

 新火種
2023-12-07
新火種
2023-12-07 


顛覆Transformer霸權!Mamba新架構,解決致命bug推理速度暴增5倍
編輯:編輯部【新智元導讀】誕生6周年的Transformer,霸主之位終于要被顛覆了?CMU、普林斯頓研究者發布的Mamba,解決了Transformer核心注意力層無法擴展的致命bug,推理速度直接飆升了5倍!一個時代要結束了?












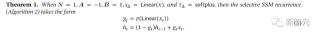




深度學習進入新紀元,Transformer的霸主地位,要被掀翻了?
2017年6月12日橫空出世,讓NLP直接變天,制霸自然語言領域多年的Transformer,終于要被新的架構打破壟斷了。
Transformer雖強大,卻有一個致命的bug:核心注意力層無法擴展到長期上下文。
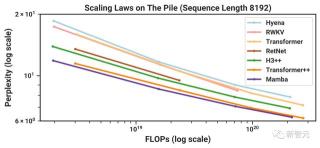
剛剛,CMU和普林斯頓的研究者發布了Mamba。這種SSM架構在語言建模上與Transformers不相上下,而且還能線性擴展,同時具有5倍的推理吞吐量!
論文一作Albert Gu表示,二次注意力對于信息密集型模型是必不可少的,但現在,再也不需要了!
論文一出,直接炸翻了AI社區。
英偉達高級科學家Jim Fan表示,自己一直期待能有人來推翻Transformer,并且對Albert Gu和Tri Dao多年以來做出替代Transformer序列架構的嘗試表示感謝。
「你們做的研究太酷了,一會兒蹦出一個來,不能稍微停一下嗎!」
「湖人粉表示,對Mamba這個名字很滿意!」
對于這個架構為何取名曼巴,作者也給出了解釋——
- 速度快:原因在于(1)序列長度線性縮放的簡單遞歸,(2)硬件感知設計和實現
- 致命性:它對序列建模問題具有致命的吸引力
- 就連發出的「聲音」都很像:其核心機制是結構化狀態空間序列模型(S4)的最新演進……SSSS
性能碾壓Transformer?
Mamba源自Albert Gu之前「結構化狀態空間模型」的相關工作,可以看作是強大的循環運算符。這就得以實現序列長度的線性縮放和快速自回歸解碼。
然而,以前的遞歸模型的缺點是,它們的固定大小狀態難以壓縮上下文。
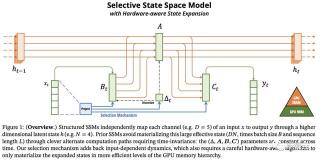
而Mamba的主要貢獻,就是引入了「選擇性SSM」,這是S4的簡單泛化,可以選擇性地關注或忽略輸入。
這一小小的改變——只需讓某些參數成為輸入的函數——就能讓它立即解決對以往模型來說艱巨無比的任務。
例如,它可以無限長地推斷出重要的「聯想回憶」任務的解決方案!(訓練長度256,測試長度1M)
關鍵就在于:這一變化涉及到非同小可的效率權衡,S4的原始設計有著特定的原因。
在DNA和音頻等其他模態的真實數據上,Mamba的預訓練性能超過了之前的專業基線(如HyenaDNA和SaShiMi)。
值得注意的是,無論在合成、DNA還是音頻數據中,隨著序列長度達到1M+,Mamba的性能也在不斷提高!
而另一位一作Tri Dao介紹了如何利用硬件感知設計應對這一挑戰,以及Mamba在語言方面的強大性能。
他表示,正如Albert所說,狀態空間模型(SSM)的特征,就是其固定大小的遞歸狀態。如果想實現更好的性能,就要求這種狀態更大,并且更具表現力。
不幸的是,因為較大的狀態太慢,會導致無法在實踐中使用遞歸進行計算。
過去,曾有基于S4的SSM通過做出結構假設(也即線性時間不變性)來解決這個問題,這樣就可以在不實現大狀態的情況下,進行等效的「卷積模式」計算。
但這次CMU和普林斯頓研究者的方法是選擇性SSM,只能循環計算。
為了解決這個計算瓶頸,他們利用了其他高效的硬件感知算法(如FlashAttention)使用的技術。
需要注意的是,對于Mamba(和一般的SSM),這種方法只能在SRAM中實現擴展狀態,而不是在主存儲器中。
此外,scan實現比基本的PyTorch/JAX快30倍,當序列長度變長時,比二次FlashAttention還要快幾個數量級。
而且,由于采用了固定大小的循環狀態(沒有KV緩存),Mamba的LM推理速度比Transformer快5倍。
從經驗上看,兩位作者取得的最重要的成果是在語言建模上,這也是以前的SSM所瞄準的領域(比如H3,也即Mamba的前身)。
然而這時,自己的工作仍然不及Transformer。并且他表示,當時沒有哪個模型能真正與精調后的Transformer相抗衡。
然而,驚喜忽然來了!
根據Chinchilla縮放定律進行預訓練時,Mamba的表現忽然就優于一個非常強大的現代「Transformer++」模型(接近Llama模型)!
而在300B token上訓練完成后,Mamba的性能,已經大大優于同類的開源模型。
最后,作者總結道:硬件感知思維可以開啟新的架構設計。
展望未來,這種新架構能否利用圍繞Transformers構建的硬件/庫?它將如何改變其他領域(基因組學、音頻、視頻)的序列擴展?
為此,作者還發布了一系列模型的權重(參數量最高可達2.8B,在300B token上訓練),以及快速推理代碼。
擊敗Transformer的架構,是怎樣誕生的
現在的基礎模型,幾乎都是基于Transformer架構和其中最核心的注意力模塊來構建的。
為了解決Transformer在處理長序列時的計算低效問題,學界開發了很多二次方時間復雜度的架構,比如線性注意力、門控卷積和循環模型,以及結構化狀態空間模型(SSM)。
然而,這些架構在處理語言時,表現并不如傳統的注意力模型。
研究人員發現,這些模型的主要弱點在于它們難以進行基于內容的推理,并因此作出了幾項改進:
首先,通過讓SSM參數成為輸入數據的函數,可以解決這類模型在處理離散數據類型時的不足。
這就使得模型能夠根據當前的token在序列長度的維度上選擇性地傳播或遺忘信息。
其次,盡管這樣的調整使得模型無法使用高效的卷積,但研究人員設計了一種適應硬件的并行算法,并在循環模式下實現它。
研究人員將這種選擇性的SSM集成進了一個簡化的端到端神經網絡架構中,這種架構不需要注意力機制,甚至也不需要MLP(多層感知器)模塊,這就是研究人員提出的Mamba。
Mamba在快速推理方面表現出色(比Transformers高5倍的處理速度),并且隨著序列長度的增加,其性能線性增長,在處理長達百萬長度的序列時表現更佳。
作為一個通用的序列處理模型,Mamba在語言、音頻和基因組學等多個領域都獲得了最先進的性能表現。
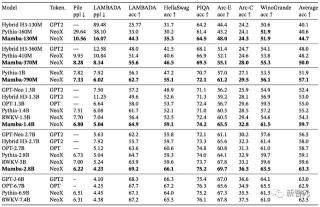
在語言建模方面,Mamba-3B模型在預訓練和后續評估中性能達了兩倍參數量的Transformers模型性能。
通過實證研究,研究人員驗證了Mamba在作為基礎模型(FM)的核心框架方面的巨大潛力。
這種潛力不僅體現在預訓練的質量上,還表現在特定領域任務的性能上,涵蓋了多種模態和環境:
- 合成任務
在重要的合成任務中,如復制和歸納等,Mamba不僅能輕松解決,還能推斷出無限長(>100萬個token)的解決方案。
-音頻和基因組學
在音頻波形和DNA序列建模方面,Mamba的表現優于SaShiMi、Hyena和Transformers等先前的SOTA模型,無論是在預訓練質量還是下游指標方面(例如,在具有挑戰性的語音生成數據集上,FID降低了一半以上)。
在這兩種情況下,它的性能隨著上下文長度的增加而提高,最高可達百萬長度的序列。
- 語言建模
Mamba是首個線性時間序列模型,無論是在預訓練復雜度還是在下游任務評估中,都能實現Transformer級別的性能。
將模型規模擴大到10億參數后,研究人員證明Mamba的性能超過了Llama等大量基線模型。
Mamba語言模型與同體量的Transformer相比,具有5倍的生成吞吐量,而且Mamba-3B的質量與兩倍于其規模的Transformer相當(與Pythia-3B相比,常識推理的平均值高出4分,甚至超過了Pythia-7B)。
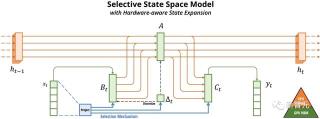
選擇性狀態空間模型
研究人員利用合成任務的直覺來激發他們的選擇機制,然后解釋如何將該機制合并到狀態空間模型中。由此產生的時變SSM無法使用卷積,這對如何有效地計算它們提出了技術挑戰。
研究人員通過利用現代硬件上的內存層次結構的硬件感知算法克服了這個問題。然后,研究人員描述了一個簡單的SSM架構,沒有注意力機制,甚至沒有MLP模塊。最后,研究人員討論選擇機制的一些附加屬性。
動機:選擇作為壓縮手段研究人員認為序列建模的一個基本問題是將上下文壓縮成更小的狀態。他們從這個角度來看待流行序列模型的權衡(tradeoffs)。
例如,注意力在某些方面非常有效,但是在另一些方面又很低效,因為它完全不壓縮上下文。從這一點可以看出,自回歸推理需要顯式存儲整個上下文(即KV緩存),這直接導致Transformers的線性時間推理和二次時間訓練緩慢。
另一方面,循環模型是高效的,因為他狀態是有限的,這意味著推理時間是恒定的,并且訓練的時間也將會是線性的。
然而,注意力的有效性受到這種狀態壓縮上下文的程度的限制。
為了理解這一原理,研究人員重點關注兩個合成任務的運行示例(如下圖2)。
選擇性復制(Selective Copying)任務通過改變要記憶的標記的位置來修改流行的復制任務。它需要內容感知推理才能記住相關標記(彩色)并過濾掉不相關標記(白色)。
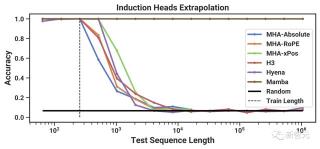
歸納頭(Induction Heads)任務是一種眾所周知的機制,以前的研究假設它可以解釋LLM的大多數情境學習能力。它需要上下文感知推理來知道何時在適當的上下文(黑色)中產生正確的輸出。
這些任務揭示了LTI模型的失效模式。從循環的角度來看,它們的恒定動態(例如(2)中的(A,B)轉換)不能讓它們從上下文中選擇正確的信息,或者影響沿輸入相關的序列傳遞的隱藏狀態方式。
從卷積的角度來看,眾所周知,全局卷積可以解決普通復制任務,因為它只需要時間感知,但由于缺乏內容意識,它們在選擇性復制任務上有困難(如上圖)。
更具體地說,輸入到輸出之間的間距是變化的,并且不能通過靜態卷積核進行建模。
總之,序列模型的效率與有效性權衡的特征在于它們壓縮狀態的程度:高效模型的狀態必須要小,而模型效果好必須要求這個小狀態要包含上下文中所有必要信息的狀態。
而相反,研究人員構建的序列模型的基本原則是選擇性:或者是關注或過濾輸入到序列狀態的上下文感知能力。
特別是,選擇機制控制信息如何沿著序列維度傳播或交互。
通過選擇改進SSM將選擇機制納入模型的一種方法是:讓影響序列交互的參數(例如 RNN 的循環動態或 CNN 的卷積核)依賴于輸入。
算法1和2說明了研究者使用的主要選擇機制。
主要區別在于簡單地使輸入的幾個參數Δ、B、C成為函數,以及整個張量形狀的相關更改。
需要注意,這些參數現在具有長度維度 ,這意味著模型已從時不變(time-invariant)改為時變(time-varying)。
這就失去了與卷積的等價性,并影響了其效率。
簡化的SSM架構與結構化SSM一樣,選擇性SSM是獨立的序列轉換,可以「靈活地合并到神經網絡中」。
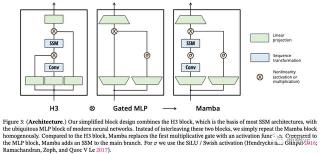
H3架構是最著名的SSM架構的基礎,該架構通常由受線性注意力啟發的塊與 MLP(多層感知器)塊交織組成。研究人員通過將這兩個組同質堆疊件合并為一個組件來簡化這一架構(如下圖)。
之所以這么處理是受到門控注意力單元(GAU)的啟發。該架構涉及通過可控擴展因子來擴展模型維度。對于每個塊,大多數參數(3ED^2)位于線性投影中,而內部SSM貢獻較少。SSM參數的數量相比起來要小的多。
研究人員重復了這個塊,與標準標準化和殘差連接交織,形成Mamba架構。
在實驗中,始終將x設為E=2,并使用塊的兩個堆棧來匹配Transformer交錯MHA(多頭注意力)和MLP塊的122個參數。
研究人員使用SiLU / Swish激活函數,其動機是使門控 MLP 成為流行的「SwiGLU」變體 。最后,研究人員還使用了一個可選的歸一化層,動機是RetNet在類似位置使用歸一層。
選擇機制是一個更廣泛的概念,可以以不同的方式應用,例如更傳統的RNN或CNN、不同的參數(例如算法2中的 A),或使用不同的變換。
實證評估
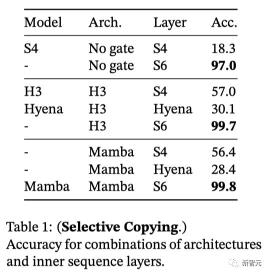
合成任務:選擇性復制復制任務是用來測試序列模型,特別是循環模型記憶能力的經典合成任務。
LTI SSM(線性遞歸和全局卷積)可以通過只關注時間而不是推理數據輕松地解決這個任務。例如,構建一個長度完全正確的卷積核(圖2)。
對此,選擇性復制任務則可以通過隨機改變token的間距,來阻止這種走捷徑的方法。
表1顯示,H3和Mamba等門控架構只能部分提升性能,而選擇機制(即將S4改進為S6)則可以輕松解決這一問題,尤其是與更強大的架構相結合時。
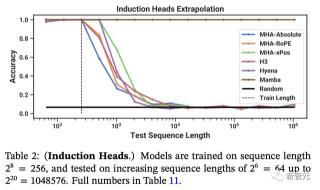
合成任務:歸納頭
歸納頭是一個從機械可解釋性的角度出發相對簡單的任務,卻意外地能夠預測大語言模型(LLMs)的上下文學習能力。
這項任務要求模型進行關聯性回憶和復制動作:比如,模型之前在一個序列中遇到過「Harry Potter」這樣的詞組,那么當「Harry」再次出現在同一個序列時,模型應能夠通過回顧歷史信息并預測出「Potter」。
表2顯示,Mamba模型,或者更準確地說是它的選擇性SSM層,由于能夠選擇性地記住相關的token,同時忽略中間其他的token,因此能夠完美地完成任務。
并且,它還能完美地泛化到百萬長度的序列,也就是訓練期間遇到的長度的4000倍。相比之下,其他方法的泛化能力都無法超過2倍。
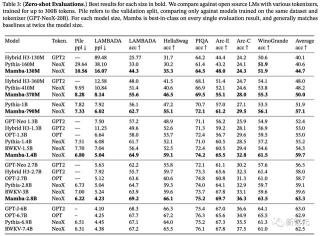
語言建模
研究人員將Mamba與標準的Transformer架構(即GPT-3架構),以及目前最先進的Transformer(Transformer++)進行了對比。
后者基于PaLM和LLaMa架構,其特點包括旋轉嵌入(rotary embedding)、SwiGLU MLP、使用RMSNorm替換LayerNorm、取消線性偏置,并采用更高的學習率。
圖4顯示,在從≈1.25億到≈13億的參數規模中,Mamba是首個在性能上媲美最強Transformer架構(Transformer++)的無注意力模型。
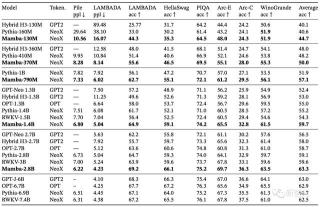
表3展示了Mamba在一系列下游zero-shot評估任務中的表現。
其中,Mamba在訓練時使用了與Pythia和RWKV相同的tokenizer、數據集和訓練長度(300B token)。
需要注意的是,Mamba和Pythia訓練時的上下文長度為2048,而RWKV為1024。
DNA建模
隨著大語言模型的成功,人們開始探索將基礎模型的范式應用于基因組學。
DNA由具有特定詞匯表的離散符號序列組成,還需要長程依賴關系來建模,因此被比作語言。
研究者將Mamba作為預訓練和微調的FM骨干進行了研究,研究背景與最近DNA長序列模型的研究相同。
在預訓練方面,研究者基本上按照標準的因果語言建模(下一個token預測)設置。
在數據集方面,基本沿用了鬣狗DNA的設置,它使用了HG38數據集進行預訓練,該數據集由單個人類基因組組成,在訓練分割中包含約45億個token(DNA堿基對)。
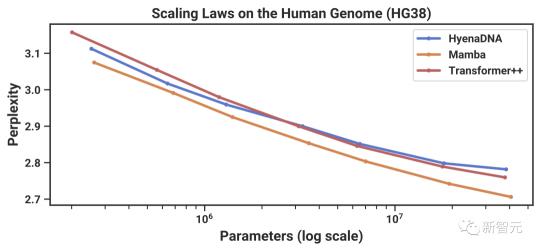
結果如圖5(左)顯示,Mamba的預訓練困惑度隨著模型規模的增大而平穩提高,并且Mamba的擴展能力優于 HvenaDNA和Transformer++。
例如,在最大模型規模≈40M參數時,曲線顯示,Mamba可以用少3到4倍的參數,與Transformer++和HvenaDNA模型相媲美。
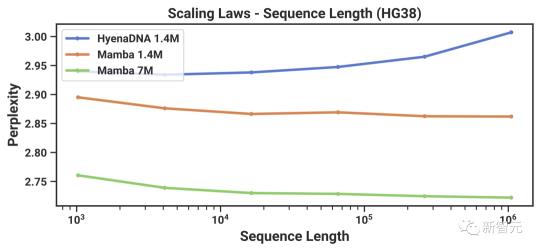
另外,圖5(右)顯示,Mamba能夠利用更長的上下文,甚至長達1M的極長序列,并且其預訓練困惑度會隨著上下文的增加而提高。
另一方面,鬣狗DNA模型會隨著序列長度的增加而變差。
從卷積的角度看,一個非常長的卷積核正在聚合一個長序列上的所有信息。
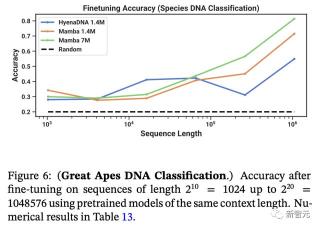
圖6是類人猿DNA的分類,顯示了使用相同上下文長度的預訓練模型對長度2^10到2^20的序列進行微調后的準確度。
音頻建模與生成
在音頻波形處理領域,主要對比的是SaShiMi架構。該模型包括:
1. 一個U-Net主干,通過兩個階段的池化操作,其中每個階段都將模型的維度D增加一倍,池化因子為p,
2. 每個階段都交替使用S4和MLP模塊。
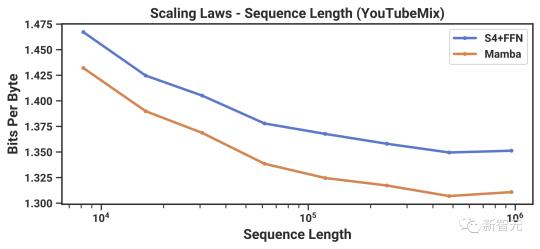
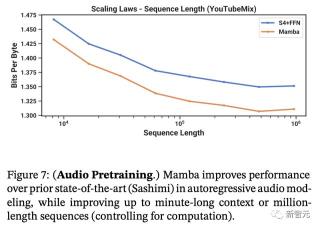
針對長上下文的自回歸式預訓練,研究人員采用了標準鋼琴音樂數據集——YouTubeMix進行評估。數據集包含了4小時的獨奏鋼琴音樂,采樣率為16000Hz。
圖7展示了在保持計算量不變的情況下,訓練序列長度從8192(2^13)增加到≈1000000(2^20)時的效果。
無論是Mamba還是SaShiMi(S4+MLP)基線模型,表現都隨著上下文長度的增加而穩步提升。其中,Mamba在整個過程中都更勝一籌,而且序列越長優勢越明顯。
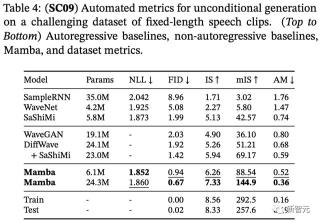
在自回歸語音生成方面,則使用基準語音生成數據集SC09進行評估。它由時長1秒的語音片段組成,采樣頻率為16000 Hz,包含數字「0」到「9」,特征多變。
表4展示了Mamba-UNet與一系列基準模型的自動評估結果,其中包括WaveNet、SampleRNN、WaveGAN、DiffWave以及SaShiMi。
可以看到,小規模的Mamba模型在性能上就已經超越了那些更大、采用了最先進的基于GAN和擴散技術的模型。而同等參數規模的Mamba模型,在保真度方面的表現更是大幅領先。
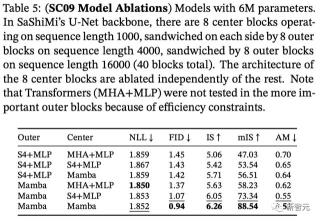
表5采用的是小規模Mamba模型,并探究了在外部和中心階段不同架構的組合效果。
研究發現,無論在外部塊還是中心塊,Mamba模型的表現都優于S4+MLP架構,而在中心塊的性能排名為Mamba > S4+MLP > MHA+MLP。
速度和顯存基準測試
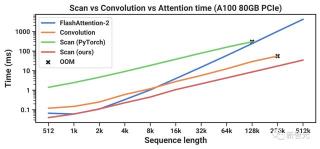
圖8展示了scan操作(狀態擴展N = 16)速度,以及Mamba端到端推理吞吐量的基準測試。
結果顯示,當序列長度超過2k時,高效的SSM scan比目前最優秀的注意力機制——FlashAttention-2還要快。而且,比起PyTorch標準的scan實現,速度提升更是高達20到40倍。
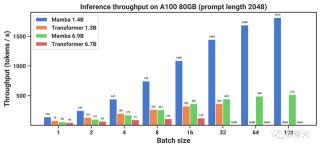
由于沒有鍵值(KV)緩存,因此Mamba可以支持更大的批處理大小,從而使推理吞吐量比同等規模Transformer高了4到5倍。
舉個例子,一個未經訓練的69億參數的Mamba(Mamba-6.9B),在推理處理能力上可以超過僅有13億參數、規模小5倍的Transformer模型。
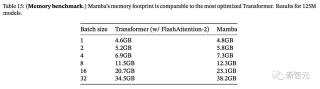
與大多數深度序列模型一樣,顯存使用量與激活張量的大小成正比。表15顯示,Mamba的顯存需求與經過優化的Transformer相當。
125M模型在單張A100 80GB GPU上訓練時顯存的需求
在論文最后,作者表示,選擇性狀態空間模型在為不同領域構建基礎模的廣泛應用性,太令人興奮了。
種種實驗結果表明,Mamba很有可能成為通用序列模型的主流框架,甚至有潛力跟Transformer一搏。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
