

 新火種
2023-12-20
新火種
2023-12-20 


如何優(yōu)雅地用TensorFlow預(yù)測時間序列:TFTS庫詳細(xì)教程
作者:何之源轉(zhuǎn)載自知乎專欄:AI Insight量子位 已獲授權(quán)編輯發(fā)布
這篇文章中,作者詳細(xì)介紹了TensorFlow Time Series(TFTS)庫的使用方法。主要包含數(shù)據(jù)讀入、AR模型的訓(xùn)練、LSTM模型的訓(xùn)練三部分內(nèi)容。內(nèi)容翔實有趣,量子位轉(zhuǎn)載分享給大家。前言如何用TensorFlow結(jié)合LSTM來做時間序列預(yù)測其實是一個很老的話題,然而卻一直沒有得到比較好的解決。如果在Github上搜索“tensorflow time series”,會發(fā)現(xiàn)star數(shù)最高的tgjeon/TensorFlow-Tutorials-for-Time-Series已經(jīng)和TF 1.0版本不兼容了,并且其他的項目使用的方法也各有不同,比較混亂。
在剛剛發(fā)布的TensorFlow 1.3版本中,引入了一個TensorFlow Time Series模塊(以下簡稱為TFTS)。TFTS專門設(shè)計了一套針對時間序列預(yù)測問題的API,目前提供AR、Anomaly Mixture AR、LSTM三種預(yù)測模型。由于是剛剛發(fā)布的庫,文檔還是比較缺乏的,我通過研究源碼,大體搞清楚了這個庫的設(shè)計邏輯和使用方法,這篇文章是一篇教程帖,會詳細(xì)的介紹TFTS庫的以下幾個功能:讀入時間序列數(shù)據(jù)(分為從numpy數(shù)組和csv文件兩種方式)用AR模型對時間序列進(jìn)行預(yù)測用LSTM模型對時間序列進(jìn)行預(yù)測(包含單變量和多變量)先上效果圖,使用AR模型預(yù)測的效果如下圖所示,藍(lán)色線是訓(xùn)練數(shù)據(jù),綠色為模型擬合數(shù)據(jù),紅色線為預(yù)測值:

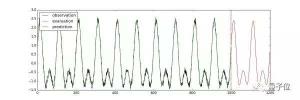
使用LSTM進(jìn)行單變量時間序列預(yù)測:
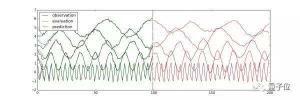
使用LSTM進(jìn)行多變量時間序列預(yù)測(每一條線代表一個變量):
文中涉及的所有代碼已經(jīng)保存在Github上了,以下提到的所有代碼和文件都是相對于這個項目的根目錄來說的。時間序列問題的一般形式一般地,時間序列數(shù)據(jù)可以看做由兩部分組成:觀察的時間點和觀察到的值。以商品價格為例,某年一月的價格為120元,二月的價格為130元,三月的價格為135元,四月的價格為132元。那么觀察的時間點可以看做是1,2,3,4,而在各時間點上觀察到的數(shù)據(jù)的值為120,130,135,132。從Numpy數(shù)組中讀入時間序列數(shù)據(jù)如何將這樣的時間序列數(shù)據(jù)讀入進(jìn)來?TFTS庫中提供了兩個方便的讀取器NumpyReader和CSVReader。前者用于從Numpy數(shù)組中讀入數(shù)據(jù),后者則可以從CSV文件中讀取數(shù)據(jù)。我們利用np.sin,生成一個實驗用的時間序列數(shù)據(jù),這個時間序列數(shù)據(jù)實際上就是在正弦曲線上加上了上升的趨勢和一些隨機的噪聲:
我們利用np.sin,生成一個實驗用的時間序列數(shù)據(jù),這個時間序列數(shù)據(jù)實際上就是在正弦曲線上加上了上升的趨勢和一些隨機的噪聲:如圖:
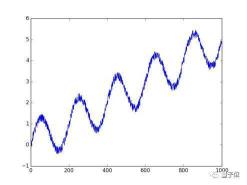
橫坐標(biāo)對應(yīng)變量“x”,縱坐標(biāo)對應(yīng)變量“y”,它們就是我們之前提到過的“觀察的時間點”以及“觀察到的值”。TFTS讀入x和y的方式非常簡單,請看下面的代碼:
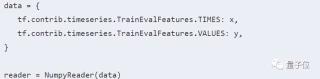
我們首先把x和y變成python中的詞典(變量data)。變量data中的鍵值tf.contrib.timeseries.TrainEvalFeatures.TIMES實際就是一個字符串“times”,而tf.contrib.timeseries.TrainEvalFeatures.VALUES就是字符串”values”。所以上面的定義直接寫成“data = {‘times’:x, ‘values’:y}”也是可以的。寫成比較復(fù)雜的形式是為了和源碼中的寫法保持一致。得到的reader有一個read_full()方法,它的返回值就是時間序列對應(yīng)的Tensor,我們可以用下面的代碼試驗一下:
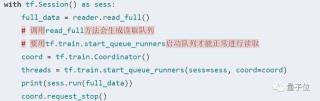
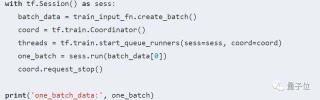
不能直接使用sess.run(reader.read_full())來從reader中取出所有數(shù)據(jù)。原因在于read_full()方法會產(chǎn)生讀取隊列,而隊列的線程此時還沒啟動,我們需要使用tf.train.start_queue_runners啟動隊列,才能使用sess.run()來獲取值。我們在訓(xùn)練時,通常不會使用整個數(shù)據(jù)集進(jìn)行訓(xùn)練,而是采用batch的形式。從reader出發(fā),建立batch數(shù)據(jù)的方法也很簡單:tf.contrib.timeseries.RandomWindowInputFn會在reader的所有數(shù)據(jù)中,隨機選取窗口長度為window_size的序列,并包裝成batch_size大小的batch數(shù)據(jù)。換句話說,一個batch內(nèi)共有batch_size個序列,每個序列的長度為window_size。以batch_size=2, window_size=10為例,我們可以打出一個batch內(nèi)的數(shù)據(jù):
從CSV文件中讀入時間序列數(shù)據(jù)有的時候,時間序列數(shù)據(jù)是存在CSV文件中的。我們當(dāng)然可以將其先讀入為Numpy數(shù)組,再使用之前的方法處理。更方便的做法是使用tf.contrib.timeseries.CSVReader讀入。項目中提供了一個test_input_csv.py代碼,示例如何將文件./data/period_trend.csv中的時間序列讀入進(jìn)來。假設(shè)CSV文件的時間序列數(shù)據(jù)形式為:

CSV文件的第一列為時間點,第二列為該時間點上觀察到的值。將其讀入的方法為:

從reader建立batch數(shù)據(jù)形成train_input_fn的方法和之前完全一樣。下面我們就利用這個train_input_fn來訓(xùn)練模型。使用AR模型預(yù)測時間序列自回歸模型(Autoregressive model,可以簡稱為AR模型)是統(tǒng)計學(xué)上處理時間序列模型的基本方法之一。在TFTS中,已經(jīng)實現(xiàn)了一個自回歸模型。使用AR模型訓(xùn)練、驗證并進(jìn)行時間序列預(yù)測的示例程序為train_array.py。Examples/blob/master/train_array.py先建立一個train_input_fn:

針對這個序列,對應(yīng)的AR模型的定義就是:

這里的幾個參數(shù)比較重要,分別給出解釋。第一個參數(shù)periodicities表示序列的規(guī)律性周期。我們在定義數(shù)據(jù)時使用的語句是:“y = np.sin(np.pi * x / 100) + x / 200. + noise”,因此周期為200。input_window_size表示模型每次輸入的值,output_window_size表示模型每次輸出的值。input_window_size和output_window_size加起來必須等于train_input_fn中總的window_size。在這里,我們總的window_size為40,input_window_size為30,output_window_size為10,也就是說,一個batch內(nèi)每個序列的長度為40,其中前30個數(shù)被當(dāng)作模型的輸入值,后面10個數(shù)為這些輸入對應(yīng)的目標(biāo)輸出值。最后一個參數(shù)loss指定采取哪一種損失,一共有兩種損失可以選擇,分別是NORMAL_LIKELIHOOD_LOSS和SQUARED_LOSS。num_features參數(shù)表示在一個時間點上觀察到的數(shù)的維度。
我們這里每一步都是一個單獨的值,所以num_features=1。除了程序中出現(xiàn)的幾個參數(shù)外,還有一個比較重要的參數(shù)是model_dir。它表示模型訓(xùn)練好后保存的地址,如果不指定的話,就會隨機分配一個臨時地址。使用變量ar的train方法可以直接進(jìn)行訓(xùn)練:TFTS中驗證(evaluation)的含義是:使用訓(xùn)練好的模型在原先的訓(xùn)練集上進(jìn)行計算,由此我們可以觀察到模型的擬合效果,對應(yīng)的程序段是:如果要理解這里的邏輯,首先要理解之前定義的AR模型:它每次都接收一個長度為30的輸入觀測序列,并輸出長度為10的預(yù)測序列。整個訓(xùn)練集是一個長度為1000的序列,前30個數(shù)首先被當(dāng)作“初始觀測序列”輸入到模型中,由此就可以計算出下面10步的預(yù)測值。接著又會取30個數(shù)進(jìn)行預(yù)測,這30個數(shù)中有10個數(shù)就是前一步的預(yù)測值,新得到的預(yù)測值又會變成下一步的輸入,以此類推。最終我們得到970個預(yù)測值(970=1000-30,因為前30個數(shù)是沒辦法進(jìn)行預(yù)測的)。這970個預(yù)測值就被記錄在evaluation[‘mean’]中。evaluation還有其他幾個鍵值,如evaluation[‘loss’]表示總的損失,evaluation[‘times’]表示evaluation[‘mean’]對應(yīng)的時間點等等。evaluation[‘start_tuple’]會被用于之后的預(yù)測中,它相當(dāng)于最后30步的輸出值和對應(yīng)的時間點。以此為起點,我們可以對1000步以后的值進(jìn)行預(yù)測,對應(yīng)的代碼為:

這里的代碼在1000步之后又像后預(yù)測了250個時間點。對應(yīng)的值就保存在predictions[‘mean’]中。我們可以把觀測到的值、模型擬合的值、預(yù)測值用下面的代碼畫出來:畫好的圖片會被保存為“predict_result.jpg”
使用LSTM預(yù)測單變量時間序列注意:以下LSTM模型的例子必須使用TensorFlow最新的開發(fā)版的源碼。具體來說,要保證“from tensorflow.contrib.timeseries.python.timeseries.estimators import TimeSeriesRegressor”可以成功執(zhí)行。給出兩個用LSTM預(yù)測時間序列模型的例子,分別是train_lstm.py和train_lstm_multivariate.py。前者是在LSTM中進(jìn)行單變量的時間序列預(yù)測,后者是使用LSTM進(jìn)行多變量時間序列預(yù)測。為了使用LSTM模型,我們需要先使用TFTS庫對其進(jìn)行定義,定義模型的代碼來源于TFTS的示例源碼,在train_lstm.py和train_lstm_multivariate.py中分別拷貝了一份。我們同樣用函數(shù)加噪聲的方法生成一個模擬的時間序列數(shù)據(jù):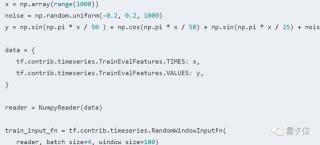
此處y對x的函數(shù)關(guān)系比之前復(fù)雜,因此更適合用LSTM這樣的模型找出其中的規(guī)律。得到y(tǒng)和x后,使用NumpyReader讀入為Tensor形式,接著用tf.contrib.timeseries.RandomWindowInputFn將其變?yōu)閎atch訓(xùn)練數(shù)據(jù)。一個batch中有4個隨機選取的序列,每個序列的長度為100。接下來我們定義一個LSTM模型:

num_features = 1表示單變量時間序列,即每個時間點上觀察到的量只是一個單獨的數(shù)值。num_units=128表示使用隱層為128大小的LSTM模型。訓(xùn)練、驗證和預(yù)測的方法都和之前類似。在訓(xùn)練時,我們在已有的1000步的觀察量的基礎(chǔ)上向后預(yù)測200步:
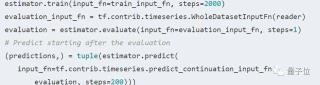
將驗證、預(yù)測的結(jié)果取出并畫成示意圖,畫出的圖像會保存成“predict_result.jpg”文件:
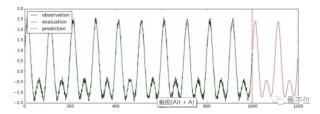
使用LSTM預(yù)測多變量時間序列所謂多變量時間序列,就是指在每個時間點上的觀測量有多個值。在data/multivariate_periods.csv文件中,保存了一個多變量時間序列的數(shù)據(jù):
這個CSV文件的第一列是觀察時間點,除此之外,每一行還有5個數(shù),表示在這個時間點上的觀察到的數(shù)據(jù)。換句話說,時間序列上每一步都是一個5維的向量。使用TFTS讀入該CSV文件的方法為:
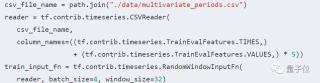
與之前的讀入相比,唯一的區(qū)別就是column_names參數(shù)。它告訴TFTS在CSV文件中,哪些列表示時間,哪些列表示觀測量。接下來定義LSTM模型:

區(qū)別在于使用num_features=5而不是1,原因在于我們在每個時間點上的觀測量是一個5維向量。訓(xùn)練、驗證、預(yù)測以及畫圖的代碼與之前比較類似,可以參考代碼train_lstm_multivariate.py,此處直接給出最后的運行結(jié)果:
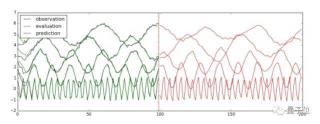
圖中前100步是訓(xùn)練數(shù)據(jù),一條線就代表觀測量在一個維度上的取值。100步之后為預(yù)測值。總結(jié)這篇文章詳細(xì)介紹了TensorFlow Time Series(TFTS)庫的使用方法。主要包含三個部分:數(shù)據(jù)讀入、AR模型的訓(xùn)練、LSTM模型的訓(xùn)練。文章里使用的所有代碼都保存在Github上了。如果覺得有幫助,歡迎點贊或star~~~— 完
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
