

 新火種
2024-08-22
新火種
2024-08-22 


賈佳亞團隊聯手劍橋清華等共推評測新范式一秒偵破大模型“高分低能”

賈佳亞團隊全新評測基準MR-Ben發布,拒絕大模型“高分低能”
隨著人工智能領域經歷GPT時刻,學術界和產業界共同發力,每月甚至每周都有新的模型問世,大模型產品之多可以說是讓人眼花繚亂。為了篩選出真正業界領先的大模型產品,業內衍生出了錯綜復雜的各類大模型評測方式,大家都希望為大模型做出客觀公正的評測,看看究竟哪家產品能力更強。
但為了在行業中“脫穎而出”,業內也不斷出現類似“刷榜”的做法,通過專項針對評測題庫進行“預訓練”從而獲取高評分,導致部分大模型出現“高分低能”的現象,在實際場景當中表現不佳。
為此,賈佳亞團隊聯合MIT、清華、劍橋等多家知名高校,與國內頭部標注公司合作,標注了一個針對復雜問題推理過程的評測數據集MR-Ben,基于GSM8K、MMLU、LogiQA、MHPP等大模型預訓練必測數據集的題目,進行“閱卷式”的范式改造,生成更難、更有區分度的新數據集,從而真實地反映模型推理能力。
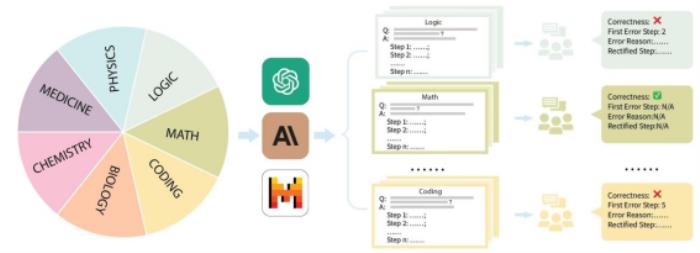
從“刷題考生”變“閱卷老師”,閱卷式考察反映大模型真實水平
目前主流大模型評測是使用人類的標準化考試——選擇題和填空題的方式去進行大模型評測。使用這套測試方式的好處有很多, 標準明確、指標直觀,且量化結果天然具有話題性。
但作者認為這種逐步作答的思維鏈方式生成最終答案,并不“靠譜”。
結合大模型的訓練方式來看,預訓練模型在預訓練時早已見過數以萬億級別的詞元,很難說被評測的模型是否早已見過相應的數據,從而通過“背題”的方式回答正確。而在分步作答的時候,模型是否是基于正確的理解推理選出正確的選項,我們不得而知,因為評測的方式主要靠檢查最終的答案。
盡管學術界不斷地對諸如GSM8K、MMLU等數據集進行升級改造,如在GSM8K上引入多語言版本的MGSM數據集,在MMLU的基礎上引入更難的題目等,依然無法擺脫選擇或填空的窠臼。并且,這些數據集都已面臨著嚴重的飽和問題,大語言模型在這些指標上的數值已經見頂,并逐漸喪失了區分度。
而賈佳亞團隊的選擇是從評測模式的底層進行改革,從而真實反映模型推理能力。
害怕數據泄露導致的大模型背題導致分數虛高嗎?賈佳亞團隊打造的MR-Ben不用重新找題出卷,也不用把題目變形來測試模型的穩健性,MR-Ben直接讓模型從答題者的學生身份,轉變為對答題過程的“閱卷”模式,讓大模型當老師來測試它對知識點的掌握情況!
不是擔心模型對解題過程毫無知覺,有可能出現“幻覺”或錯誤的理解,蒙對答案嗎?MR-Ben直接招聘一批高水平的碩博標注者,對大量題目的解題過程進行精心標注。把解題過程是否正確,出錯的位置,出錯的原因都細致指出,比對大模型的閱卷結果和人類專家的閱卷結果來測試模型的知識點掌握情況。
具體來說,賈佳亞團隊針對市面上主流的評測數據集GSM8K、MMLU、LogiQA、MHPP等數據集進行整理,并分成了數理化生、代碼、邏輯、醫藥等多個類別,同時區分了不同的難度等級。針對每個類別、收集到的每個問題,團隊精心收集了對應的分步解題過程,并經由專業的碩博標注者進行培訓和標注。
從評測方式來看,MR-Ben所提出的方法需要模型對于解題過程的每一個步驟的前提、假設、邏輯都進行細致分析,并對推理過程進行預演來判斷當前步驟是否能導向正確答案。
這種“閱卷”式的評測方式從難度上遠超于僅答題的評測方式,但可有效避免模型背題所導致的分數虛高問題。而只會背題的學生很難成為一名合格的閱卷老師。
其次,MR-Ben通過使用了人力精細的標注流程控制,取得了大量的高質量標注,而巧妙的流程設計又使得評測方式能夠直觀地量化。
知名大模型公開評測,GPT4-Turbo表現最佳
賈佳亞團隊針對性測試了時下最具代表性的十大大語言模型和不同版本。可以看到,閉源大語言模型里,GPT4-Turbo的表現最佳(雖然在“閱卷”時未能發現計算錯誤),在絕大部分的科目里,有demo(k=1)和無demo(k=0)的設置下都領先于其他模型。
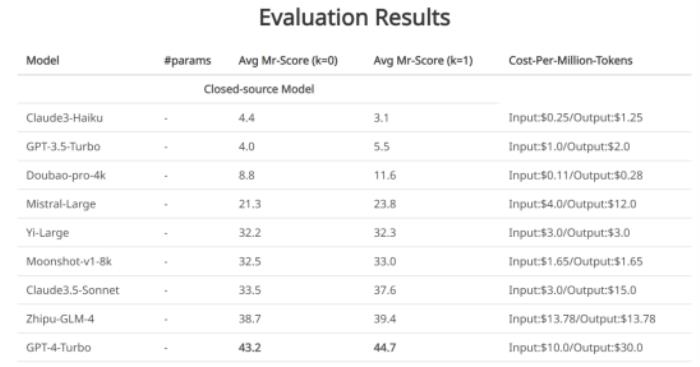
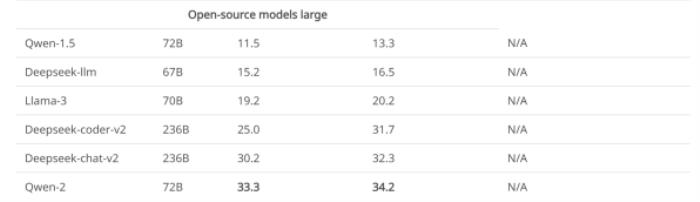
部分開源大語言模型在MR-Ben數據集上的測評結果
可以看到,最強的部分開源大語言模型效果已經趕上了部分商用模型,并且哪怕最強的閉源模型在MR-Ben數據集上表現也仍未飽和,不同模型間的區分度較大。
除此之外,MR-Ben的原論文里還有更多有意思的解析和發現,例如:
?Qwen和Deepseek發布的開源模型哪怕在全球梯隊里,PK閉源模型效果也不遜色。
?不同的閉源模型定價策略和實際表現耐人尋味。在使用場景里關注推理能力的小伙伴,可以對照價格和能力找到自己心儀的模型去使用。
?低資源場景下,小模型也有不少亮點,MR-Ben評測中Phi-3-mini在一眾小模型里脫穎而出,甚至高于或持平幾百億參數的大模型,展現出了微調數據的重要性。
?MR-Ben場景包含復雜的邏輯解析和逐步推斷,Few-shot模式下過長的上下文反而會使得模型困惑,造成水平下降的后果。
?MR-Ben評測了不少生成-反思-重生成的消融實驗,查看不同提示策略的差異,發現對低水平的模型沒有效果,對高水平的模型如GPT4-Turbo效果也不明顯。反而對中間水平的模型因為總把錯的改對,對的改錯,效果反而略有提升。
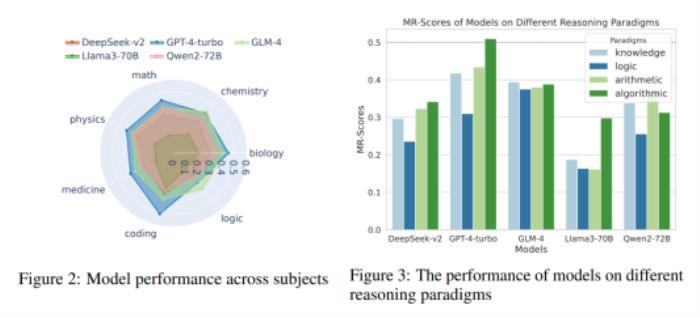
?將MR-Ben評測的科目粗略劃分成知識型、邏輯型、計算型、算法型后,不同的模型在不同的推理類型上各有優劣。
目前賈佳亞團隊已在github上傳一鍵評測的方式,歡迎所有關注復雜推理的小伙伴在自家的模型上評測并提交,團隊會及時更新相應的leaderboard。使用官方的腳本一鍵評測,只需花費12M tokens左右,過程非常絲滑,值得一試。
Project Page: https://randolph-zeng.github.io/Mr-Ben.github.io/
Arxiv Page: https://arxiv.org/abs/2406.13975
Github Repo: https://github.com/dvlab-research/Mr-Ben
參考
1.Training Verifiers to Solve Math Word Problems(https://arxiv.org/abs/2110.14168)
2.Measuring Massive Multitask Language Understanding(https://arxiv.org/abs/2009.03300)
3.LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning(https://arxiv.org/abs/2007.08124)
4.MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation(https://arxiv.org/abs/2405.11430)
5. Sparks of Artificial General Intelligence: Early experiments with GPT-4(https://arxiv.org/abs/2303.12712)
6. Qwen Technical Report(https://arxiv.org/abs/2309.16609)
7. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(https://arxiv.org/abs/2405.04434)
8. Textbooks Are All You Need(https://arxiv.org/abs/2306.11644)
9. Large Language Models Cannot Self-Correct Reasoning Yet(https://arxiv.org/abs/2310.01798)
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
