

 新火種
2024-09-14
新火種
2024-09-14 


GPT未竟的革命,由o1接棒:或是LLM研究最重要的發現
天下武功唯快不破,但 OpenAI 不走尋常路,新出的 o1 系列宣告天下:
我們更慢,但更強了。
o1 要花更多的時間思考問題,再做出反應,但在復雜推理層面直接竄了幾個檔位。
在國際數學奧林匹克 (IMO) 資格考試中,GPT-4o 僅正確解決了 13% 的問題,而 o1 得分為 83%。
好家伙,這數學水平,上一次見面還是小學生,現在直接博士畢業了?
OpenAI 也很得意,表示 o1 已經達到AI能力新高度了,所以直接把計數重置到1,開啟新的大模型系列 OpenAI o1。
本次 OpenAI o1系列分為三個型號,最強但還未發布的 o1,o1 的預覽版 o1-preview,和性價比最高的輕量版 o1-mini。
之前的 GPT 系列還被詬病更新“擠牙膏”,沒想到 OpenAI 一直都是老樣子,不鳴則已一鳴驚人,直接給 AI 界來了個大大大地震。
綜合網絡對于 o1 的報道和評論,我們注意到幾個關鍵信息:
這可能是Scaling Law提出以來,LLM領域最重要的發現。這一進展的核心是推理時間和參數規模兩條曲線的協同作用,而不是單一曲線;
與強化學習的完美結合,可能為我們指明了通往人工通用智能(AGI)的有效路徑(此前AI科技評論8月28日曾舉辦《大模型時代的強化學習》網絡研討會,討論了強化學習與大模型的結合,感興趣的朋友點擊下方鏈接進行回看);
o1 并非 GPT-4o 的升級版本,目前仍然無法解決像黎曼假設這樣極其復雜或開放的問題,也沒能解決幻覺問題。
OpenAI 對大模型的這次重新構想,無疑將對大模型的未來走向和整個AI領域的格局產生深遠影響。
OpenAI的又一里程碑奧特曼表示,o1 是他們迄今為止功能最強大、最一致的模型系列,只是使用的時候要花更多時間(凡爾賽了)。
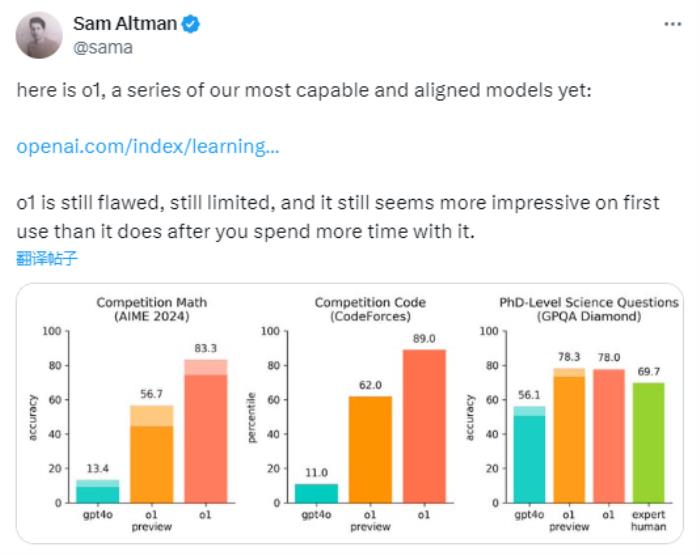
如圖所示,o1 在絕大多數重推理任務中顯著優于 GPT-4o
正在休長假、沉寂了一個月的 OpenAI 的另一位聯創 Greg Brockman 洋洋灑灑寫了一長段推文,表揚了 o1 的超強性能,并特別指出 o1 是第一個使用強化學習訓練的模型,會在回答問題之前進行深入的思考。

lmsys 也馬上在 Chatbot Arena 更新了 o1-preview 和 o1-mini,歡迎大家測試。

參與研發o1的 Shengjia Zhao 很謙虛地表示,o1 并不是完美的,也不會適合所有事情。不過人們能感受到它潛力無限,并再一次感受到 AGI。

Jim Fan 認為,o1 透露出的研究進展可能是自 2022 年 OG Chinchilla 縮放定律以來 LLM 研究中最重要的發現。

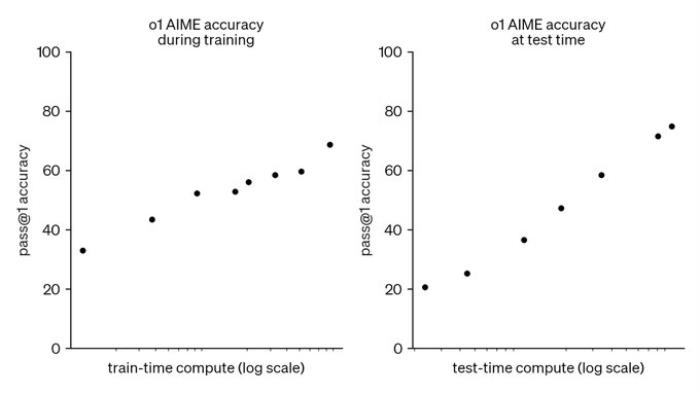
他還提到了兩篇近期發表的關于 Scaling Law 的論文,并指出 OpenAI 早已意識到這一點,并通過 o1 證實了這些發現。

大模型與強化學習的結合是近幾年來的熱門研究方向之一。
大模型的泛化能力和背景知識與強化學習的交互學習和任務優化相結合,可以創建出能夠更好地適應復雜環境、解決多任務問題、并提供更高效和可解釋決策的智能系統。這種互補性使得兩者的結合成為推動人工智能發展的重要方向。
o1 大模型的發布,首次證明了語言模型可以進行真正的強化學習。而 OpenAI 的一位研究員說,o1 證明了強化學習才是通往 AGI 道路上的必備要素(RL研究者狂喜)。
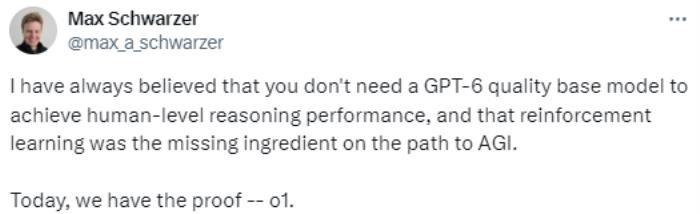
OpenAI 另一位專注推理的研究員也說,通過強化學習,o1 能夠在做出反應進行“思考”,讓他們不用再受預訓練的瓶頸限制,終于可以做擴展推理計算了。

強化學習和LLM可以說是非常適配了,只不過在 o1 之前還沒有人能用 LLM 真正實現強化學習。
之前就有人說,模仿是 LLM 訓練的基礎,而模仿其實就是強化學習的問題。
DeepMind 的新論文也有提到,與監督學習相比,強化學習可以更好地利用序列結構、在線數據并進一步提取獎勵。

領導 DeepMind 強化學習研究小組的David Silver,也在前段時間的演講中強調,“需要重新關注強化學習,才能走出 LLM 低谷。”
局限不過,一眾好評聲中,也有人指出了 o1 存在的一些問題。
Andrej Karpathy 在測試后發推特說,o1-mini 還是有大模型的老毛病,問它黎曼假設這類復雜問題就偷懶逃避。

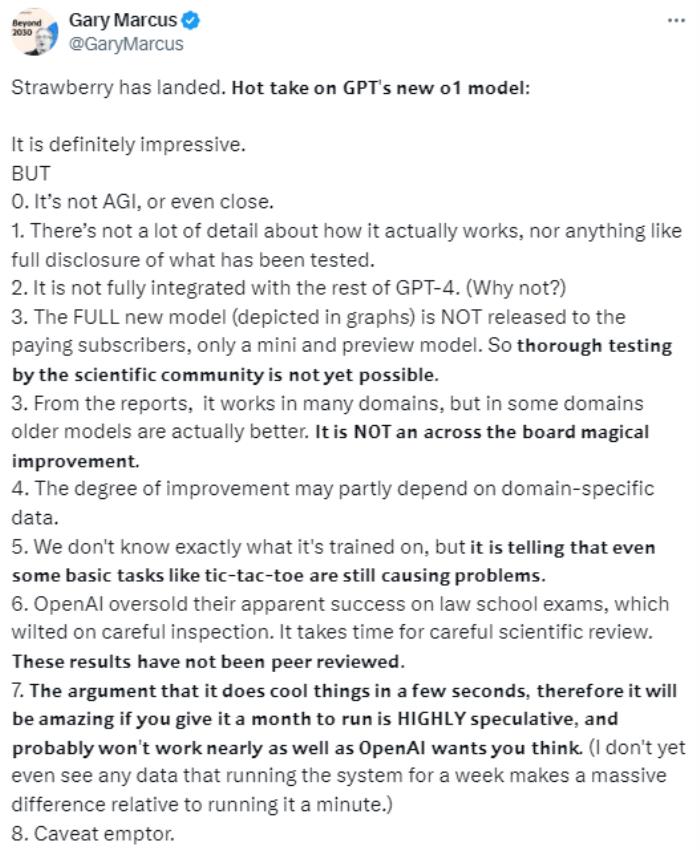
Gary Marcus 認為 o1 并不是通用人工智能(AGI),甚至離 AGI 還很遠。
他尖銳地點出了 o1 的八條問題,從多個方面批評了o1模型的細節披露不足、改進不夠全面,認為實際測試與宣傳間存在差距,并提醒消費者要慎重。
Hugging Face 的 CEO 也表示,AI 并不是在思考,只是在在“處理”、“運行預測”……和谷歌或者計算機做的事情是一樣的。這種技術系統是人類的錯誤印象,只是廉價的騙術和營銷手段,讓人誤以為它比實際更聰明。

OpenAI 自己也承認了 o1 的不足。在一些自然語言任務測試中,尤其是寫作能力方面,GPT-4o 還是更勝一籌。
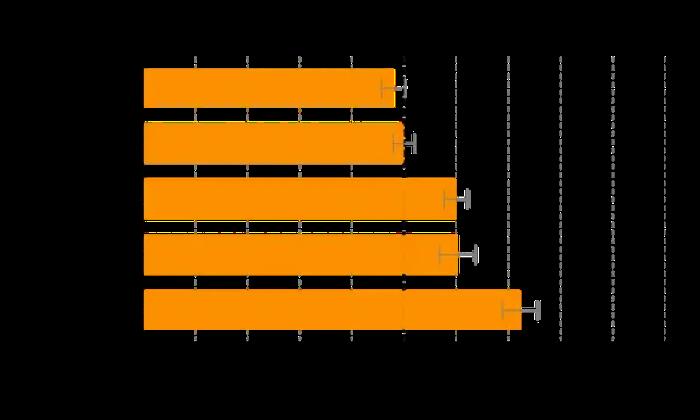
并且,o1 的推理依然存在缺陷,在實現質的提升的同時也沒能解決LLM的幻覺問題。
著名程序員、Django Web 框架的聯合創建者 Simon Willison 在推特上收集在 GPT-4o 上推理失敗,但在 o1 成功的例子,只找到了幾個讓他滿意的案例。他認為從推理來看,o1 并不是 GPT-4o 的升級版。

他在博客中寫道,o1 并不是簡單的 GPT-4o 升級版,而是通過在成本和性能方面引入重大權衡,換取了更進一步的推理能力。
很明顯,o1 和 GPT-4o 代表大模型的兩個不同方向。OpenAI 也提到,以后會分別研發升級兩個模型,這意味著,過去適用于 GPT-4o 的 Prompt 技巧未必同樣適用于 o1。
實測那么,o1 的表現到底怎么樣呢?
在 Toqan 的排行榜中,我們可以看到 OpenAI O1 模型在 ProLLM StackUnseen 基準測試中表現出來的水平,比 SOTA 要高出 20%。
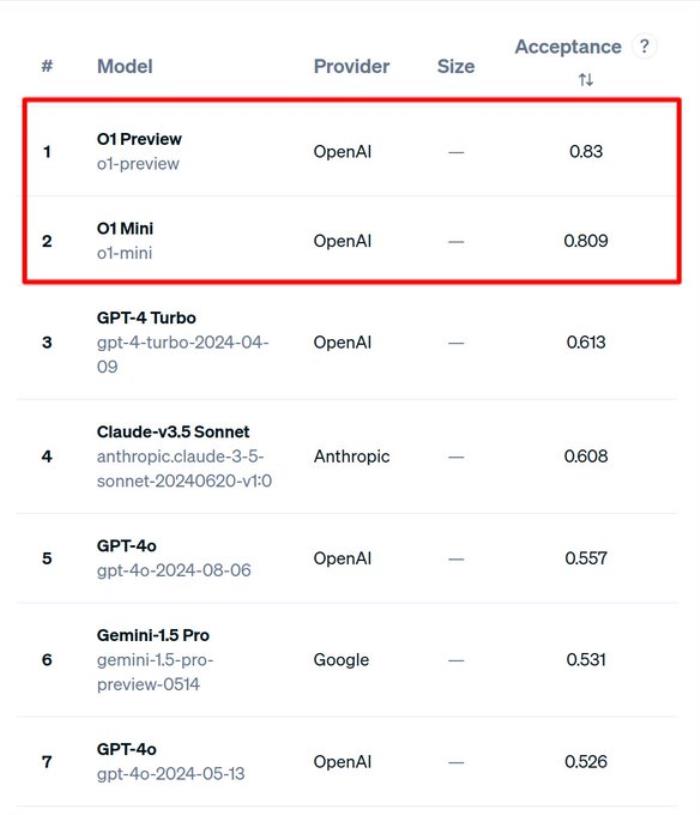
elvis 做了詳細測試,他提到 o1-preview 能夠一次性解決很多難以回答的問題,包括很多當前大型語言模型(LLMs)難以處理的數學問題。
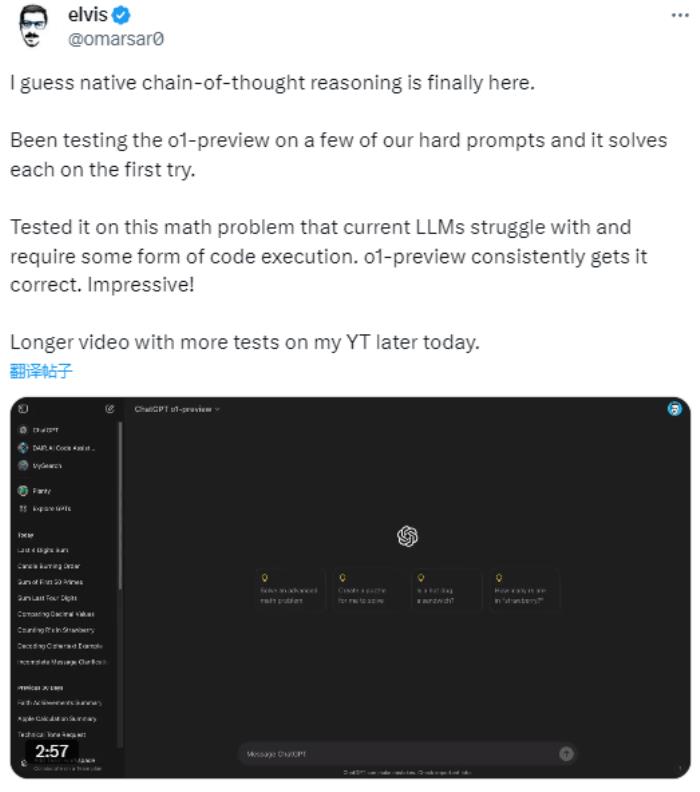
他的完整測試視頻已經上傳YouTube,可以點擊以下鏈接觀看:
https://www.youtube.com/watch?v=xJJ2h3wQByg
OpenAI 首席研究官 Bob McGrew 在The Verge的采訪中說,“從根本上說,o1 是一種新的模型模式,能夠解決真正困難的問題,從而達到與人類相似的智能水平。”
o1-preview和o1 mini已經帶給我們這么多驚喜,不敢想最后發布的o1到底能有多強悍,讓我們拭目以待。

Tags:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
