

 新火種
2024-09-04
新火種
2024-09-04 


大模型應用新戰場:揭秘終端側AI競爭關鍵|智在終端
2024年過去2/3,大模型領域的一個共識開始愈加清晰:
AI技術的真正價值在于其普惠性。沒有應用,基礎模型將無法發揮其價值。
于是乎,回顧這大半年,從互聯網大廠到手機廠商,各路人馬都在探索AI時代Killer APP的道路上狂奔。這股風潮,也開始在頂級學術會議中顯露蹤跡。
其中被行業、學術界都投以關注的一個核心問題就是:
在大模型“力大磚飛”的背景之下,AIGC應用要如何在手機等算力有限的終端設備上更絲滑地落地呢?

△Midjourney生成
這段時間以來,ICML(國際機器學習大會)、CVPR(IEEE國際計算機視覺與模式識別會議)等頂會上的最新技術分享和入選論文,正在揭開更多細節。
是時候總結一下了。
AI應用背后,大家都在聚焦哪些研究?先來看看,AI應用從云端邁向終端,現在進展到何種程度了。
目前,在大模型/AIGC應用方面,眾多安卓手機廠商都與高通保持著深度合作。
在CVPR 2024等頂會上,高通的技術Demo,吸引了不少眼球。
比如,在安卓手機上,實現多模態大模型(LLaVA)的本地部署:
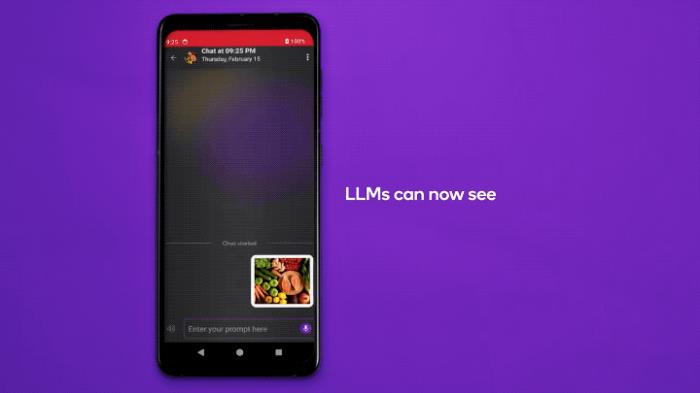
△Qualcomm Research發布于YouTube
這是一個70億參數級別的多模態大模型,支持多種類型的數據輸入,包括文本和圖像。也支持圍繞圖像的多輪對話。
就像這樣,丟給它一張小狗的照片,它不僅能描述照片信息,還能接著和你聊狗狗適不適合家養之類的話題。

△新火種在巴塞羅那MWC高通展臺拍攝的官方演示Demo
高通還展示了在安卓手機上運行LoRA的實例。
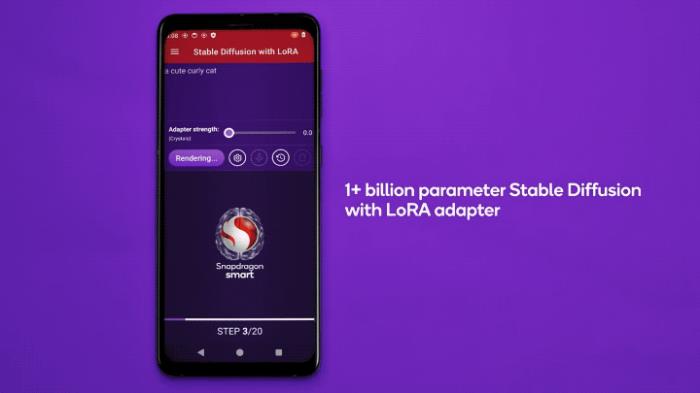
△Qualcomm Research發布于YouTube
以及音頻驅動的3D數字人版AI助手——同樣能在斷網的情況下本地運行。
Demo原型既出,加之手機廠商們的魔改優化,對于普通用戶而言,意味著其中展現的新玩法新可能,在咱們自個兒的終端設備上已經指日可待。
但在頂會上,更加受到關注的是,demo之外,高通的一系列最新論文們,還詳細地揭開了應用背后需要重點布局的關鍵技術。
量化
其中之一,就是量化。
在手機等終端設備上部署大模型/AIGC應用,要解決的一大重點是如何實現高效能的推理。
而量化是提高計算性能和內存效率最有效的方法之一。并且高通認為,使用低位數整型精度對高能效推理至關重要。
高通的多項研究工作發現,對于生成式AI來說,由于基于Transformer的大語言模型受到內存的限制,在量化到8位(INT8)或4位(INT4)權重后往往能夠獲得大幅提升的效率優勢。
其中,4位權重量化不僅對大語言模型可行,在訓練后量化(PTQ)中同樣可能,并能實現最優表現。這一效率提升已經超過了浮點模型。
具體來說,高通的研究表明,借助量化感知訓練(QAT)等量化研究,許多生成式AI模型可以量化至INT4模型。
在不影響準確性和性能表現的情況下,INT4模型能節省更多功耗,與INT8相比實現90%的性能提升和60%的能效提升。

今年,高通還提出了一種名為LR-QAT(低秩量化感知訓練)的算法,能使大語言模型在計算和內存使用上更高效。
LR-QAT受LoRA啟發,采用了低秩重參數化的方法,引入了低秩輔助權重,并將其放置在整數域中,在不損失精度的前提下實現了高效推理。
在Llama 2/3以及Mistral系列模型上的實驗結果顯示,在內存使用遠低于全模型QAT的情況下,LR-QAT達到了相同的性能。

另外,高通還重點布局了矢量量化(VQ)技術,與傳統量化方法不同,VQ考慮了參數的聯合分布,能夠實現更高效的壓縮和更少的信息丟失。

編譯
在AI模型被部署到硬件架構的過程中,編譯器是保障其以最高性能和最低功耗高效運行的關鍵。
編譯包括計算圖的切分、映射、排序和調度等步驟。
高通在傳統編譯器技術、多面體AI編輯器和編輯器組合優化AI方面都積累了不少技術成果。
比如,高通AI引擎Direct框架基于高通Hexagon NPU的硬件架構和內存層級進行運算排序,在提高性能的同時,可以最大程度減少內存溢出。
硬件加速
終端側的AI加速,離不開硬件的支持。
在硬件方面,高通AI引擎采用異構計算架構,包括Hexagon NPU、高通Adreno GPU、高通Kryo CPU或高通Oryon CPU。
其中,Hexagon NPU在今天已經成為高通AI引擎中的關鍵處理器。

以第三代驍龍8移動平臺為例,Hexagon NPU在性能表現上,比前代產品快98%,同時功耗降低了40%。
架構方面,Hexagon NPU升級了全新的微架構。與前代產品相比,更快的矢量加速器時鐘速度、更強的推理技術和對更多更快的Transformer網絡的支持等等,全面提升了Hexagon NPU對生成式AI的響應能力,使得手機上的大模型“秒答”用戶提問成為可能。
Hexagon NPU之外,第三代驍龍8在高通傳感器中樞上也下了更多功夫:增加下一代微型NPU,AI性能提高3.5倍,內存增加30%。

事實上,作為大模型/AIGC應用向終端側遷移的潮流中最受關注的技術代表之一,以上重點之外,高通的AI研究布局早已延伸到更廣泛的領域之中。
以CVPR 2024入選論文為例,在生成式AI方面,高通提出了提高擴散模型效率的方法Clockwork Diffusion,在提高Stable Diffusion v1.5感知得分的同時,能使算力消耗最高降低32%,使得SD模型更適用于低功耗端側設備。
并且不止于手機,針對XR和自動駕駛領域的實際需求,高通還研究了高效多視圖視頻壓縮方法(LLSS)等。
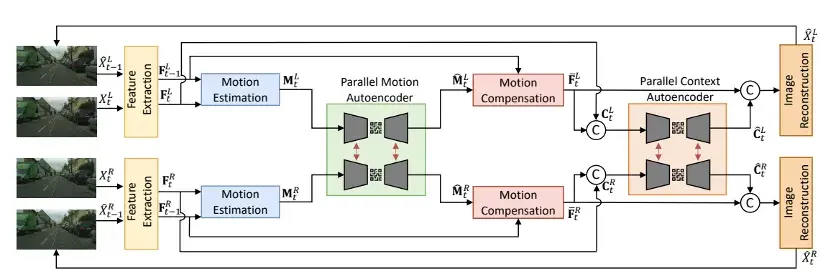
在當前的熱點研究領域,比如AI視頻生成方面,高通也有新動作:
正在開發面向終端側AI的高效視頻架構。例如,對視頻到視頻的生成式AI技術FAIRY進行優化。在FAIRY第一階段,從錨定幀提取狀態。在第二階段,跨剩余幀編輯視頻。優化示例包括:跨幀優化、高效instructPix2Pix和圖像/文本引導調節。
底層技術驅動AI創新大模型應用是當下的大勢所趨。而當應用發展的程度愈加深入,一個關鍵問題也愈加明朗:
應用創新的演進速度,取決于技術基座是否扎實牢固。
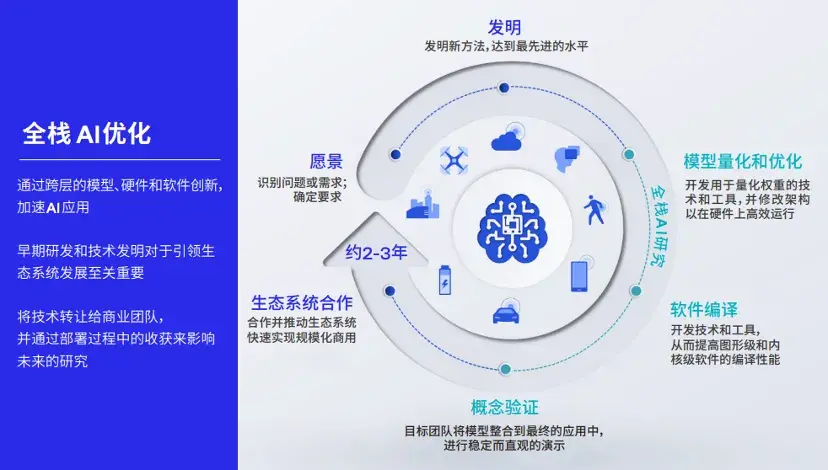
這里的技術基座,指的不僅是基礎模型本身,也包括從模型量化壓縮到部署的全棧AI優化。
可以這樣理解,如果說基礎模型決定了大模型應用效果的上限,那么一系列AI優化技術,就決定了終端側大模型應用體驗的下限。
作為普通消費者,值得期待的是,像高通這樣的技術廠商,不僅正在理論研究方面快馬加鞭,其為應用、神經網絡模型、算法、軟件和硬件的全棧AI研究和優化,也已加速在實踐中部署。

以高通AI軟件棧為例。這是一套容納了大量AI技術的工具包,全面支持各種主流AI框架、不同操作系統和各類編程語言,能提升各種AI軟件在智能終端上的兼容性。
其中還包含高通AI Studio,相當于將高通所有AI工具集成到了一起,包括AI模型增效工具包、模型分析器和神經網絡架構搜索(NAS)等。
更為關鍵的是,基于高通AI軟件棧,只需一次開發,開發者就能跨不同設備隨時隨地部署相應的AI模型。
就是說,高通AI軟件棧像是一個“轉換器”,能夠解決大模型在種類繁多的智能終端中落地所面臨的一大難題——跨設備遷移。
這樣一來,大模型應用不僅能從云端走向手機端,還能被更快速地塞進汽車、XR、PC和物聯網設備中。
站在現在的時間節點,人人都在期待改變世界的技術潮流翻騰出更洶涌的巨浪。
而站立潮頭的弄潮兒們正在再次驗證技術史中一次次被探明的事實:引領技術之先的人和組織,無不具備重視基礎技術的“發明家文化”。
不止是追趕最新的技術趨勢,更要提前布局,搶先攻克基本方案。
高通在《讓AI觸手可及》白皮書中同樣提到了這一點:
高通深耕AI研發超過15年,始終致力于讓感知、推理和行為等核心能力在終端上無處不在。
這些AI研究和在此之上產出的論文,影響的不僅是高通的技術布局,也正在影響整個行業的AI發展。
大模型時代,“發明家文化”仍在延續。
也正是這樣的文化,持續促進著新技術的普及化,促進著市場的競爭和繁榮,帶動起更多的行業創新和發展。
你覺得呢?
— 完 —
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
