

 新火種
2024-05-21
新火種
2024-05-21 


LoRA數學編程任務不敵全量微調|哥大&Databricks新研究
大數據巨頭Databricks與哥倫比亞大學最新研究發(fā)現,在數學和編程任務上,LoRA干不過全量微調。
具體來說,在這兩種任務中,LoRA模型的精確度只有后者的八到九成左右。
不過,作者也發(fā)現,LoRA雖然學得少,但是“記憶力”卻更好,遺忘現象要比全量微調少得多。
究其原因,作者認為是數學和代碼任務的特性與LoRA的低秩“八字不合”,遺忘更少也與秩相關。
但LoRA的一個公認的優(yōu)勢是訓練成本更低;而且相比全量微調,能夠更好地保持原有模型性能。
于是,網友們的看法也自然地分成了兩派:
一波人認為,單純考慮降低成本用LoRA,表現卻顯著降低,這是不可接受的。

更具針對性的,有人指出,對于數學和代碼這樣對精度要求高的任務,一定要最大程度地保證性能,哪怕犧牲一些訓練成本。
另一波機器學習工程師則認為,作者的一些實驗參數設置不當,造成這種現象的原因不一定是LoRA本身。
質疑的具體理由我們放到后面詳細講解,先來看看作者的研究都有哪些發(fā)現。
學的更少,但忘的也少
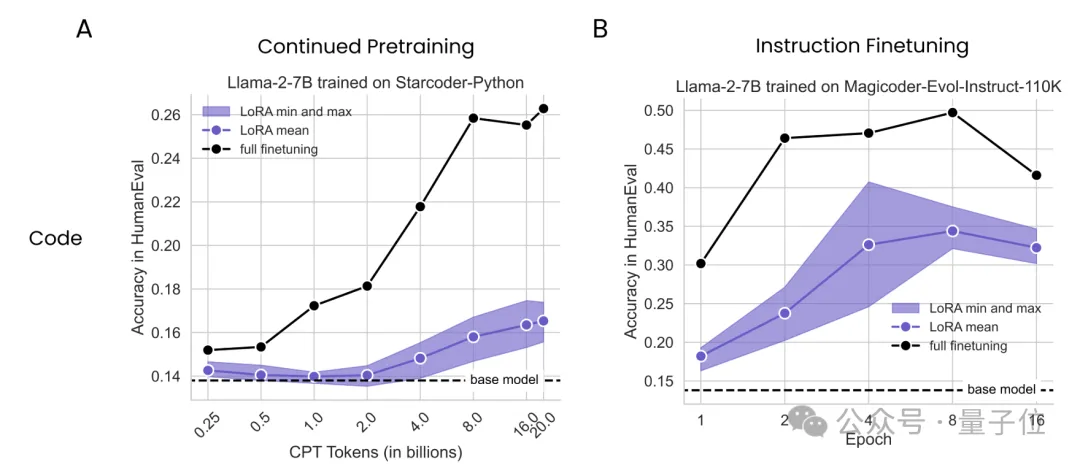
實驗中,作者使用7B參數的Llama2作為基礎模型,在持續(xù)預訓練和監(jiān)督微調兩種模式下分別應用LoRA和全量微調,并比較了它們的表現,使用的數據集如下表:

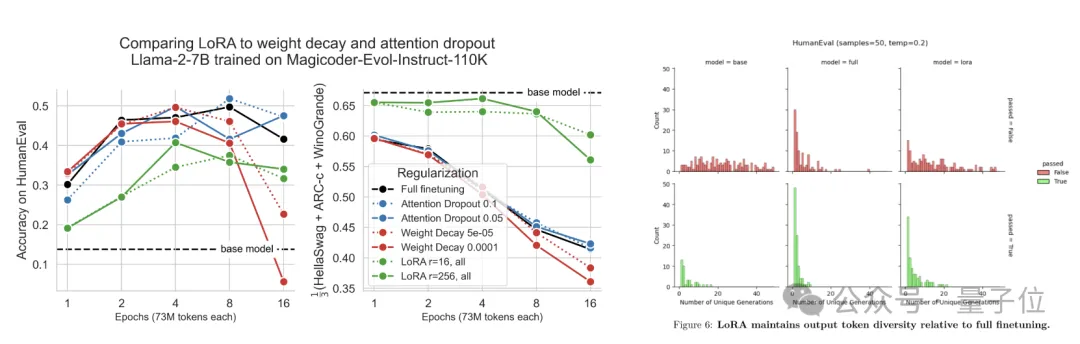
持續(xù)預訓練實驗中,作者在2.5-200億token之間共選擇了8個點進行了測試;監(jiān)督微調實驗則是在訓練1、2、4、8、16個epochs時取樣;LoRA的rank取值為16和256,適配對象包括Attention、MLP和All。
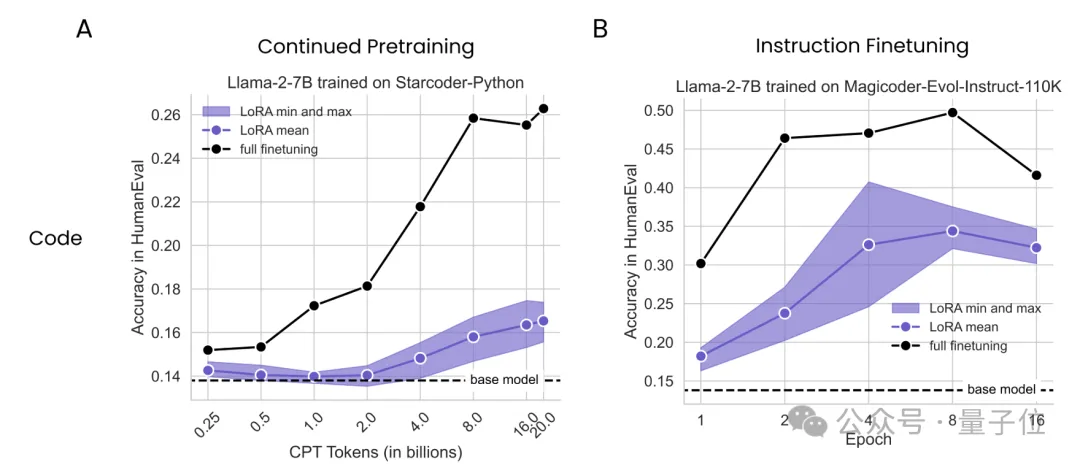
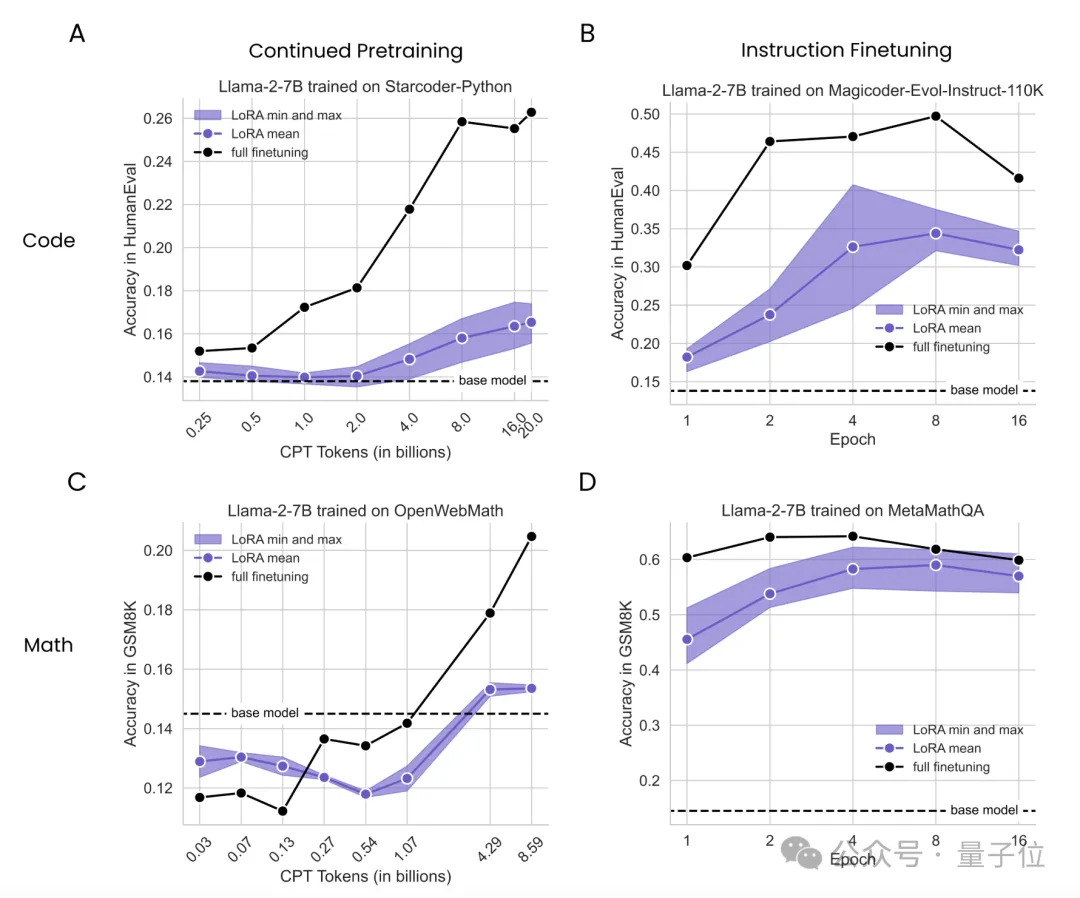
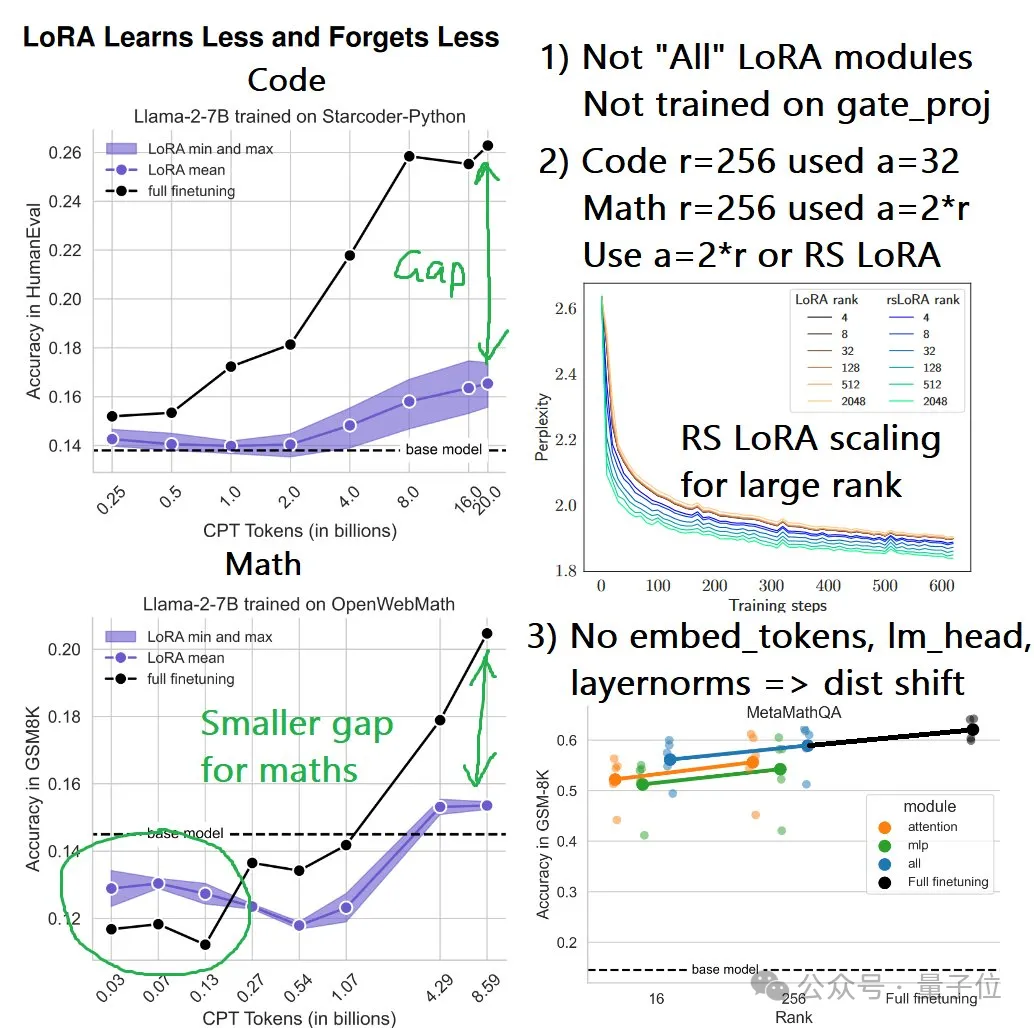
結果不難看出,無論是持續(xù)預訓練還是監(jiān)督微調,LoRA在編程上的表現從未追上過全量微調,而且在持續(xù)預訓練中,隨著token數量的增加,差距越來越懸殊。
而在數學任務上的持續(xù)預訓練實驗中,LoRA起初表現略勝于全量微調,但也是隨著token數量的增加,這種優(yōu)勢逐漸被反超。
這一系列結果表明,LoRA在讓模型學習新知識的工作中,表現不及全量微調。
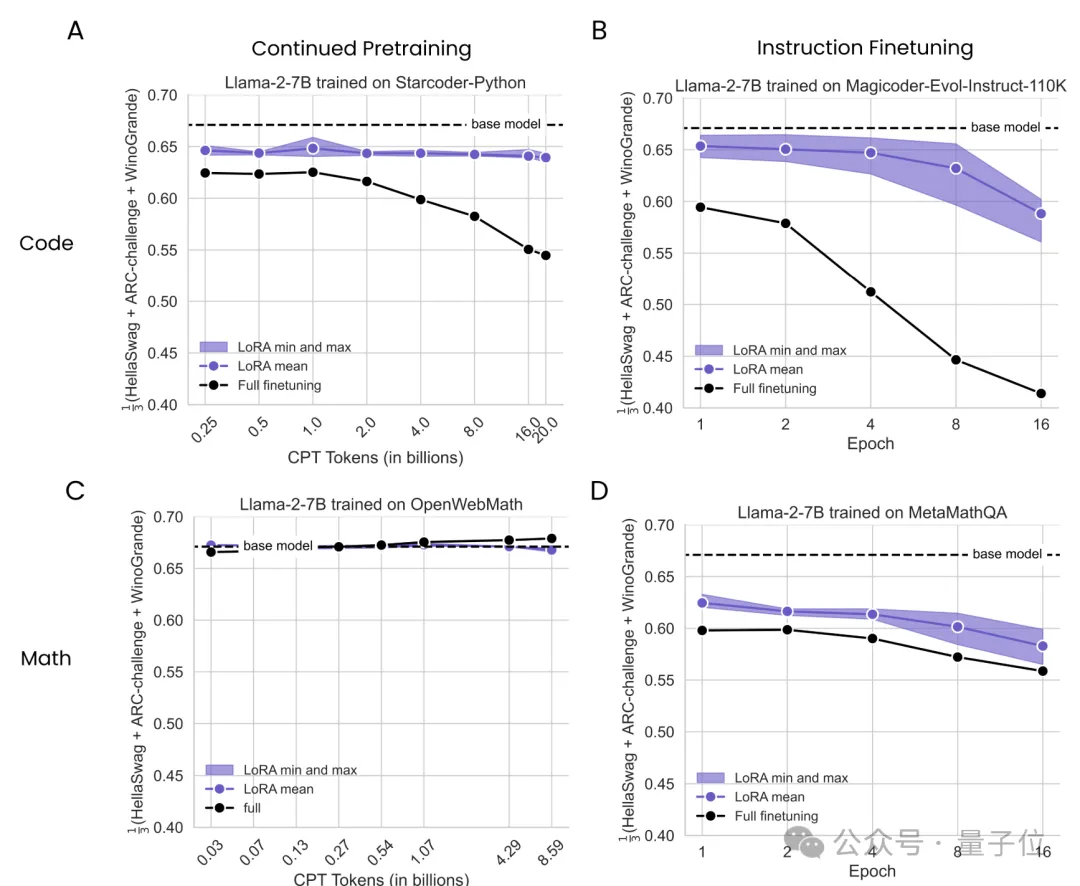
不過盡管在性能上比不過全量微調,但LoRA的遺忘現象更少,更有利于保持原有模型的能力。
換言之,如果把原始模型比作剛畢業(yè)的小學生,那么用LoRA能學到的初中知識更少,但之前的小學知識忘得也更少。
對應到應用當中,則主要在語言理解、嘗試推理等基礎能力中體現。
作者使用了相同的實驗配置,把測試數據集更換成了HellaSwag、ARC-Challenge和Winogrande,分別測試經過代碼和數學微調后的Llama2在基礎任務上的表現。
結果,用代碼來微調造成的“遺忘”現象更加嚴重,LoRA從整體上看更接近基礎模型,即遺忘現象更輕。
秩是模型表現關鍵
作者分析了這些現象背后的原因,結果發(fā)現,秩在其中扮演了重要的角色。
在線性代數中,一個矩陣的秩是指其線性無關的行或列的最大數量,秩越高,所能表示的變換或關系就越復雜。
同理,在深度學習中,模型的權重矩陣可以看作是將輸入信息轉換為輸出信息的一種映射關系,這些矩陣的秩反映了模型在學習時所需的自由度或復雜度。
對于LoRA來說,其學習的矩陣秩較小,對原始權重矩陣的影響也就越小,因此在適應新任務時更易保留原有知識。
而在作者的實驗中,低秩矩陣的特性還體現為了更強的正則化能力和生成多樣性。
至于為什么LoRA在學習新知識上表現不如全量微調,原因同樣和秩相關。
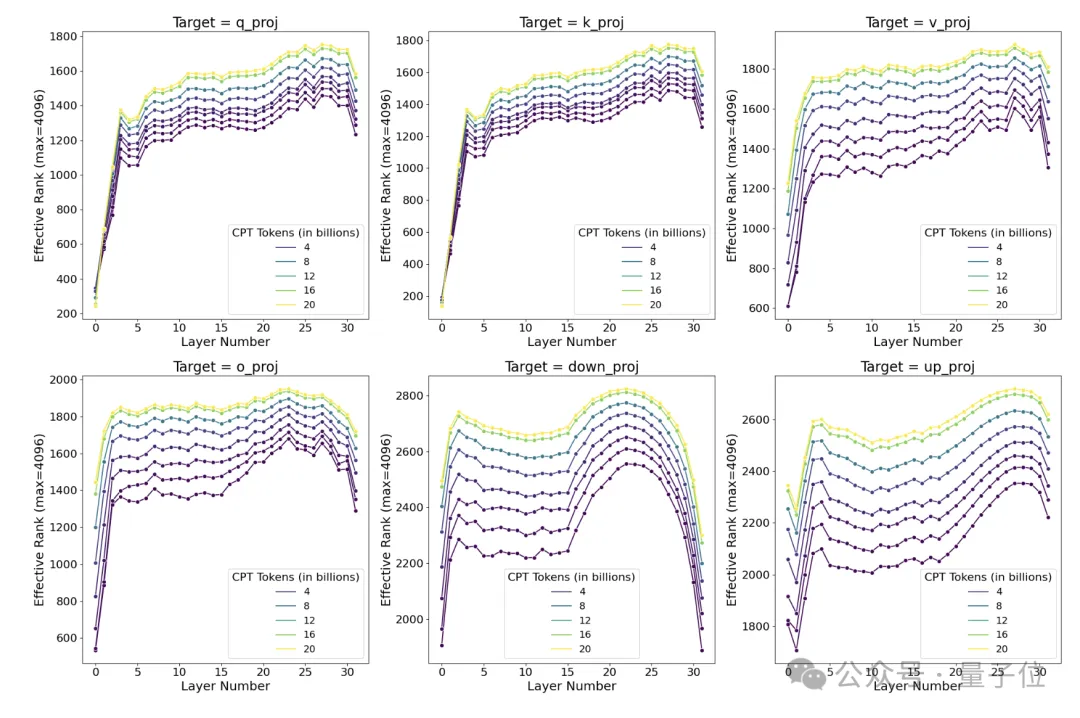
作者對在Llama2上用StarCoder-Python數據集進行持續(xù)預訓練過程中各個階段的權重矩陣進行了奇異值分解。
結果發(fā)現,即使在訓練的早期階段,全面微調學到的權重擾動矩陣的秩就是LoRA常用秩的10-100倍,這表明在編程任務上,全面微調需要學習高秩的權重擾動以適應目標領域;而且隨著訓練的進行,權重擾動矩陣的秩還會持續(xù)增長。
也就是說,此類任務的高秩需求,注定無法與LoRA的低秩特性相匹配,表現不佳也就不是什么意外之事了。
實驗中的另一個現象是,雖然同樣比不過全量微調,但數學任務中兩者的差距相比代碼任務更小,作者推測可能有兩方面原因:
首先還是和秩相關,作者認為數學任務相比于代碼更接近于預訓練數據,因此秩也相對更低。另一個原因,則是目前的GSM8K數據集可能挑戰(zhàn)性不夠,對模型考察不充分,這可能也是導致出現一開始LoRA超過全量微調的原因。ML工程師提出質疑
不過對作者的實驗,有人指出了實驗的參數設置存在不合理之處。
首先提出質疑的,是模型微調和訓練平臺UnslothAI創(chuàng)始人、前英偉達ML工程師Daniel Han。
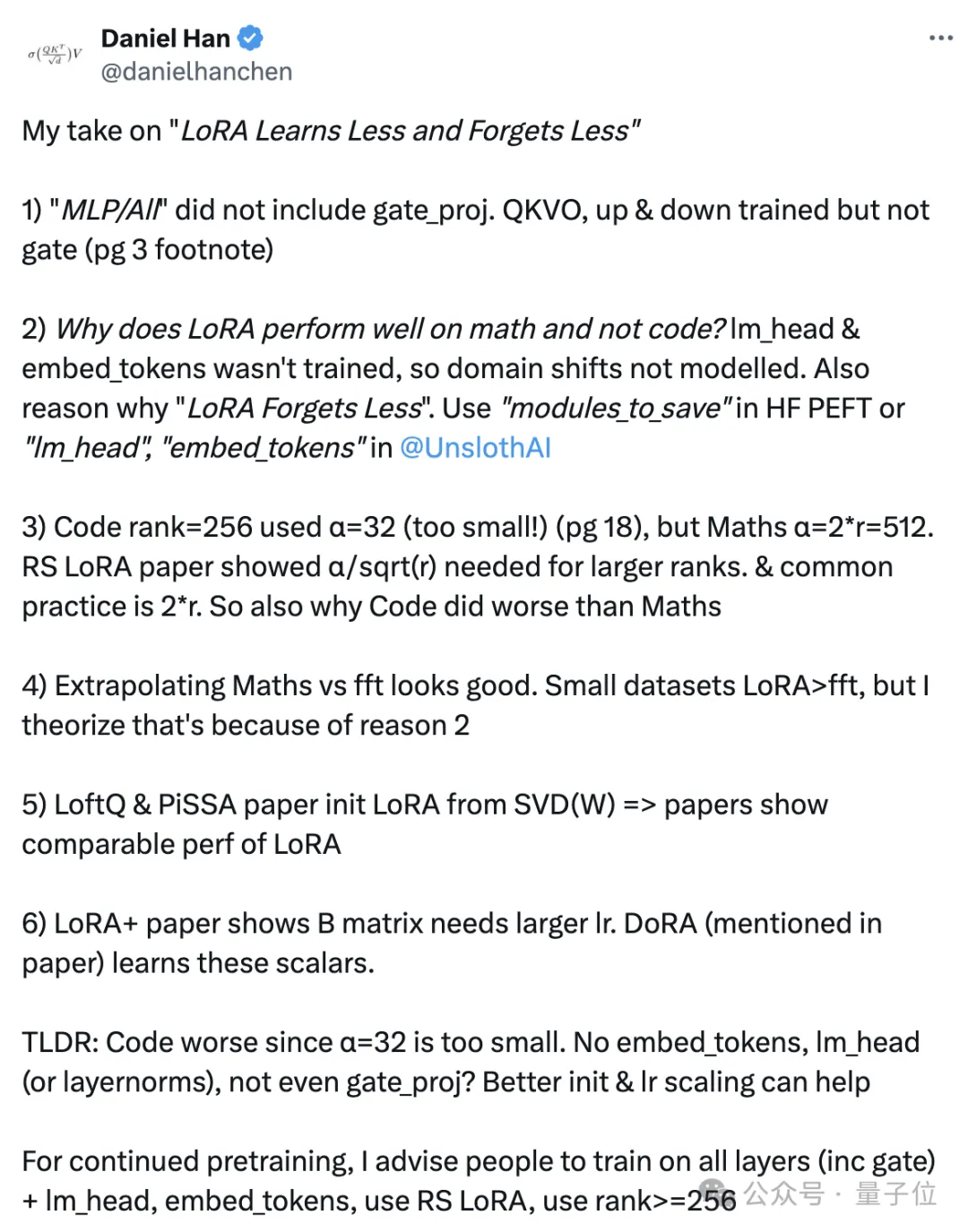
Daniel首先指出,論文中的LoRA實驗只適配了QKVO、up和down矩陣,沒有適配gate_proj矩陣。
如果LoRA沒有對gate_proj進行適配,那么FFN模塊的大部分權重實際上沒有被優(yōu)化,這可能限制了LoRA在編程任務上的表現。
至于數學能力好一些而在編程任務上表現不佳的原因,可能是lm_head和embed_tokens層沒有進行適配訓練,因此領域轉移沒有被很好地建模。
lm_head和embed_tokens層分別對應了語言模型的輸出和輸入嵌入,它們與具體領域的詞匯和表達密切相關。如果這兩個層沒有被LoRA適配,那么模型在新領域的詞匯和表達習慣上的適應能力就會受限。
另一方面,Daniel認為編程任務的超參數設置也有問題,比如秩為256時α值設得太小了,導致適配矩陣的值可能難以得到有效更新。
總結一下就是,LoRA在這些任務上的表現不如全量微調的原因,可能不是出在LoRA本身。
同時Daniel還表示,有論文指出LoftQ和PiSSA使用奇異值分解(SVD)來初始化LoRA矩陣,據稱可以使LoRA達到與全面微調相當的性能。
另一名ML工程師附和了Daniel的觀點,同時還針對LoRA的應用給出了一些具體建議:
LoRA更適用于監(jiān)督微調而不是持續(xù)預訓練對于LoRA來說,0.0005(代碼)或0.0002(數學)的學習率是最佳的應用LoRA時,優(yōu)先選擇同時適配MLP和Attention,其次單獨MLP,最后單獨Attention

總之,雖然出現了論文中的結果,但LoRA仍然是一項重要的技術,而且能夠顯著降低訓練成本,所以做好性能和資源的權衡,該用還是得用。
關于LoRA,你還有什么看法或經驗,歡迎評論區(qū)交流。
Tags:
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
