

 新火種
2023-12-20
新火種
2023-12-20 


AMD的下一代GPU是3D集成的超級芯片:MI300將13塊硅片組合為一個芯片

編輯 | 白菜葉
AMD 在近日的 AMD Advancing AI 活動中揭開了其下一代 AI 加速器芯片 Instinct MI300 的面紗,這是前所未有的 3D 集成壯舉。MI300 將為 El Capitan 超級計算機提供動力,它是一個集計算、內存和通信于一體的夾層蛋糕,有三片硅片高,可以在這些硅平面之間垂直傳輸多達 17 TB 的數據。它可以使某些機器學習關鍵計算的速度提高 3.4 倍。該芯片與 Nvidia 的 Grace-Hopper 超級芯片和英特爾的超級計算機加速器 Ponte Vecchio 等競品既有不同又有相似之處。
MI300a 在四個輸入輸出芯片 (IOD) 之上堆疊了三個 CPU 小芯片(用 AMD 的行話稱為計算復雜芯片或 CCD)和六個加速器小芯片 (XCD),所有這些都位于一塊硅片之上,硅片將它們連接到圍繞超級芯片的八個高帶寬 DRAM 堆棧。(MI300x 將 CCD 替換為另外兩個 XCD,構成僅加速器系統。)隨著硅平面上晶體管尺寸縮小的速度放緩,3D 堆疊被視為將更多晶體管放入同一區域并繼續推動摩爾定律向前發展的關鍵方法。
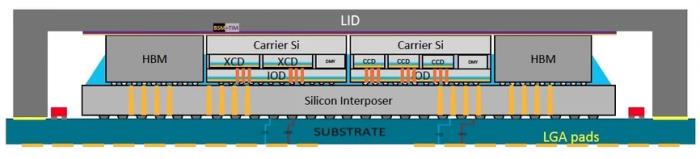
「這是一個真正令人驚嘆的硅堆疊,可提供業界目前已知如何生產的最高密度性能。」AMD 高級副總裁兼企業研究員 Sam Naffziger 說道。該集成是使用兩種臺積電技術完成的:SoIC(集成芯片系統)和 CoWoS(基板上晶圓芯片)。后者使用所謂的混合鍵合將較小的芯片堆疊在較大的芯片之上,這種混合鍵合直接連接每個芯片上的銅焊盤,無需焊接。它用于生產 AMD 的 V-Cache,這是一種堆疊在其最高端 CPU 小芯片上的高速緩存內存擴展小芯片。前者稱為 CoWos,將小芯片堆疊在稱為中介層的較大硅片上,該硅片旨在包含高密度互連。
AMD 和 Nvidia 之間的異同
與主要競爭對手英偉達的做法既有相似之處,也有不同之處。正如 Nvidia 在其 Hopper 架構中所做的那樣,AMD 的加速器架構 CDNA3 增加了使用稱為 TF32 的截斷 32 位數字和兩種不同形式的 8 位浮點數的計算能力。后一個屬性用于加速 transformer 神經網絡某些部分的訓練,例如大型語言模型。它們還都包含一種減小神經網絡大小的方案,稱為 4:2 稀疏性。
另一個相似之處是 CPU 和 GPU 都包含在同一個封裝中。在許多人工智能計算機系統中,GPU 和 CPU 是單獨封裝的芯片,以 4 比 1 的比例部署。將它們集成在單個超級芯片中的一個優點是,CPU 和 GPU 都可以高帶寬訪問相同的緩存和高帶寬 DRAM (HBM),并且在讀寫數據時不會互相干擾。
Nvidia 的 Grace-Hopper 就是這樣一個超級芯片組合,通過 Nvidia 的 Nvidia NVLink Chip-2-Chip 互連將 Grace CPU 與 Hopper GPU 連接起來。AMD 的 MI300a 也是如此,通過使用 AMD Infinity Fabric 互連技術集成了專為其 Genoa 系列設計的三個 CPU 芯片和六個 XCD 加速器。
但粗略地看一下 Grace Hopper 和 MI300,就會發現一些深刻的差異。Grace 和 Hopper 都是獨立的芯片,集成了片上系統所需的所有功能塊(計算、I/O 和緩存)。它們是水平連接的,而且很大——幾乎達到了光刻技術的尺寸極限。
AMD 采取了不同的方法,它在幾代 CPU 中都采用了這種方法,競爭對手英特爾在其 3D 堆棧超級計算機加速器 Ponte Vecchio 中也采用了這種方法。這個概念被稱為系統技術協同優化(STCO)。這意味著,設計人員首先將芯片分解為其功能,然后決定哪些功能需要哪種制造技術。
「我們想要使用 MI300 進行擴展,超越單個單片 GPU 的能力。因此,我們將其解構為碎片,然后將其重新構建起來,」Instinct 的高級研究員兼首席架構師 Alan Smith 說道。盡管已經在多代 CPU 中這樣做,但 MI300 是該公司首次制造 GPU 小芯片并將它們綁定在單個系統中。
「將 GPU 分解為小芯片使我們能夠將計算置于最先進的工藝節點中,同時將芯片的其余部分保留在更適合緩存和 I/O 的技術中。」他說。就 MI300 而言,所有計算都是使用臺積電的 N5 工藝構建的,這是最先進的工藝,用于 Nvidia 的頂級 GPU。I/O 功能和系統緩存都無法從 N5 中受益,因此 AMD 為此選擇了一種較便宜的技術 (N6)。因此,這兩個功能可以一起構建在同一個小芯片上。
隨著功能的分解,MI300 中涉及的所有硅片都變得很小。最大的 I/O 芯片甚至還不到 Hopper 的一半大小。而且 CCD 的尺寸僅為 I/O 芯片的 1/5 左右。小尺寸帶來很大差異。一般來說,芯片越小產量越好。也就是說,單個晶圓將提供比大芯片更高比例的工作小芯片。「3D 集成不是免費的。」Naffziger 說。但他表示,更高的產量抵消了成本。
Luck and experience
Naffziger 表示,該設計涉及對現有技術和設計的巧妙重用、一些妥協以及一點運氣。重用有兩種情況。
首先,AMD 能夠充滿信心地進行 3D 集成,因為它已在其 V 緩存產品中使用了完全相同的垂直互連間距(9 微米)。作為 AMD 能夠收取額外費用的可選附加組件,V-cache 很少有良率不佳或其他問題對公司產生重大影響的風險。「這讓我們能夠在不危及主要產品線的情況下解決制造問題和 3D 堆疊的所有設計復雜性,這是一件很棒的事情,」Naffziger 說道。
另一個重用的例子就有點冒險了。當 MI300 團隊決定需要 CPU/GPU 組合時,Naffziger 「有些不好意思」地詢問為 Genoa CPU 設計 Zen4 CCD 的團隊負責人,是否可以制作出適合 MI300 需求的 CCD。
該團隊面臨著比預期更早完成任務的壓力,但一天后他們做出了回應。Naffziger 很幸運;Zen4 CCD 在正確的位置有一個小的空白空間,可以在不破壞整體設計的情況下與 MI300 I/O 芯片及其相關電路進行垂直連接。
盡管如此,仍然有一些幾何問題需要解決。為了使所有內部通信正常工作,四個 I/O 小芯片必須在特定邊緣上相互面對。這意味著制作小芯片的鏡像版本。由于它是與 I/O 小芯片共同設計的,因此 XCD 的垂直連接旨在與兩個版本的 I/O 連接。但 CCD 沒有受到任何干擾,他們很幸運能夠擁有 CCD。因此,I/O 被設計為具有冗余連接,這樣無論它位于哪個版本的小芯片上,CCD 都會連接。

圖示:為了讓一切都對齊,IOD 小芯片需要制作為彼此的鏡像,并且加速器 (XCD) 和計算 (CCD) 小芯片必須旋轉。(來源:AMD)
Naffziger 指出,電網必須向堆棧頂部的計算芯片提供數百安培的電流,也面臨著類似的挑戰,因為它也必須適應所有不同的小芯片方向。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
