

 新火種
2024-06-11
新火種
2024-06-11 


5秒完成3D生成,合成數(shù)據(jù)集已開源,上交港中文框架超越Instant3D
使用大模型合成的數(shù)據(jù),就能顯著提升3D生成能力?
來自上海交大、香港中文大學(xué)等團(tuán)隊還真做到了。

他們推出Bootstrap3D框架,結(jié)合微調(diào)的具備3D感知能力的多模態(tài)大模型。這個框架能夠自動生成任意數(shù)量的高質(zhì)量的多視角圖片數(shù)據(jù),助力多視圖擴(kuò)散模型的訓(xùn)練。
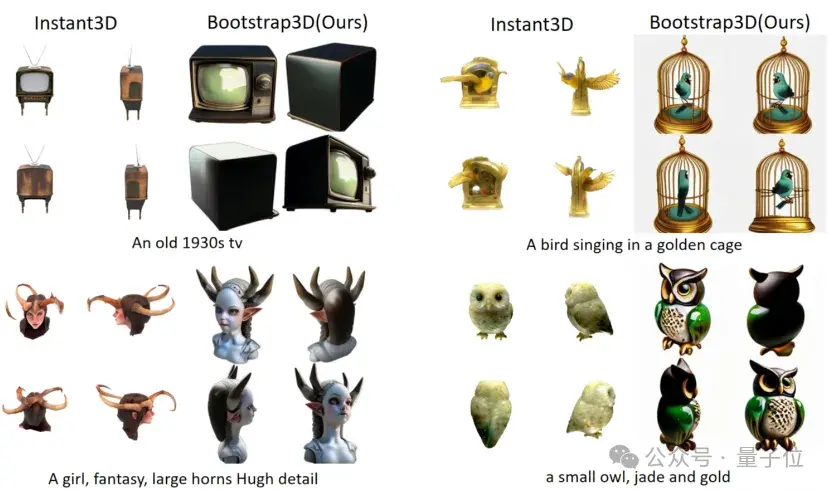
結(jié)果表明,新的合成數(shù)據(jù)能夠顯著提高現(xiàn)有3D生成模型的生成物體的美學(xué)質(zhì)量和文本prompt的控制能力。
目前,Bootstrap3D的數(shù)據(jù)集已經(jīng)全面開源。
用大模型合成數(shù)據(jù)
近年來,3D內(nèi)容生成技術(shù)迎來了飛速發(fā)展。然而,相對于2D圖片生成,生成高質(zhì)量的3D物體仍面臨諸多挑戰(zhàn)。
其中核心的瓶頸即在于3D數(shù)據(jù),尤其是高質(zhì)量數(shù)據(jù)的不足。
為了解決這一問題,研究團(tuán)隊推出Bootstrap3D框架,通過自動生成多視圖圖像數(shù)據(jù)來解決3D內(nèi)容生成中高質(zhì)量數(shù)據(jù)不足的問題。
具體來說,這個框架采用了2D和視頻擴(kuò)散模型來生成多視圖圖像,并利用一個經(jīng)過微調(diào)的3D多模態(tài)大模型對生成的數(shù)據(jù)進(jìn)行質(zhì)量篩選和描述重寫。
通過這種方式,Bootstrap3D能夠自動產(chǎn)生大量高質(zhì)量的3D圖像數(shù)據(jù),從而“自舉”出一個足夠大的數(shù)據(jù)集,輔助訓(xùn)練更優(yōu)秀的多視圖擴(kuò)散模型。
這里插一嘴,在計算機(jī)科學(xué)和機(jī)器學(xué)習(xí)領(lǐng)域,“Bootstrap”通常指的是一種通過自舉方法解決問題的技術(shù)。
數(shù)據(jù)構(gòu)建Pipeline
具體來說,數(shù)據(jù)構(gòu)建Pipeline是本次框架的核心創(chuàng)新之一,旨在自動生成高質(zhì)量的多視圖圖像數(shù)據(jù),并附帶詳細(xì)的描述文本。
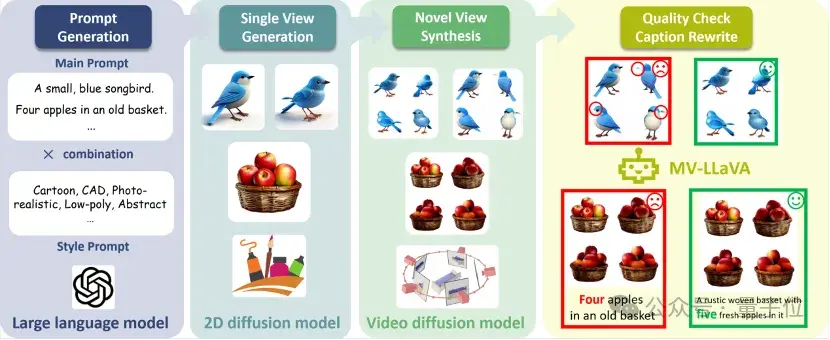
主要分為以下幾個步驟:
文本提示生成:首先,使用強(qiáng)大的大語言模型(如GPT-4)生成大量富有創(chuàng)意和多樣化的文本提示。這些文本提示涵蓋了各種場景和物體,為后續(xù)的圖像生成提供了豐富的素材。
圖像生成:利用2D擴(kuò)散模型和視頻擴(kuò)散模型,根據(jù)生成的文本提示創(chuàng)建單視圖圖像。通過結(jié)合2D和視頻擴(kuò)散模型的優(yōu)勢,生成的圖像具有更高的初始質(zhì)量和多樣性。
多視圖合成:使用視頻擴(kuò)散模型將單視圖圖像擴(kuò)展為多視圖圖像,生成不同角度的視圖。這一步驟確保了每個對象在不同視角下的一致性,解決了傳統(tǒng)方法中視圖不一致的問題。
質(zhì)量篩選和描述重寫:通過我們微調(diào)的3D感知模型MV-LLaVA,對生成的多視圖圖像進(jìn)行嚴(yán)格的質(zhì)量篩選。篩選過程不僅過濾掉低質(zhì)量的數(shù)據(jù),還重寫描述文本,使其更加準(zhǔn)確和詳細(xì)。
通過這個數(shù)據(jù)構(gòu)建Pipeline,Bootstrap3D能夠生成大量高質(zhì)量的3D圖像數(shù)據(jù),為多視圖擴(kuò)散模型的訓(xùn)練提供了堅實的基礎(chǔ)。
這一創(chuàng)新不僅解決了3D數(shù)據(jù)稀缺的問題,還顯著提升了模型的生成效果和對文本提示的響應(yīng)能力。
訓(xùn)練timestep重安排(TTR)
團(tuán)隊還提出了一種創(chuàng)新的訓(xùn)練timestep重新安排策略(TTR),以解決多視圖擴(kuò)散模型訓(xùn)練中的圖像質(zhì)量和視圖一致性問題。
TTR策略的核心理念是在訓(xùn)練過程中靈活調(diào)整合成數(shù)據(jù)和真實數(shù)據(jù)的訓(xùn)練時間步,從而優(yōu)化去噪過程的不同階段。
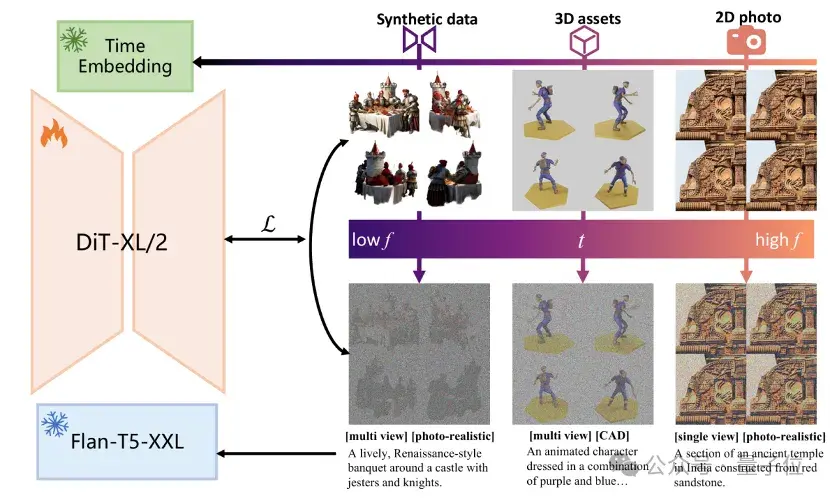
去噪過程的階段性特征:在擴(kuò)散模型中,去噪過程通常分為不同的時間步。在早期時間步,去噪過程主要關(guān)注圖像的整體結(jié)構(gòu)和形狀(低頻成分);在后期時間步,則主要生成圖像的細(xì)節(jié)和紋理(高頻成分)。這種階段性特征為我們提供了調(diào)整訓(xùn)練策略的機(jī)會。
限制合成數(shù)據(jù)的訓(xùn)練時間步:由于合成數(shù)據(jù)可能存在一些模糊和失真,我們在訓(xùn)練時限制其時間步范圍。具體來說,我們讓合成數(shù)據(jù)主要參與早期的去噪階段,確保它們對整體結(jié)構(gòu)的貢獻(xiàn),而將后期的細(xì)節(jié)生成留給質(zhì)量更高的真實數(shù)據(jù)。
分階段訓(xùn)練策略:通過將合成數(shù)據(jù)限制在較大的時間步范圍內(nèi)(如200到1000步),我們確保這些數(shù)據(jù)在去噪過程中主要影響圖像的低頻成分,從而保持視圖一致性。同時,真實數(shù)據(jù)則參與所有時間步的訓(xùn)練,以提供高頻細(xì)節(jié)和真實感。這樣的分階段訓(xùn)練策略有效平衡了圖像質(zhì)量和視圖一致性。
實驗證明效果顯著:廣泛的實驗結(jié)果表明,使用TTR策略的多視圖擴(kuò)散模型在圖像-文本對齊、圖像質(zhì)量和視圖一致性方面均表現(xiàn)優(yōu)異。該策略不僅保留了原始2D擴(kuò)散模型的優(yōu)點(diǎn),還顯著提升了多視圖生成的效果。
通過訓(xùn)練時間步重新安排策略(TTR),Bootstrap3D框架成功解決了合成數(shù)據(jù)質(zhì)量參差不齊的問題,顯著提升了多視圖擴(kuò)散模型的性能,為高質(zhì)量3D內(nèi)容生成奠定了堅實基礎(chǔ)。
好了,Bootstrap3D生成的數(shù)據(jù)集已經(jīng)全面開源,任何研究人員和開發(fā)者都可以免費(fèi)訪問和使用。
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
