

 新火種
2023-12-19
新火種
2023-12-19 

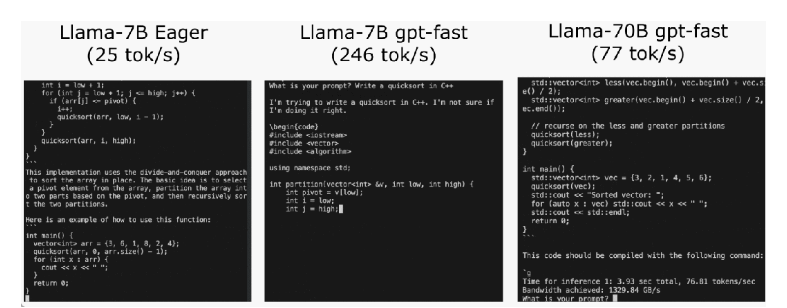

通過這些代碼,PyTorch團隊讓Llama7B提速10倍
要點:
PyTorch團隊通過優化技術,在不到1000行的純原生PyTorch代碼中將Llama7B的推理速度提升了10倍,達到了244.7tok/s。
優化方法包括使用PyTorch2.0的torch.compile函數、GPU量化、Speculative Decoding(猜測解碼)、張量并行等手段,以及使用不同精度的權重量化,如int8和int4。
通過組合以上技術,包括"compile + int4quant + speculative decoding"的組合,以及引入張量并行性,實現了在Llama-70B上達到近80tok/s的性能。
站長之家12月5日 消息:近期,PyTorch團隊在其博客中分享了一篇關于如何加速大型生成式AI模型推理的文章。該團隊以Llama7B為例,展示了如何通過一系列優化技術將推理速度提升10倍,達到了244.7tok/s。
推理性能的初始狀態,大模型推理性能為25.5tok/s,效果不佳。然后,通過PyTorch2.0引入的torch.compile函數,以及靜態KV緩存等手段,成功減少CPU開銷,實現了107.0TOK/S的推理速度。
為了進一步提高性能,團隊采用了GPU量化技術,通過減小運算精度來加速模型。特別是使用int8量化,性能提升了約50%,達到了157.4tok/s。
然而,仍然存在一個問題,即為了生成100個token,必須加載權重100次。為解決這個問題,團隊引入了Speculative Decoding,通過生成一個“draft”模型預測大模型的輸出,成功打破了串行依賴,進一步提升了性能。
使用int4量化和GPTQ方法進一步減小權重,以及將所有優化技術組合在一起,最終實現了244.7tok/s的推理速度。
為了進一步減少延遲,文章提到了張量并行性,通過在多個GPU上運行模型,進一步提高了性能,特別是在Llama-70B上達到了近80tok/s。
PyTorch團隊通過一系列創新性的優化手段,不僅成功提升了大模型的推理速度,而且以不到1000行的純原生PyTorch代碼展示了這一技術的實現過程。
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
