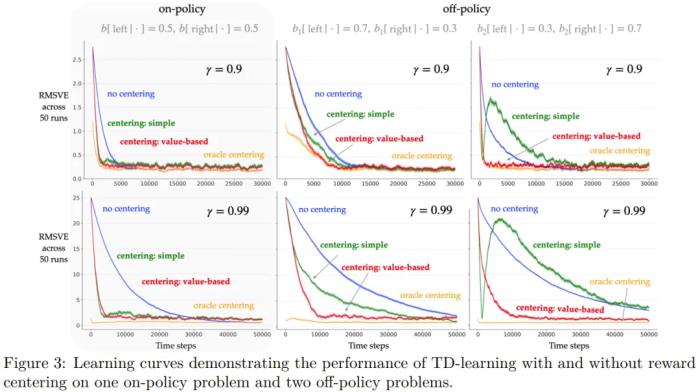
如圖 3 所示,當獎勵由一個 oracle 進行聚中處理時,學習曲線的起點會低得多。對于其它算法,第一個誤差都在 r(π)/(1 ? γ) 量級。
無聚中的 TD 學習(藍色)最終達到了與 oracle 聚中算法(橙色)相同的誤差率,這符合預(yù)期。
簡單聚中方法(綠色)確實有助于更快地降低 RMSVE,但其最終誤差率會稍微高一點。這也符合預(yù)期,因為平均獎勵估計會隨時間而變化,導致與非聚中或 oracle 聚中版本相比,更新的變數(shù)更大。當 γ 更大時也有類似的趨勢。這些實驗表明,簡單的獎勵聚中技術(shù)在在策略設(shè)置中非常有效,并且對于較大的折扣因子,效果更為明顯。
在學習率和漸近誤差方面,基于價值的獎勵聚中(紅色)在在策略問題上與簡單聚中差不多。但在離策略問題上,基于價值的聚中能以更快的速度得到更低的 RMSVE,同時最終誤差率也差不多。
總體而言,可以觀察到獎勵聚中可以提高折現(xiàn)獎勵預(yù)測算法(如 TD 學習)的學習率,尤其是對于較大的折扣因子。雖然簡單獎勵聚中方法已經(jīng)相當有效,但基于價值的獎勵聚中更適合一般的離策略問題。
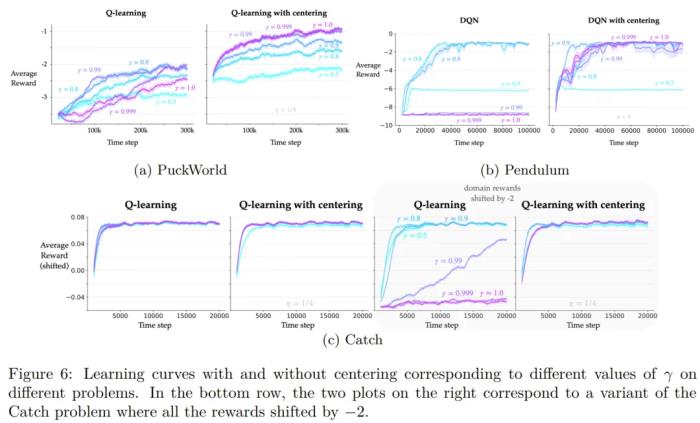
此外,該團隊還研究了獎勵聚中對 Q 學習的影響。具體的理論描述和實驗過程請訪問原論文。
總之,實驗表明,獎勵聚中可以提高 Q 學習算法的表格、線性和非線性變體在多種問題上的性能。當折現(xiàn)因子接近 1 時,學習率的提升會更大。此外,該算法對問題獎勵變化的穩(wěn)健性也有所提升。
看起來,獎勵聚中這個看起來非常簡單的方法確實可以顯著提升強化學習算法。你怎么看待這一方法,會在你的研究和應(yīng)用中嘗試它嗎?
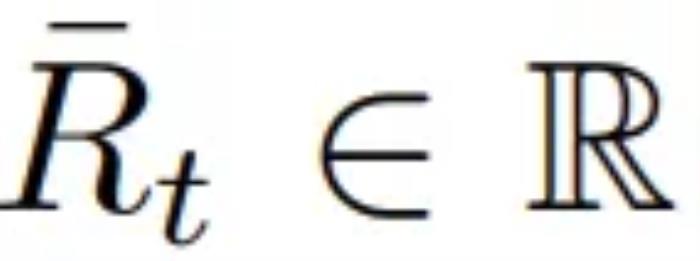
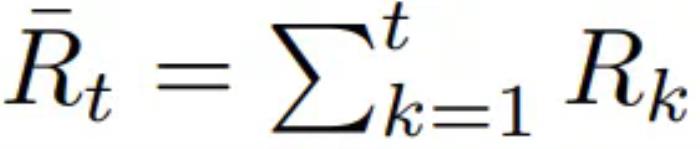

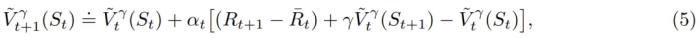
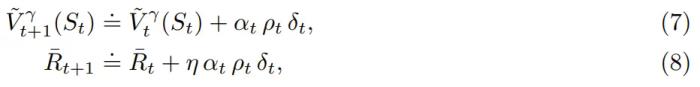

相關(guān)推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
