

 新火種
2024-09-19
新火種
2024-09-19 

推理效率提升超200%,易用性對齊vLLM,這款國產加速框架啥來頭?
2022 年 10 月,ChatGPT 的問世引爆了以大語言模型為代表的的 AI 浪潮,全球科技企業紛紛加入大語言模型的軍備競賽,大語言模型的數量、參數規模及計算需求呈指數級提升。
大語言模型(Large Language Model,簡稱 LLM 大模型)指使用大量文本數據訓練的深度學習模型,可以生成自然語言文本或理解語言文本的含義。大模型通常包含百億至萬億個參數,訓練時需要處理數萬億個 Token,這對顯卡等算力提出了極高的要求,也帶來了能源消耗的激增。
據斯坦福人工智能研究所發布的《2023 年 AI 指數報告》,大語言模型 GPT-3 一次訓練的耗電量為 1287 兆瓦時,相當于排放了 552 噸二氧化碳。隨著 AI 的進一步普及,預測到 2025 年,AI 相關業務在全球數據中心用電量中的占比將從 2% 增加至 10%。到 2030 年,智能計算年耗電量將達到 5000 億千瓦時,占全球發電總量的 5%。
除了算力與能耗,當大模型進入行業落地階段,定制化和運營成本也成為新的核心矛盾。以最新發布的 Llama 3.1 405B 為例,需要 450GB 顯存;0.6B pixart 在 A800 上生成 4096 px 的圖片需要 3 分鐘,對業務提出了極高的要求。
如何在更多的業務上應用大模型,同時降低成本,提高效率,成為行業普遍需要解決的問題。
業內推理引擎方案在大語言模型的和用戶的交互過程中,推理框架是 AI 的核心引擎,負責接收用戶的請求,并且將其進行處理和回應。整個 AI 行業都在探索如何高效利用計算資源,并行處理更多的推理請求,從而針對現有的推理構架做優化,推出新的異構算力的解決方案。
vLLM 是伯克利大學組織開源了大語言模型高速推理框架,使用 PagedAttention 高效管理注意力鍵和值內存,支持連續批處理和快速模型執行,通過引入操作系統的虛擬內存分頁思想,提高語言模型服務在實時場景下的吞吐與內存使用效率。
除 vLLM 外,眾多大模型上下游廠商也紛紛給出了自己的方案:
Text Generation Inference(TGI)是 Hugging Face 推出的支持 Hugging Face Inference API 和 Hugging Chat 上的 LLM 推理的工具,旨在支持大型語言模型的優化推理。
TensorRT-LLM 是由 NVIDIA 推出的在 TensorRT 推理引擎基礎上針對 Transformer 類大模型推理優化的工具,支持多種優化技術,如 kernel 融合、矩陣乘優化、量化感知訓練等,以提升推理性能。
DeepSpeed 是由微軟開發的分布式訓練工具,旨在支持更大規模的模型,并提供了更多的優化策略和工具,如 zero、offload 等。支持多種并行策略,如數據并行、模型并行、流水線并行以及它們的組合(3D 并行),可以在多個維度上優化模型的訓練和推理。
LightLLM 是一個基于 Python 的 LLM 推理和服務框架,以輕量級設計、易于擴展和高速性能而聞名。LightLLM 利用許多備受好評的開源實現優勢,包括 Faster Transformer、TGI、vLLM 和 Flash Attention 等。
這些框架有著不同的技術特點,具體性能和優勢也會因不同的應用場景、模型配置和硬件環境而有所差異,但依然沒有解決核心的成本問題。為此,騰訊推出了 TACO-LLM 大模型推理加速框架,為定制化、自建、上云、私有化提供完整部署方案和極致性價比。
TACO-LLM 如何實現降本增效?TACO-LLM (TencentCloud Accelerated Computing Optimization LLM)是基于騰訊云異構計算產品推出的大語言模型推理加速引擎,通過充分利用計算資源的并行計算能力,可同時處理更多的用戶請求,提高語言模型的推理效能,為客戶提供兼顧高吞吐和低時延的優化方案,幫助客戶實現降本增效。
針對各個應用場景,Taco-LLM 的優化大致分為四類:Generation 優化、Prefill 優化、長序列優化與高性能量化算子。接下來對這四個場景進行詳細介紹:
使用并行解碼進行 Generation 優化
Generation 優化是自回歸式 LLM 最重要的優化之一,幾乎覆蓋所有 LLM 應用場景。例如:文案創作、智能客服、聊天機器人、代碼生成、咨詢系統、AI 助手等; 這里 Taco-LLM 用到并行解碼,高性能算子等技術。Taco-LLM 使用并行解碼的主要優勢有:
1、并行解碼突破自 Transformer-Decoder 架構下的回歸限制,緩解 Generation 過程bandwidth bound 問題。
2、與單純增加 Generation 過程的 batch-size 相比,并行解碼是通過降低每一條請求的延時來增加吞吐,可以保證更低的 TPOT。
3、與增加 memory bandwidth 的異構方案相比,并行解碼不需要異構化集群,部署成本更低,系統更加簡單易維護。
Taco-LLM 在并行解碼上的主要嘗試是自預測方案,一是它解決了小模型從哪里來的問題,只需要使用大模型的部分層或者量化后的大模型當作小模型即可,用戶不用感知 draft model 的存在,二是該方案相比其他方案有較高的命中率,較小的冗余計算,主要用于 70B+ 的大模型推理加速。除自預測方案之外,Taco-LLM 也支持 RawLookaheadCache 和 TurboLookaheadCache 兩種 cache 方案,減少冗余計算,提高性能與整體命中率。
使用 Prefix Cache 技術降低 TTFT
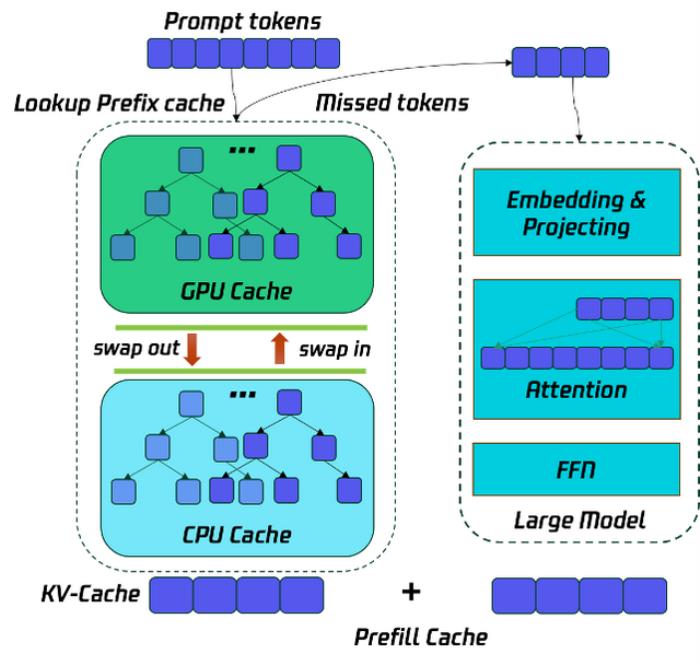
Prefill 優化的主要目標是降低 TTFT,優化用戶使用體驗,這里常用的優化是多卡并行,例如 TP 和 SP,來降低 TTFT,Taco-LLM 在此基礎上使用 GPU & CPU 結合多級緩存的 Prefix Cache 技術,讓一部分的 prompt token 通過查找歷史的 kv-cache 獲得,而不用參與 Prefill 階段的計算,減少計算量,從而降低 TTFT。這項技術在代碼助手場景尤其有效。
為了節省 Prefill 的運行時間,將歷史的請求的 prefill cache 按照前綴樹的方式保存在 GPU & CPU 中,從而將 Prefill 的計算過程轉化為 KV-Cache 的查詢過程,并將沒有命中的 Tokens 參入 Prefill 的計算,從而降低計算開銷,降低 TTFT。如下圖所示:
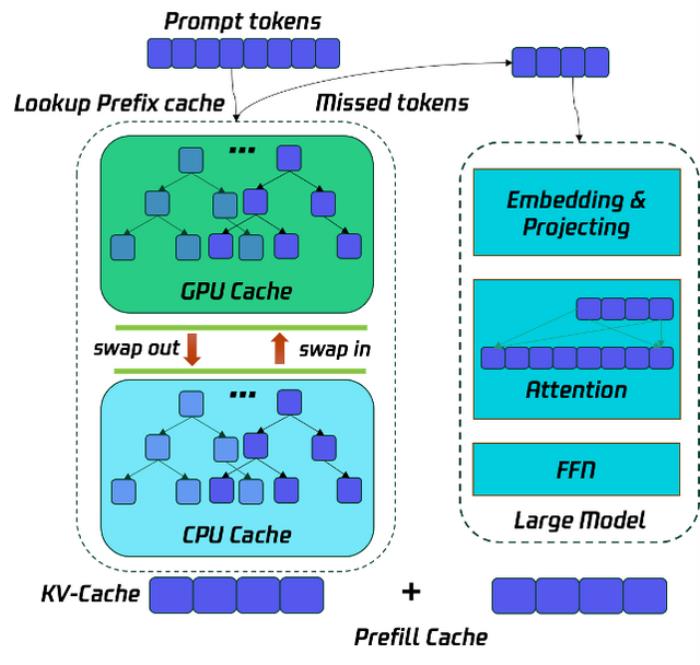
長序列推理優化中的 TurboAttention
長序列優化分為 Prefill 階段的長序列,例如文本摘要,信息檢索等,和 Generation 階段的長序列,例如長文本創作等。前者用到 Prefix Cache 和多卡并行推理技術,對于后者我們自研了 Turbo Attention 系列算子和一些優化后的量化算子。
Taco-LLM 長序列能力主要體現在 TurboAttention、Prefix Cache、和序列并行上,這里主要介紹 TurboAttention。TurboAttention 結合了 Page 管理機制和Flash機制,專門為長序列下Lookahead實現的Kernel,如下圖所示:
通過 LLM 量化技術降低推理成本
隨著 LLM 模型參數迅速增加,LLM 的推理延時和推理成本也急劇上升。LLM 量化技術成為優化 LLM 推理性能,降低推理成本的一種重要手段。高性能量化算子對于一些對精度要求不高的場景,像文本分類,文本異常檢測,文本潤色等,量化往往有較好的效果,可以有效減少 GPU 內存占用,提升推理速度。
為了達到量化預期的目標,高效的量化算子實現是必不可少的,Taco-LLM 針對 GEMM 和 Attention 兩類算子,開發了權重計算感知重排、任務調度和同步策略、快速反量化、Integer Scale 技術等多個高效的量化算子技術。
總的來說,Taco-LLM 的優化包括:通過并行解碼進行投機采樣和 LookaheadCache;Prefix Cache 的 GPU & CPU 的多級緩存技術以及內存管理技術;長序列主要包括自研的 TurboAttention 系列算子、Prefix Cache 和序列并行等;高性能量化算子包括 Taco-LLM 對 W4A8,W4A16,W8A16,W8A8 等量化算子的高效實現。
TACO-LLM 實際效果與應用案例通過各項優化技術,TACO- LLM 在性能以及成本,相較于現有的開源和廠商框架,有了明顯的優勢,且在易用性上完全對齊 vLLM。
TACO 的性能優勢直觀體現在幫助大模型服務提高吞吐和降低延遲。在 TACO 加速引擎的支持下,相同的硬件設備上能夠處理的 Token 數量顯著增加,原本每秒能處理 100 個 Token,TACO 加持后每秒能處理 200 甚至 300 個Token。吞吐的提升沒有以犧牲延遲為代價,相反每個 Token 的平均處理時間大大降低,代表響應效率和用戶體驗的提升,LLM 部署的成本也隨之大幅降低。
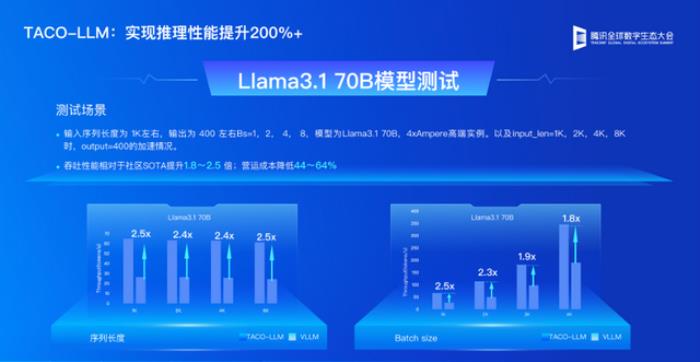
以 Llama – 3.1 70B 模型為例,在使用 4 張 Ampere 實例,輸入序列長度為 1 K 左右,輸出 為 400 左右,Bs = 1,2,4,8 的測試場景中,相較于業內主流的 vLLM,TACO – LLM 的吞吐性能相對于社區 SOTA?提升 1.8~2.5 倍;營運成本降低 44~64%,且使用方式、調用接口保持一致,支持無縫切換。
同樣以 Llama-3.1 70B 為例,使用 TACO-LLM 部署的成本低至 <$0.5/1M tokens,相比直接調用 MaaS API 的成本節約超過 60%+,且使用方式、調用接口保持一致,支持無縫切換。TACO – LLM 卓越的能效比顯著降低了 LLM 業務成本,在廣泛的實際場景中實現了降本增效:
在微信某文本處理業務中,TACO – LLM 吞吐性能相對于競品提升 2.8 倍,營運成本降低 64%,超時失敗降低約 95%,進一步擴大支持文本的最大長度。
在某頭部視頻平臺業務中,客戶希望在自建高端實例上部署推理服務,要求相對廠商官方推理框架性能提升 50% 以上。最終,TACO-LLM 在不同 bs 下相對競品性能提升 1.7~2.5 倍。
在順豐某業務中,TACO – LLM 在短輸出場景,在不同 bs 下,加速幅度為 2~3 倍;在長輸出場景,在不同 bs 下,加速幅度為 1.4 到 1.99 倍。
TACO – LLM 的出現打破了以往高昂成本對人們使用 AI 的限制,不僅能夠滿足用戶對高吞吐和低時延的需求,還能幫助企業降本增效,為大語言模型的應用提供了一種更高效、更經濟的解決方案,
在未來,隨著技術的不斷迭代,TACO – LLM 有望在更多領域得到廣泛應用,推動行業的發展和創新,讓 AI 真正走進了人們的生活,成為人們學習和生活的得力助手。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
