

 新火種
2023-12-17
新火種
2023-12-17 


南農(nóng)大團(tuán)隊研發(fā)“古籍版ChatGPT”,為何取名“荀子”
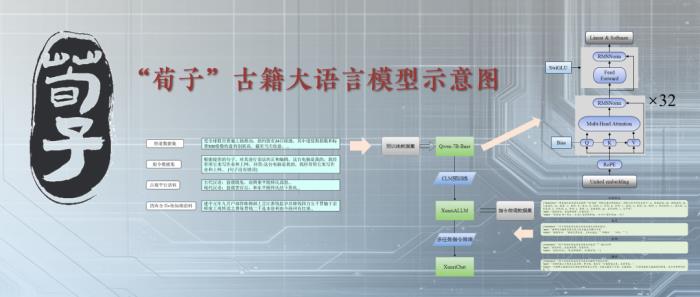
“荀子”古籍大語言模型示意圖 微信公眾號@南農(nóng)信管之窗CIM 圖
澎湃新聞12月11日從南京農(nóng)業(yè)大學(xué)獲悉,該校信息管理學(xué)院王東波團(tuán)隊日前研發(fā)出國內(nèi)首個專門用于古籍處理與研究的智能工具——“荀子”古籍大語言模型,包含《四庫全書》在內(nèi)的古籍文獻(xiàn)超20億字大型語料庫,具備自然語言理解、自動翻譯、自動標(biāo)引等功能。該模型已在GitHub、ModelScope等網(wǎng)站開源。
王東波表示,荀子不僅是先秦偉大的樸素唯物主義思想家和散文家,對語言學(xué)理論的闡述也是開拓者,如此命名是紀(jì)念這位語言學(xué)先驅(qū),“普通受眾要走近繁體、豎版、沒有句讀的古文不是容易的事,‘荀子’上線,意味著在智媒時代與古籍對話成為可能,古文閱讀理解、標(biāo)點添加、譯為現(xiàn)代漢語——這些難啃的‘硬骨頭’,‘荀子’可以輕松拿下。”專家則可借助“荀子”完成古籍詞法分析、實體識別、關(guān)系抽取、文本分類與匹配、文本摘要等。
據(jù)介紹,“荀子”的問世離不開高性能算力基礎(chǔ)設(shè)施,也離不開團(tuán)隊長期積累精加工語料庫,投喂了40億字的混合語料數(shù)據(jù)。“模型的構(gòu)建受算力、場景應(yīng)用等影響,但精準(zhǔn)度高的優(yōu)質(zhì)數(shù)據(jù)是關(guān)鍵。”王東波說,團(tuán)隊2008年接觸古籍,2013年至今一直專注于人工精標(biāo)注數(shù)據(jù)工作,“比如《岳陽樓記》,要訓(xùn)練機(jī)器標(biāo)注其中的形容詞,先要訓(xùn)練相關(guān)人員標(biāo)注形容詞,在大量人工標(biāo)注的基礎(chǔ)上讓機(jī)器學(xué)習(xí)”。
王東波表示,期待通過“荀子”大語言模型,將古籍的智能化研究與跨學(xué)科人才培養(yǎng)結(jié)合,讓學(xué)生既有前瞻的科研視野,又積累較深厚的人文底蘊,同時讓更多受眾接觸、品讀、傳播古籍,喚活“故紙堆”。
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
