

 新火種
2024-01-05
新火種
2024-01-05 


大模型玩星際爭霸能秀到什么程度?有意識,有預判,中科院和汪軍團隊發(fā)布
全球最重要的電競賽事之一 DreamHack 剛剛落幕,來自世界各地的星際爭霸 II 頂尖選手們展開了激烈的較量。在這場緊張精彩的賽事中,人族選手 CLEM 憑借出色的戰(zhàn)術(shù)和操作,擊敗了世界冠軍 Dark,贏得了其生涯首個線下大賽冠軍。

在 AI 領(lǐng)域,DeepMind 的 AlphaStar 在 2019 年發(fā)表于《Nature》雜志,至今仍是 AI 研究的重要里程碑。AlphaStar 標志著 AI 技術(shù)在理解和處理復雜戰(zhàn)略任務(wù)方面的巨大進步。然而,它在長期戰(zhàn)略規(guī)劃和決策的可解釋性方面的局限性,也為研究者們提供了進一步的研究空間。正是看到了這些挑戰(zhàn)和機遇,中國科學院自動化研究所的群體決策智能實驗室與倫敦大學學院 (UCL) 的汪軍教授合作,將最近興起的 LLM Agent 技術(shù)應(yīng)用于星際爭霸 II 的 AI 研究。團隊通過 LLM 理解與分析能力來提高星際 AI 的長期戰(zhàn)略規(guī)劃與可解釋性決策。
為了提升 LLM 的長期戰(zhàn)略規(guī)劃能力,團隊設(shè)計了 TextStarCraft II 環(huán)境和 Chain of Summarization (CoS) 方法。CoS 方法能夠有效的提升 LLM 對復雜環(huán)境的理解能力,極大提高了 LLM 的戰(zhàn)略規(guī)劃和宏觀策略能力。該方法創(chuàng)造性的解決了 LLM 在長期戰(zhàn)略規(guī)劃和實時戰(zhàn)略決策方面存在的不足,讓 LLM agent 能夠在星際爭霸 II 這樣的復雜 RTS 游戲中做出長期策略規(guī)劃和實時策略調(diào)整,最終進行合理且具有可解性的決策。此外,團隊邀請了 30 位大師和宗師級選手(包括了星際爭霸 2 高校冠軍 TATP,ReWhite,Joliwaloves 等知名選手)對 GPT 等 LLM 在星際爭霸 II 的相關(guān)知識進行測評。最終 LLM agent 涌現(xiàn)出了超越 AlphaStar 的危險預測和兵種轉(zhuǎn)型能力,以及前期快攻,前期偵察,加速研發(fā)科技等類人策略。

TextStarCraft II:語言模型的新戰(zhàn)場面對星際爭霸 II 這一巨大挑戰(zhàn),團隊開發(fā)了 TextStarCraft II —— 一個全新的交互環(huán)境,它將星際爭霸 II 轉(zhuǎn)換成了一個文字游戲。這個環(huán)境基于 python-sc2 框架,將游戲中的狀態(tài)信息和動作空間巧妙地映射到文本空間。在這里,宏觀戰(zhàn)略動作被轉(zhuǎn)化為 LLM Agent 能夠理解并執(zhí)行的具體語義動作,大致包括生產(chǎn)單位,建造建筑和升級科技等。而微觀操作則交由一套固定的規(guī)則式方法處理。為了保證實驗最終的結(jié)果是得益于 LLM agent 的分析和決策能力,研究團隊將宏觀動作和微觀動作都設(shè)置為最簡單的情況,以避免過強的規(guī)則方法帶來的干擾。得益于 TextStarCraft II,LLM agent 能夠在這個全新的戰(zhàn)場上與游戲內(nèi)置的 Build-in AI 展開較量。同時借助 python-sc2,該方法能夠適配游戲的最新版本和地圖,實現(xiàn)星際爭霸 II AI 的靈活部署和高效應(yīng)用。Chain of Summarization:突破思維的界限
在星際爭霸 II 的戰(zhàn)場上,進行有效決策意味著需要及時處理大量復雜的信息,進行合理的戰(zhàn)略分析與長期規(guī)劃,最終制定宏觀戰(zhàn)略決策。這讓團隊面臨著巨大的挑戰(zhàn)。原有的 CoT (Chain of Thought) 及其改進方法,在 TextStarCraft II 環(huán)境中遭遇了三個主要問題:無法完全理解復雜的游戲信息,難以分析戰(zhàn)局的走向,以及不足以提出有用的策略建議。
針對這些挑戰(zhàn),團隊創(chuàng)新性地提出了 「Chain of Summarization」方法。這一方法分為兩大核心組成部分:單幀總結(jié)和多幀總結(jié)。單幀總結(jié)側(cè)重于信息的壓縮和提取,將觀測到的游戲信息轉(zhuǎn)化為簡潔而富含語義的結(jié)構(gòu)化數(shù)據(jù),從而便于 LLM 的理解和分析。而多幀總結(jié)則是受到計算機硬件緩存機制和強化學習中的跳幀技術(shù)的啟發(fā),通過同時處理多步觀測信息,彌補了快節(jié)奏的游戲和 LLM 推理速度之間的差異,提高了 LLM 在復雜環(huán)境中的理解和決策能力。
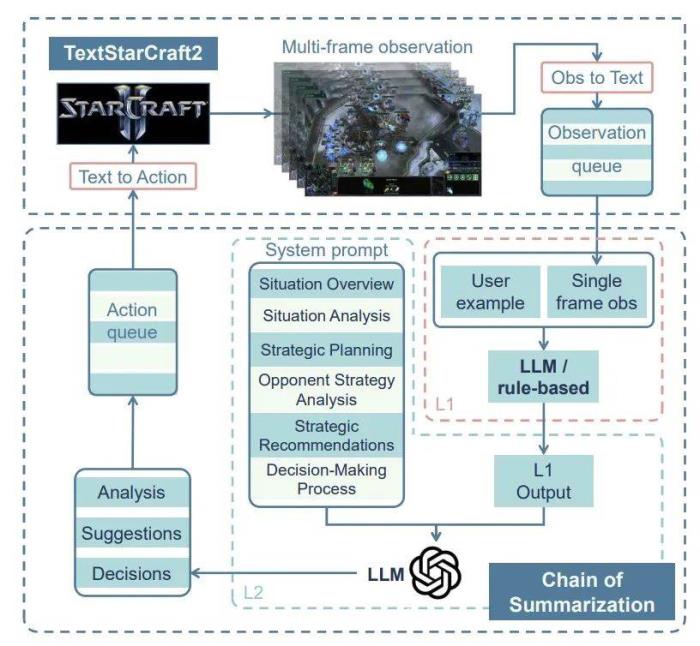 圖1:Chain of Summarization 框架。
圖1:Chain of Summarization 框架。
為了引導 LLM 進行高效的實時戰(zhàn)略決策,團隊精心設(shè)計了一套復雜的提示詞系統(tǒng) (prompt system)。這套系統(tǒng)包括四個主要部分:游戲狀態(tài)總結(jié),狀態(tài)分析,策略建議,以及最終決策。
通過這種方式,模型能夠全面理解游戲的當前局勢,分析敵我雙方的策略,并提出具有戰(zhàn)略深度的建議,最終做出多步的合理決策。這不僅極大地提高了 LLM 的實時決策能力和長期規(guī)劃能力,也極大提升了決策的可解釋性。在后續(xù)的實驗中,LLM agent 展示了前所未有的智能水平。
實驗結(jié)果Chain of Summarization 對交互速度的提升在驗證 Chain of Summarization 方法的有效性方面,團隊選擇了 GPT-3.5-turbo-16k 作為 LLM。實驗對比了應(yīng)用和未應(yīng)用該方法的兩種情況。結(jié)果表明:Chain of Summarization 不僅將 LLM 與游戲端的交互速度提升到了之前的十倍,還顯著增強了模型對游戲情境的理解及決策能力。

雖然 LLM agent 未能擊敗 Very Hard 的內(nèi)置 AI,但是該方法超越了采用同樣動作空間下的人類專家手動編寫的策略,能夠適應(yīng)更加復雜多變的戰(zhàn)場情況。類人策略的發(fā)現(xiàn)在實驗過程中,一個令人興奮的發(fā)現(xiàn)是 LLM Agent 展現(xiàn)出了許多與人類玩家類似的策略。這些策略包括前期偵察、前期快攻、加速升級科技和兵種轉(zhuǎn)型等。更為重要的是,團隊觀察到,在 Chain of Summarization 方法的幫助下,LLM Agent 能夠通過觀察、思考和決策來有效進行實時戰(zhàn)略規(guī)劃,實現(xiàn)了既具有可解釋性又符合長期規(guī)劃的決策。
1. 狂熱者快攻
2. 加速研發(fā)科技
3. 前期偵察
4. 加速生產(chǎn)工人
5. 防御與反擊
6. 偵測單位偵察
不同語言模型的表現(xiàn)
為了深入探究 LLM 在玩星際爭霸 II 中表現(xiàn)優(yōu)異的根本原因,團隊提出了一個假設(shè):這些 LLM 在其預訓練階段可能已經(jīng)學習到了關(guān)于星際爭霸 II 的相關(guān)知識。
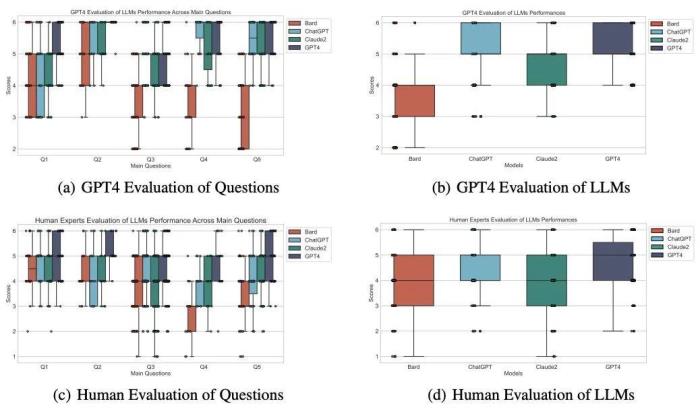
為驗證這一假設(shè),團隊設(shè)計了一系列問題,覆蓋星際爭霸 II 的基礎(chǔ)知識、種族機制、典型戰(zhàn)術(shù)、標準開局及戰(zhàn)術(shù)應(yīng)對等方面。這些問題的回答由人類專家(大師和宗師級選手)和 GPT-4 進行雙盲評分,以此評估不同模型對星際爭霸 II 知識的掌握程度。
實驗結(jié)果如下圖所示,其中揭示了一個有趣的現(xiàn)象:這些模型在不同程度上確實掌握了星際爭霸 II 的相關(guān)知識,其中 GPT-4 在理解和回答這些問題上表現(xiàn)尤為出色。這一發(fā)現(xiàn)不僅支持了團隊的假設(shè),也為理解 LLM agent 在復雜現(xiàn)實場景中的應(yīng)用提供了新的視角。
策略的可解釋性:LLM Agent 的戰(zhàn)略智慧在 AI 領(lǐng)域,即使是像 AlphaStar 這樣能擊敗人類職業(yè)選手的強大 AI,有時也會做出一些難以理解或解釋的決策。相比之下,盡管 LLM Agent 可能無法達到 AlphaStar 那樣精細的微操作水平,但其強大的邏輯思考能力使其能夠分析乃至預測游戲走向,并提供更合理的決策。這一能力主要體現(xiàn)在兩個方面:
1. 預測危險與建立防御:如左圖所示,AlphaStar(藍色蟲族)在對抗大師級玩家(紅色神族)時,未能及時建造防空建筑來應(yīng)對對手的騷擾,導致了重大損失。而在右圖中,LLM Agent(綠色神族)通過預判對手(紅色蟲族)的攻勢,及時建造了護盾電池,成功進行了防御。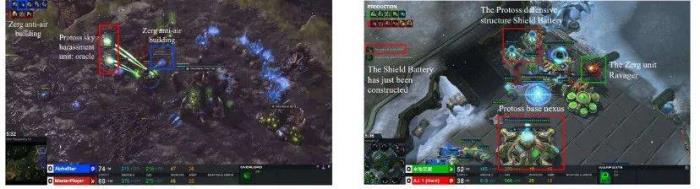 2. 戰(zhàn)場形勢下的兵種轉(zhuǎn)型:在另一場比賽中,AlphaStar(藍色蟲族)面對大師級玩家(紅色人族)的機械化部隊時,并未做出有效的兵種轉(zhuǎn)型,導致資源和人口的浪費(見左圖)。相對而言,LLM Agent(紅色神族)在面對敵方(藍色蟲族)時,不僅迅速生產(chǎn)出克制對手的部隊,還進一步研發(fā)了相關(guān)科技,實現(xiàn)了合理的部隊轉(zhuǎn)型和策略拓展(見右圖)。
2. 戰(zhàn)場形勢下的兵種轉(zhuǎn)型:在另一場比賽中,AlphaStar(藍色蟲族)面對大師級玩家(紅色人族)的機械化部隊時,并未做出有效的兵種轉(zhuǎn)型,導致資源和人口的浪費(見左圖)。相對而言,LLM Agent(紅色神族)在面對敵方(藍色蟲族)時,不僅迅速生產(chǎn)出克制對手的部隊,還進一步研發(fā)了相關(guān)科技,實現(xiàn)了合理的部隊轉(zhuǎn)型和策略拓展(見右圖)。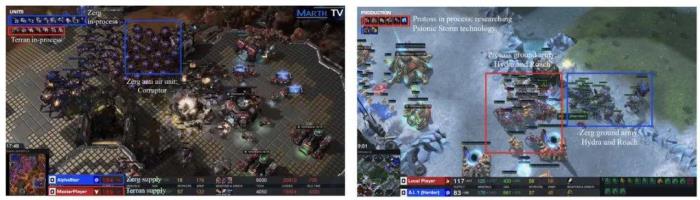
展望未來:LLM agent 的潛力與應(yīng)用
展望未來,團隊期待 TextStarCraft II 環(huán)境能夠成為評估 LLM 及 LLM Agent 能力的重要標準。此外,團隊認為未來將 LLM 與強化學習相結(jié)合,會產(chǎn)生更高級的策略和更佳的可解釋性,能夠解決星際爭霸 II 以及更復雜的決策場景。這種方法不僅有潛力超越 AlphaStar,還可能解決更加復雜和多變的決策問題,從而為 AI 在現(xiàn)實社會中的應(yīng)用開辟新的道路。相關(guān)推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
