

 新火種
2024-03-08
新火種
2024-03-08 


StableDiffusion3技術報告出爐:揭露Sora同款架構細節(jié)
很快啊,“文生圖新王”Stable Diffusion 3的技術報告,這就來了。
全文一共28頁,誠意滿滿。

“老規(guī)矩”,宣傳海報(??)直接用模型生成,再秀一把文字渲染能力:

所以,SD3這比DALL·E 3和Midjourney v6都要強的文字以及指令跟隨技能,究竟怎么點亮的?
技術報告揭露:
全靠多模態(tài)擴散Transformer架構MMDiT。
成功關鍵是對圖像和文本表示使用單獨兩組權重的方式,由此實現(xiàn)了比SD3之前的版本都要強的性能飛升。
具體幾何,我們翻開報告來看。
微調DiT,提升文本渲染能力
在發(fā)布SD3之初,官方就已經透露它的架構和Sora同源,屬于擴散型Transformer——DiT。
現(xiàn)在答案揭曉:
由于文生圖模型需要考慮文本和圖像兩種模式,Stability AI比DiT更近一步,提出了新架構MMDiT。
這里的“MM”就是指“multimodal”。
和Stable Diffusion此前的版本一樣,官方用兩個預訓練模型來獲得合適和文本和圖像表示。
其中文本表示的編碼用三種不同的文本嵌入器(embedders)來搞定,包括兩個CLIP模型和一個T5模型。
圖像token的編碼則用一個改進的自動編碼器模型來完成。
由于文本和圖像的embedding在概念上完全不是一個東西,因此,SD3對這兩種模式使用了兩組獨立的權重。
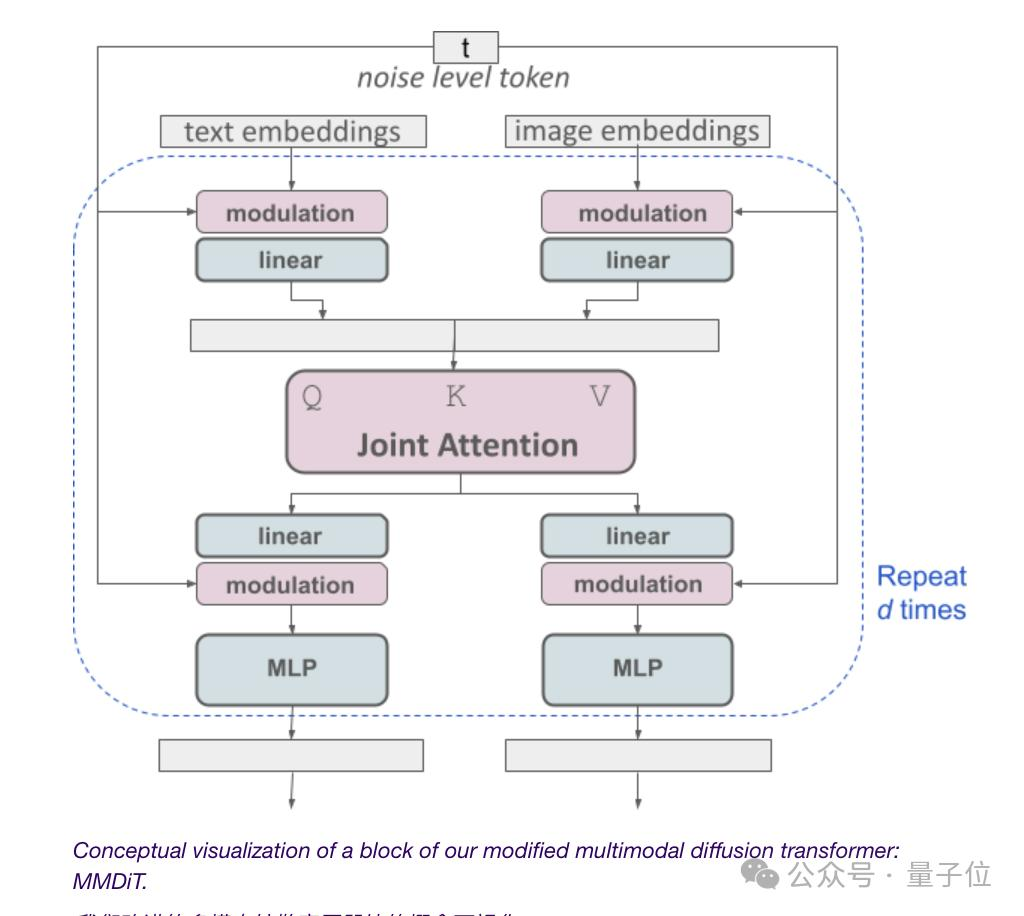
(有網友吐槽:這個架構圖好像要啟動“人類補完計劃”啊,嗯是的,有人就是“看到了《新世紀福音戰(zhàn)士》的資料才點進來這篇報告的”)
如上圖所示,這相當于每種模態(tài)都有兩個獨立的transformer,但是會將它們的序列連接起來進行注意力操作。
這樣,兩種表示都可以在自己的空間中工作,同時還能考慮到另一種。
最終,通過這種方法,信息就可以在圖像和文本token之間“流動”,在輸出時提高模型的整體理解能力和文字渲染能力。
并且正如之前的效果展示,這種架構還可以輕松擴展到視頻等多種模式。

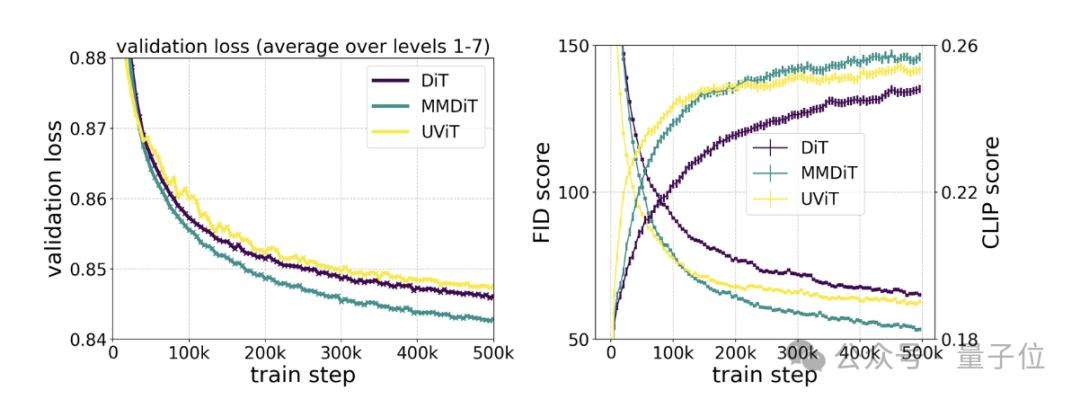
具體測試則顯示,MMDiT出于DiT卻勝于DiT:
它在訓練過程中的視覺保真度和文本對齊度都優(yōu)于現(xiàn)有的文本到圖像backbone,比如UViT、DiT。
重新加權流技術,不斷提升性能
在發(fā)布之初,除了擴散型Transformer架構,官方還透露SD3結合了flow matching。
什么“流”?
如今天發(fā)布的論文標題所揭露,SD3采用的正是“Rectified Flow”(RF)。

這是一個“極度簡化、一步生成”的擴散模型生成新方法,入選了ICLR2023。
它可以使模型的數(shù)據和噪聲在訓練期間以線性軌跡進行連接,產生更“直”的推理路徑,從而可以使用更少的步驟進行采樣。
基于RF,SD3在訓練過程中引入了一張全新的軌跡采樣。
它主打給軌跡的中間部分更多權重,因為作者假設這些部分會完成更具挑戰(zhàn)性的預測任務。
通過多個數(shù)據集、指標和采樣器配置,與其他60個擴散軌跡方法(比如LDM、EDM和ADM)測試這一生成方法發(fā)現(xiàn):
雖然以前的RF方法在少步采樣方案中表現(xiàn)出不錯的性能,但它們的相對性能隨著步數(shù)的增加而下降。
相比之下,SD3重新加權的RF變體可以不斷提高性能。
模型能力還可進一步提高
官方使用重新加權的RF方法和MMDiT架構對文本到圖像的生成進行了規(guī)模化研究(scaling study)。
訓練的模型范圍從15個具有4.5億參數(shù)的模塊到38個具有80億參數(shù)的模塊。
從中他們觀察到:隨著模型大小和訓練步驟的增加,驗證損失呈現(xiàn)出平滑的下降趨勢,即模型通過不斷學習適應了更為復雜的數(shù)據。
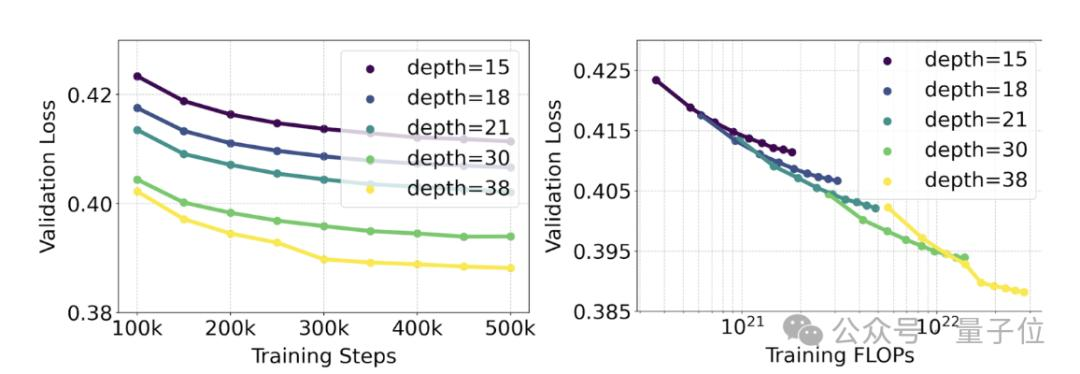
為了測試這是否在模型輸出上轉化為更有意義的改進,官方還評估了自動圖像對齊指標(GenEval)以及人類偏好評分(ELO)。
結果是:
兩者有很強的相關性。即驗證損失可以作為一個很有力的指標,預測整體模型表現(xiàn)。
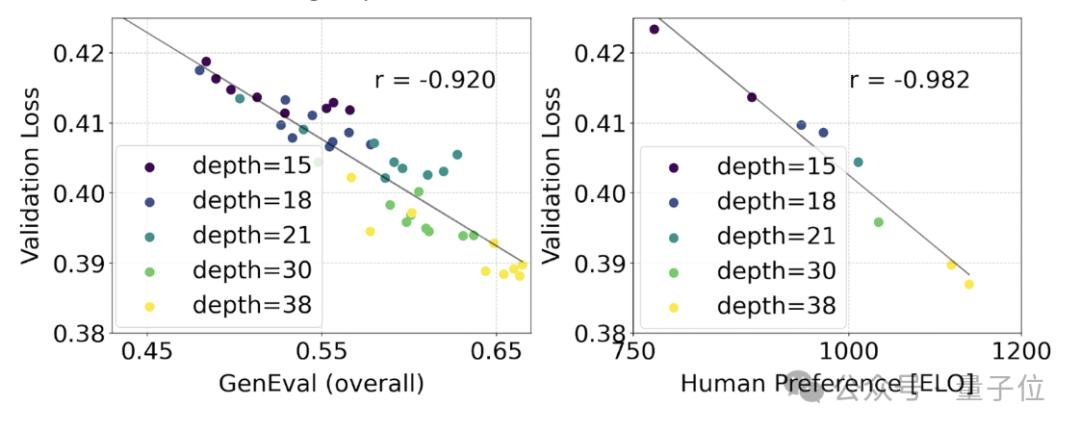
此外,由于這里的擴展趨勢沒有出現(xiàn)飽和跡象(即即隨著模型規(guī)模的增加,性能仍在提升,沒有達到極限),官方很樂觀地表示:
未來的SD3性能還能繼續(xù)提高。
最后,技術報告還提到了文本編碼器的問題:
通過移除用于推理的47億參數(shù)、內存密集型T5文本編碼器,SD3的內存需求可以顯著降低,但同時,性能損失很小(win rate從50%降到46%)。
不過,為了文字渲染能力,官方還是建議不要去掉T5,因為沒有它,文本表示的win rate將跌至38%。

那么總結一下就是說:SD3的3個文本編碼器中,T5在生成帶文本圖像(以及高度詳細的場景描述圖)時貢獻是最大的。
網友:開源承諾如期兌現(xiàn),感恩
SD3報告一出,不少網友就表示:Stability AI對開源的承諾如期而至很是欣慰,希望他們能夠繼續(xù)保持并長久運營下去。

還有人就差報OpenAI大名了:

更加值得欣慰的是,有人在評論區(qū)提到:
SD3模型的權重全部都可以下載,目前規(guī)劃的是8億參數(shù)、20億參數(shù)和80億參數(shù)。

速度怎么樣?
咳咳,技術報告有提:
80億的SD3在24GB的RTX 4090上需要34s才能生成1024*1024的圖像(采樣步驟50個)——不過這只是早期未經優(yōu)化的初步推理測試結果。
+1
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
