

 新火種
2024-05-22
新火種
2024-05-22 


黑馬!大模型競技場榜單更新,國產玩家首次進入全球總榜前10
龍爭虎斗的大模型競技場,今天突然更新:
國內大模型公司零一萬物旗下的Yi-Large千億參數閉源大模型,躍升總榜第七,也成為榜上國產大模型第一。
可以看到,它的成績幾乎與GPT-4-0125-preview持平。
同時,國內清華系大模型公司智譜華章的GLM-4-0116也殺進總榜,位居第15位。
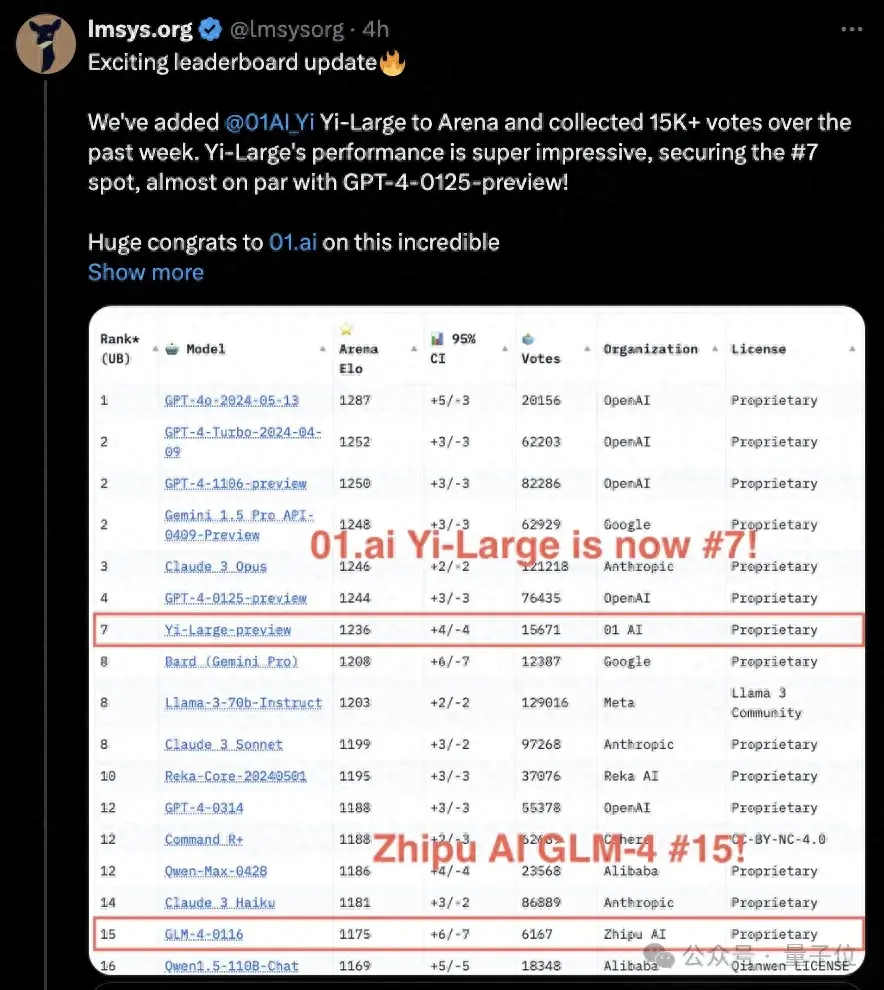
這個結果來自累積超1170萬全球用戶的真實盲測投票數。
而且大模型競技場最近修改了規則,只要大模型亮明身份后就不能再繼續投票,杜絕了刷分的可能性。
再來看Yi-Large排名之前的前6名中,有4個模型來自GPT,另外有1個谷歌的Gemini,1個Anthropic的Claude。
零一萬物創始人兼CEO李開復博士為此表示,LMSYS提供了一個第三方的、公正的平臺,其他競爭對手也都非常認可。
而零一萬物的團隊規模、參數規模、GPU算力都比排名更靠前的模型“小”。
Yi-Large成排名飛升黑馬
大模型競技場官推還給出了Yi-Large的更多成績:
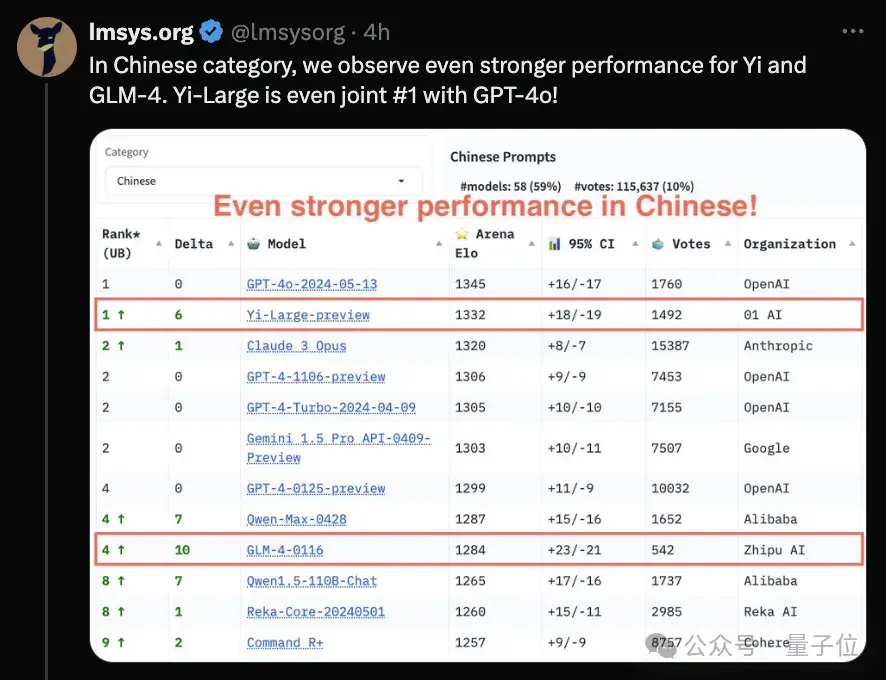
在中文類別中,Yi-Large和GLM-4兩個國產大模型的表現不俗。
其中,Yi-Large成績尤為突出,與GPT-4o并列總榜第一。
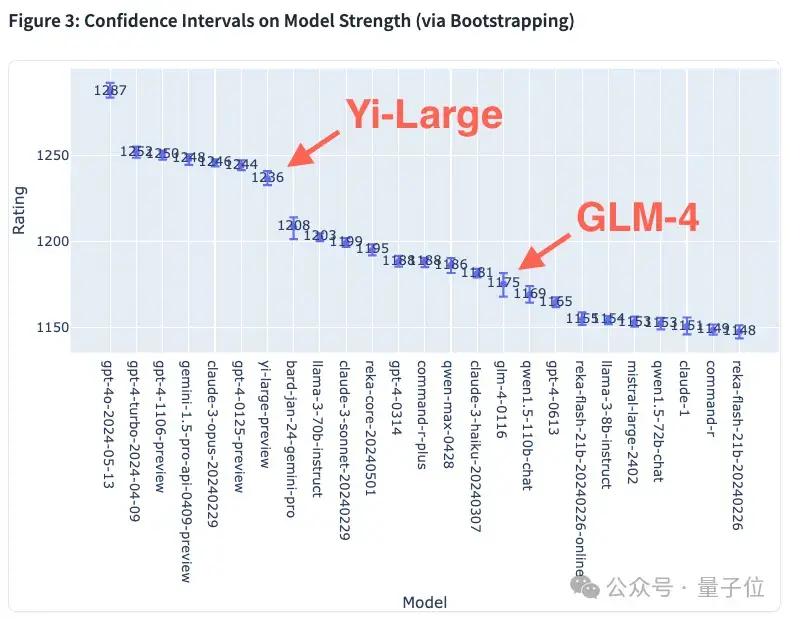
模型強度的置信區間,則如下圖所示:
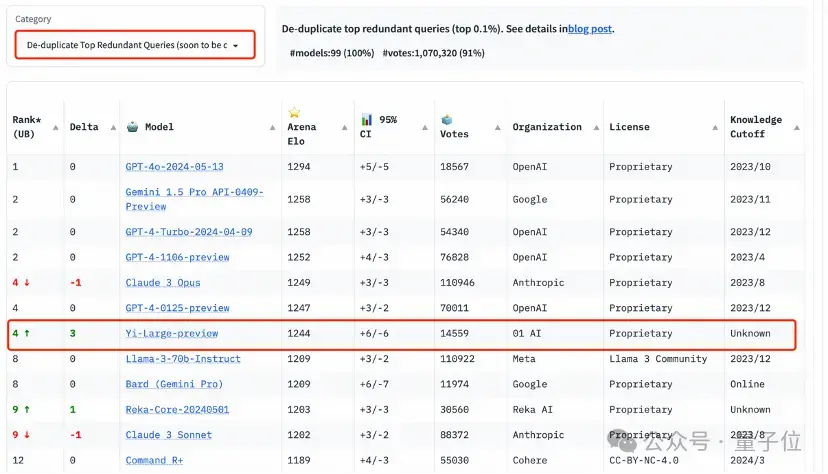
值得注意的是,為了提高大模型競技場查詢的整體質量,LMSYS還實施了重復數據刪除機制,并出具了去除冗余查詢后的榜單。
這個新機制旨在消除過度冗余的用戶提示——如過度重復的“你好”——這類冗余提示可能會影響排行榜的準確性。
LMSYS公開表示,去除冗余查詢后的榜單將在后續成為默認總榜。
目前,在去除冗余查詢后的總榜中,Yi-Large的Elo得分更進一步,與Claude 3 Opus、GPT-4-0125-preview并列第四。
解釋一下,Elo評分系統基于統計學原理設定,是當前國際公認的競技水平評估標準。在這個評分系統里,每個參賽者都有基準評分,然后根據每場比賽調整評分。一旦低分選手擊敗高分選手,那么低分選手就會獲得較多的分數,反之則較少。
LMSYS引入Elo評分系統,是為了保證大模型競技場在最大程度上保證排名的客觀公正。
而在分類別的排行榜中,Yi-Large同樣表現亮眼。
編程能力、長提問及最新推出的 “艱難提示詞” 的三個評測是LMSYS所給出的針對性榜單。這三個榜單以專業性與高難度著稱,可稱為當下大模型最燒腦的公開盲測。
在編程能力(Coding)排行榜上,Yi-Large 的Elo分數超過Anthropic當家旗艦模型Claude 3 Opus,僅低于GPT-4o,與GPT-4-Turbo、GPT-4并列第二。
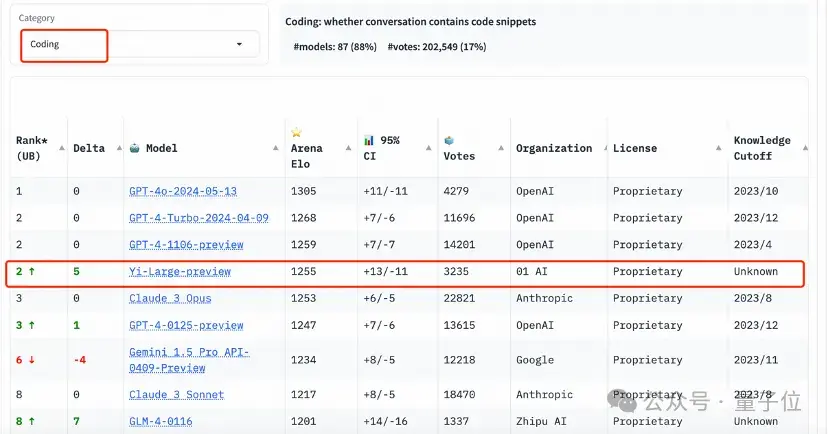
在長提問(Longer Query)榜單上,Yi-Large同樣位列全球第二,與GPT-4-Turbo、GPT-4、Claude 3 Opus并列。
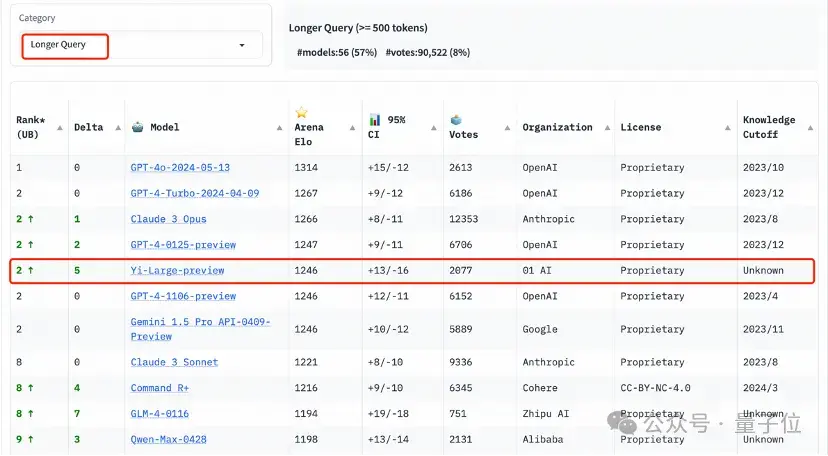
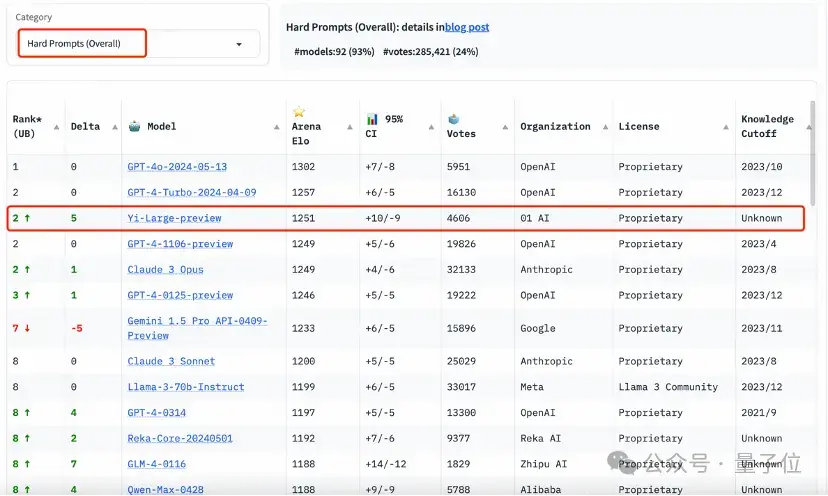
艱難提示詞(Hard Prompts)則是LMSYS響應社區要求,在今天的排行榜刷新中新增的類別。
這個類別的提示詞來自大模型競技場用戶提交的prompts,它們經過專門設計,更加復雜、要求更高且更加嚴格。
LMSYS增加這一類別榜單的原因,是官方認為這類提示能夠測試最新語言模型面臨挑戰性任務時的性能。
這個榜單上,Yi-Large處理艱難提示的能力與GPT-4-Turbo、GPT-4、Claude 3 Opus并列第二。
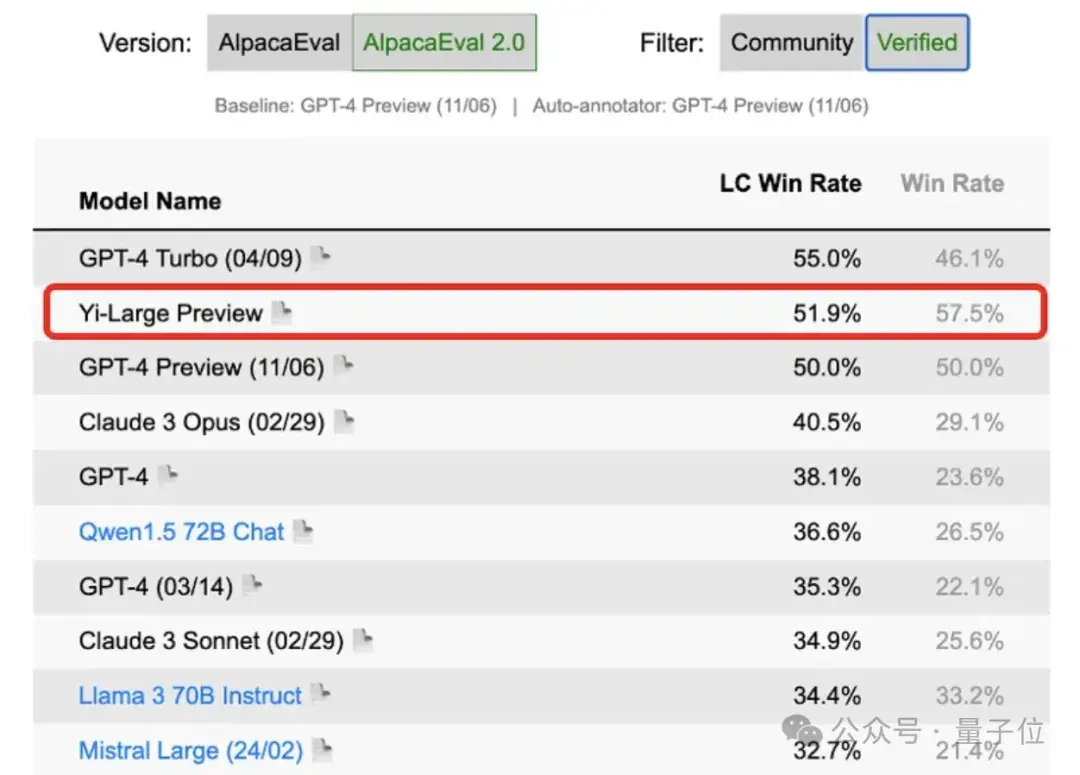
這次表現亮眼的Yi-Large,是一周前零一萬物剛對外發布的閉源模型。
當時官方給出的評測結果中,推理方面,Yi-Large在HumanEval和MATH都位列第一,超越GPT-4、Claude3 Sonnet、Gemini 1.5 Pro以及LLaMA3-70B-Instruct(都是時下大模型領域的佼佼者)。
據了解,Yi-Large的下一步是采用MoE架構的Yi-XLarge,目前已經啟動訓練。
大模型競技場
大模型競技場(Chatbot Arena),似乎已經成為現在頭部大模型的兵家必爭之地。
此前,國外如谷歌Bard、OpenAI的神秘大模型gpt2-chatbot(不是GPT-2)、Mistral AI的Mistral Large等模型都在上面沖鋒陷陣。
國內諸多玩家也都陸陸續續把自家孩子放進去考驗真功夫。
大神卡帕西去年就夸過大模型競技場很Awesome:
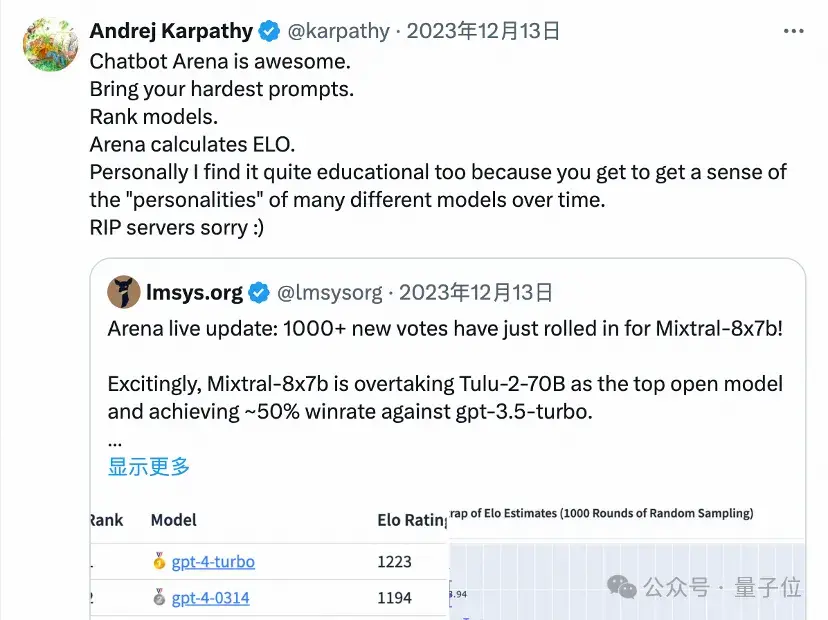
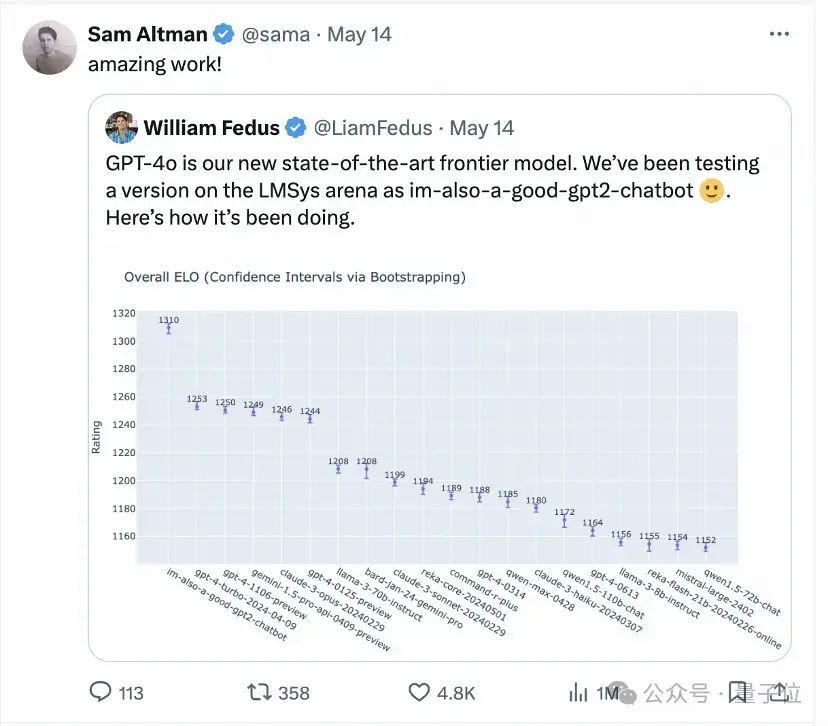
GPT-4o發布后,OpenAI的CEO奧特曼也轉帖引用大模型競技場盲測擂臺的測試結果,直呼鵝妹子嚶。
發布它的開放研究組織LMSYS Org(Large Model Systems Organization)發布,由加州大學伯克利分校的學生和教師、加州大學圣地亞哥分校、卡耐基梅隆大學合作創立。
雖然背后團隊主要來自高校,但LMSYS的研究項目卻相對更貼近產業。
他們不僅自己開發大語言模型,還向業內輸出多種數據集(其推出的MT-Bench已是指令遵循方向的權威評測集)、評估工具,此外還開發分布式系統以加速大模型訓練和推理,提供線上live大模型打擂臺測試所需的算力。

在形式上,大模型競技場借鑒了搜索引擎時代的橫向對比評測思路。
它首先將所有上傳評測的參賽模型隨機兩兩配對,以匿名模型的形式呈現在用戶面前。
在不知道模型型號名稱的前提下,用戶輸入自己的提示詞,模型A、模型B兩側分別生成兩PK模型的真實結果,然后由用戶在結果下方做出投票四選一:
A模型較佳/B模型較佳/兩者平手/兩者都不好。
提交投票后,可進行下一輪PK。
目前,大模型競技場的評測過程涵蓋了從用戶直接參與投票、盲測、大規模投票和動態更新評分機制等多個方面,盡可能保證結果的客觀和專業。
官方公開數據顯示,本次更新的大模型競技場,共有44款模型參賽。
既有開源高手,如Llama3-70B;也有全球各家大廠、創業公司的閉源模型。
最后,奉上一張勝率熱圖,它涵蓋了目前大模型競技場上的所有大模型:
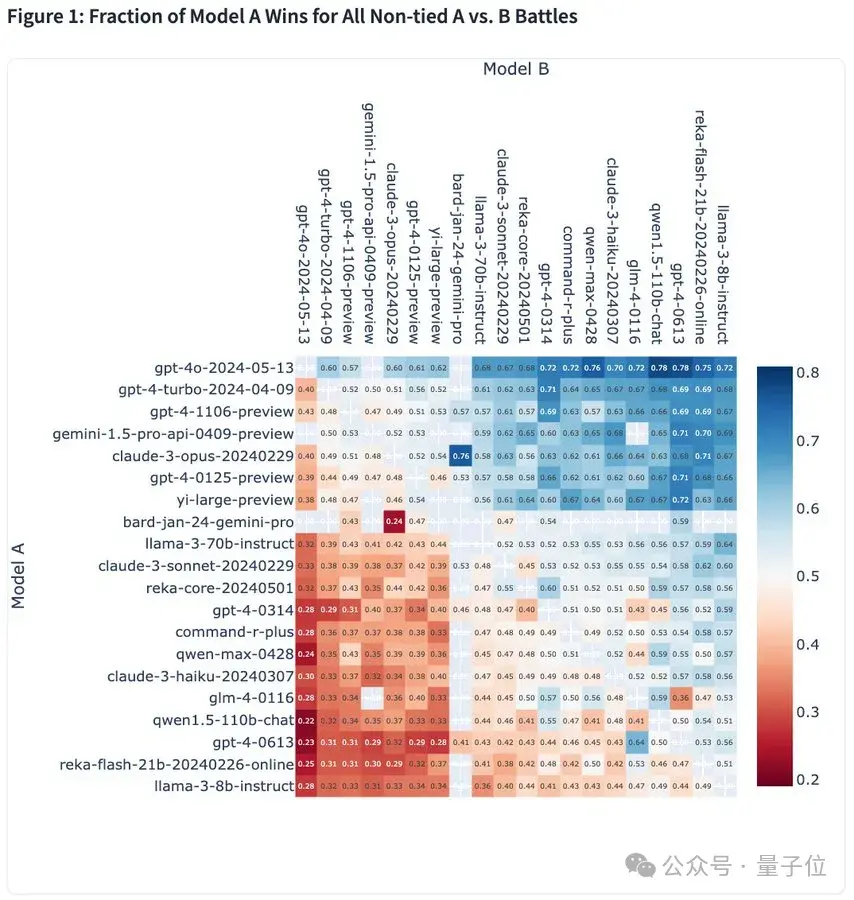
快來看看你pick的大模型勝率如何吧(手動狗頭)~
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
