

 新火種
2024-03-06
新火種
2024-03-06 

北大具身智能成果入選CVPR’24:只需一張圖一個指令,就能讓大模型玩轉機械臂
只靠一張物體圖片,大語言模型就能控制機械臂完成各種日常物體操作嗎?
北大最新具身大模型研究成果ManipLLM將這一愿景變成了現實:
在提示詞的引導下,大語言模型在物體圖像上直接預測機械臂的操作點和方向。
進而,得以操控機械臂直接玩轉各項具體的任務:
例如打開抽屜、冰箱,揭鍋蓋、掀馬桶蓋……

作者表示:
該方法利用LLM的推理和面對開放世界的泛化能力,成功提升了模型在物體操縱方面的泛化能力。
在仿真和真實世界中,ManipLLM在各種類別的物體上均取得了令人滿意的效果,證明了其在多樣化類別物體中的可靠性和適用性。
與谷歌RT2等輸出機器人本體動作的策略相比(如下圖所示),該方法側重于以物體為中心(Object-centric)的操縱,關注物體本身,從而輸出機器人對物體操縱的位姿。

以物體為中心的操縱策略,設計針對物體本身特性的表征,與任務、動作、機器人型號無關。
這樣就可以將物體和任務及環境解耦開來,使得方法本身可以適應于各類任務、各類機器人,從而實現面對復雜世界的泛化。
目前,該工作已被CVPR 2024會議接收,團隊由北大助理教授、博導董豪領銜。

大模型如何直接操控機械臂?
大多的具身操縱工作主要依賴大語言模型的推理能力來進行任務編排和規劃。
然而,鮮有研究探索大語言模型在實現低層原子任務(low-level action)方面的潛力。
因此,該方法致力于探索和激發大語言模型在預測低層原子任務的能力,從而實現對更多類別物體的以物體為中心(object-centric)的通用操縱。
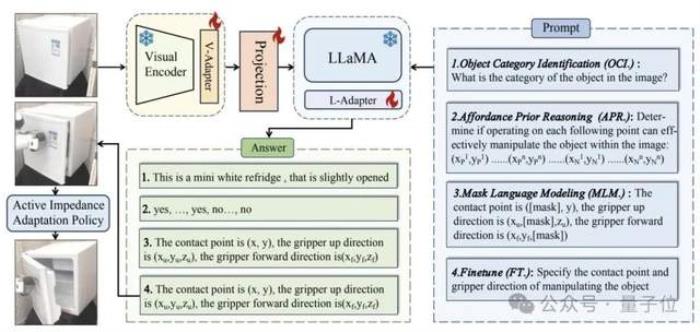
具體而言,通過以下三個學習階段,ManipLLM實現了具有泛化能力的以物體為中心的操縱:
1)類別級別(category-level):識別物體類別;
2)區域級別(region-level):預測物體的可操縱性分數(affordance score),反映哪些部位更可能被操縱;
3)位姿級別:預測操作物體的位姿。在訓練時,模型只更新適配器模塊(adapter),這樣既可以保有LLMs本身的能力,同時賦予其具身操縱的能力。
在獲得初始接觸姿態的輸出后,該方法利用一種無需學習的閉環主動式阻抗適應策略,來完成完整的操縱。
它的作用是不斷地微調末端執行器的旋轉方向,這樣就能夠靈活地適應物體的形狀和軸向,從而逐步地完成對物體的操控任務。
具體來說,我們會在當前方向的周圍加入一些微小的變化,生成多個可能的移動方向。
然后我們會試著每個方向輕輕地移動一下,看看哪個方向可以讓物體移動最遠,然后我們選擇這個方向作為下一步的移動方向。
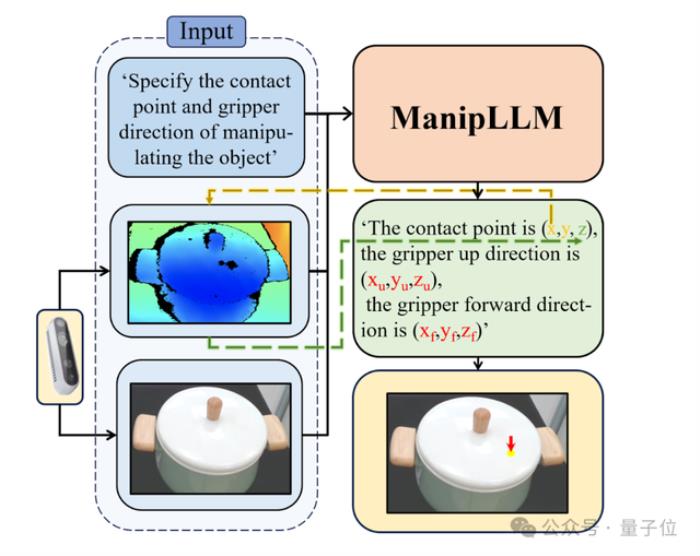
在推理階段,該模型只需輸入兩個信息:
1)文本提示:“請指出操縱物體的接觸點和夾爪方向。”(Specify the contact point and gripper direction of manipulating the object);
2)一張RGB圖片。然后,模型就能夠輸出物體操縱的2D坐標和旋轉信息。其中,2D坐標會通過深度圖映射到3D空間。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
