

 新火種
2024-08-22
新火種
2024-08-22 


視頻生成賽道再添“猛將”,智譜清影正式上線
年初Sora橫空出世,驗證了Scalling Law在視頻生成方面的有效性。但Sora始終止步于公開的60秒demo,產品落地計劃遲遲未有公開。
隨后的半年時間,不少“玩家”繼續在AI視頻生成賽道展開角逐,并逐步實現落地。今年6月,快手打“前鋒”,發布即可用的“可靈”成為國內視頻生成賽道的“黑馬”。
緊隨其后,國外知名3D建模平臺Luma AI也高調入局,發布文生視頻模型 ,并宣布對所有用戶免費開放使用,再掀波瀾。
昨日,快手進一步宣布全面開放內測,同時推進商業化,上線了會員付費體系。
而就在今日,智譜也正式上線了AI視頻生成功能清影(Ying),正式入局文生視頻及圖生視頻賽道,生成6秒視頻僅需30秒的時間。首發測試期間,可以免費試用。
值得關注的是,智譜是目前國內超200億估值的大模型公司中、第一家發布視頻生成成果的創業團隊。
此前,智譜在外界傳遞的技術優勢以文本、檢索為先,Tier 1中多模態能力被寄予眾望的兩家是月之暗面、MiniMax,但在視頻生成上,智譜卻先人一步,率先亮出了耀眼的成績。
快速的多模態能力成長,不僅得益于行業的技術進步,展露了智譜在多模態算法、算力儲備上少為人關注的“肌肉”,更歸功于智譜的扎實積累:
實際上,智譜在all in大模型之初就開始布局多模態,且在2022年率先發布了基于大模型的文本到視頻生成模型CogVideo。
智譜清影便是基于這一模型的升級版——CogVideoX實現的。
“CogVideoX能將文本、時間、空間三個維度融合起來,參考了Sora的算法設計,它也是一個DiT架構,通過優化,CogVideoX相比前代(CogVideo)推理速度提升了6倍。我們將繼續努力迭代,在后續版本中,陸續推出更高分辨率、更長時長的生成視頻功能。”智譜AI CEO張鵬說道。
智譜“清影”正式上線
今日,智譜在Open Day上正式發布“清影”后,當前,在智譜清言平臺上,該功能已正式開放內測,支持PC、APP及小程序。
目前,清影所能生成的視頻時長為6s,渲染時長在30s左右。此外,所生成視頻的分辨率已達1440p。
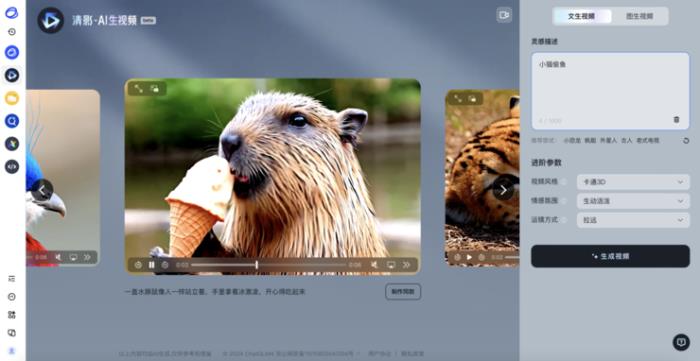
(鏈接:https://chatglm.cn/video)
從文生視頻的具體操作來看,輸入一段文字后(俗稱“Prompt”),便可以自主選擇想要生成的風格,包括卡通3D、黑白、油畫、電影感等,再疊加清影自帶的音樂,隨即生成視頻。
同步上線的還有圖生視頻功能,包括表情包梗圖、廣告制作、劇情創作、短視頻創作等。同時,基于清影的“老照片動起來”小程序也將上線,清影在讓老照片“復活”方面表現可觀,且能夠自動實現上色:

原圖為未上色黑白版
https://sfile.chatglm.cn/testpath/video/6954cc06-7293-5144-a410-dc53c980a9b6_0.mp4
生成后視頻(指令為:圖中的奶奶帶上頭戴式耳機)
從生成視頻的類型維度上看,清影主要在風景、動物、超現實、人文歷史類需求上表現更好;在視頻風格維度上,皮克斯風格、卡通風格、攝影風格、動漫風格均能夠自主選擇;鏡頭畫面實現效果最好的是近景。
需要注意的是,在實操過程中,提示詞作為重要一環,會對生成視頻的效果產生一定影響。
例如,描述為“小男孩喝咖啡”與“攝影機平移,一個小男孩坐在公園的長椅上,手里拿著一杯熱氣騰騰的咖啡。他穿著一件藍色的襯衫,看起來很愉快,背景是綠樹成蔭的公園,陽光透過樹葉灑在男孩身上。”所達成的效果便不盡相同。
此外,為了使提示詞更加清晰可執行,智譜還相應地提供了文生視頻及圖生視頻的prompt智能體,輔助達成更好的視頻生成效果。在圖生視頻界面,直接點擊“幫我想一條”即可快速獲得提示詞。
從價格上來看,此次首發測試期間,所有用戶均可免費使用。
當前,清影生成視頻需要排隊等待1分鐘以上,而如需走VIP通道快速“提貨”,則需要購買加速包。清影界面顯示,解鎖一天(24小時)的高速通道權益收費5元,付費199元解鎖一年付費高速通道權益。
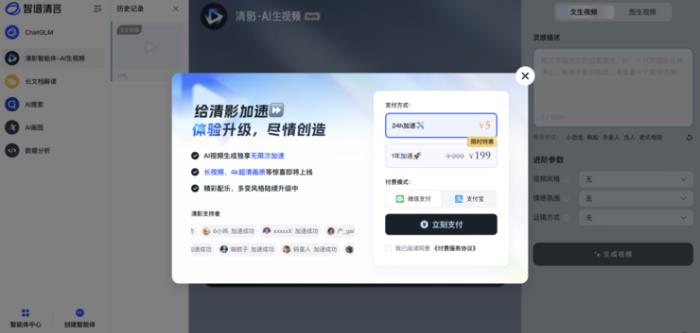
值得一提的是,智譜還將成為國內首個面向開發者開放視頻生成大模型的廠商。在CogVideoX上線開放平臺后,開發者可以通過調用API的方式,體驗和使用文生視頻以及圖生視頻的模型能力。
依托自研提質增效
清影主要依托于智譜團隊自研的視頻生成大模型CogVideoX。
而從技術維度進行深度剖析來看,首先,智譜自研了一個高效的三維變分自編碼器結構(3D VAE)來解決內容連貫性的問題,將原視頻空間壓縮至2%大小,以減少視頻擴散生成模型的訓練成本及訓練難度。
模型結構方面,采用因果三維卷積(Causal 3D convolution)為主要模型組件,移除了自編碼器中常用的注意力模塊,使得模型具備不同分辨率遷移使用的能力。
同時,在時間維度上因果卷積的形式也使得模型具備視頻編解碼具備從前向后的序列獨立性,便于通過微調的方式向更高幀率與更長時間泛化。
從工程部署的角度,基于時間維度上的序列并行(Temporal Sequential Parallel)對變分自編碼器進行微調及部署,使其具備支持在更小的顯存占用下支持極高幀數視頻的編解碼的能力。
其次,針對目前的視頻數據大多缺乏對應的描述性文本或者描述質量低下的情況,智譜自研了一個端到端的視頻理解模型,用于為海量的視頻數據生成詳細的、貼合內容的描述,增強模型的文本理解和指令遵循能力,使生成的視頻更符合用戶的輸入,能夠理解超長復雜prompt指令。
最后,智譜還自研了一個將文本、時間、空間三個維度全部融合起來的transformer架構,摒棄了傳統的cross attention模塊,在輸入階段就將文本embedding和視頻embedding concat起來,以便更充分地進行兩種模態的交互。
由于兩種模態的特征空間存在很大差異,智譜進一步通過expert adaptive layernorm對文本和視頻兩個模態分別進行處理來彌補,更有效地利用擴散模型中的時間步信息,使得模型能夠高效利用參數來更好地將視覺信息與語義信息對齊。
其中,注意力模塊采用了3D全注意力機制,先前的研究通常使用分離的空間和時間注意力,或者分塊時空注意力,需要大量隱式傳遞視覺信息,大大增加了建模難度,同時,也無法與現有的高效訓練框架適配。位置編碼模塊設計了3D RoPE,更有利于在時間維度上捕捉幀間關系,建立起視頻中的長程依賴。
多模態領域厚積薄發
多模態大模型技術底座的支撐,讓智譜發布“清影”,成為積淀已久的使然。2021年,智譜正式發布文生圖大模型CogView,次年迭代至CogView2,并在今年發布CogView3。
而實際上,早在2022年,基于CogView,智譜團隊便已正式推出了文生視頻大模型CogVideo。
據介紹,CogVideo采用多幀率分層訓練策略生成高質量的視頻片段,提出一種基于遞歸插值的方法,逐步生成與每個子描述相對應的視頻片段,并將這些視頻片段逐層插值得到最終的視頻片段。
過去一年多,智譜在多模態大模型發展上一路狂飆。2023年3月,智譜推出了千億開源基座對話模型ChatGLM,5月,又發布了圖文對話大模型VisualGLM,隨后,迅速在6月、10月推出迭代版的ChatGLM2與ChatGLM3,并在今年1月迭代至GLM-4。
去年年末,智譜還推出了多模態對話模型CogVLM,今年逐步迭代至CogVLM2。
智譜GLM大模型團隊認為,“文本是構建大模型的關鍵基礎,下一步則應該把文本、圖像、視頻、音頻等多種模態混合在一起訓練,構建真正原生的多模態模型。”未來大模型的技術突破方向之一就是原生多模態大模型。
當前,“多模態模型的探索還處于非常初級的階段”。從生成視頻的效果看,對物理世界規律的理解、高分辨率、鏡頭動作連貫性以及時長等,都有非常大的提升空間。而從模型本身角度看,需要更具突破式創新的新模型架構,能夠更高效壓縮視頻信息,更充分融合文本和視頻內容,貼合用戶指令的同時,讓生成內容真實感更高。
而在生成式視頻模型的研發中,Scaling Law將繼續在算法和數據兩方面發揮作用。“我們積極在模型層面探索更高效的scaling方式。”張鵬表示,“隨著算法、數據不斷迭代,相信Scaling Law將繼續發揮強有力作用。”

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
