

 新火種
2023-11-28
新火種
2023-11-28 

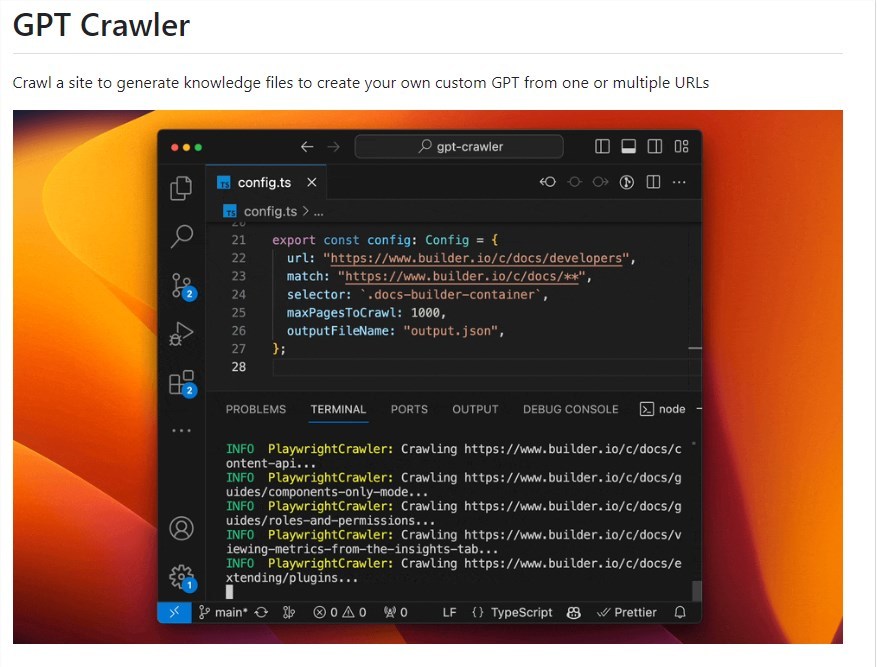

gptcrawler:從URL爬取網(wǎng)站生成結(jié)構(gòu)化知識,創(chuàng)建定制GPT
站長之家11月21日 消息:gpt crawler是一款強大的工具,能夠?qū)⒕W(wǎng)站內(nèi)容全面地爬取下來,并將其轉(zhuǎn)換成結(jié)構(gòu)化知識,為GPTs的學習提供了有力支持。
這個工具的應用場景廣泛,比如,如果你想打造一個數(shù)字人分身,可以先將自己在社交媒體或個人博客上的內(nèi)容抓取下來,然后提交給ChatGPT作為儲備知識。這種方式不僅能夠保存?zhèn)€人在網(wǎng)絡(luò)上的言論和觀點,還可以為ChatGPT提供更多的學習材料,使其更好地理解和模擬用戶的語言風格和思維方式。
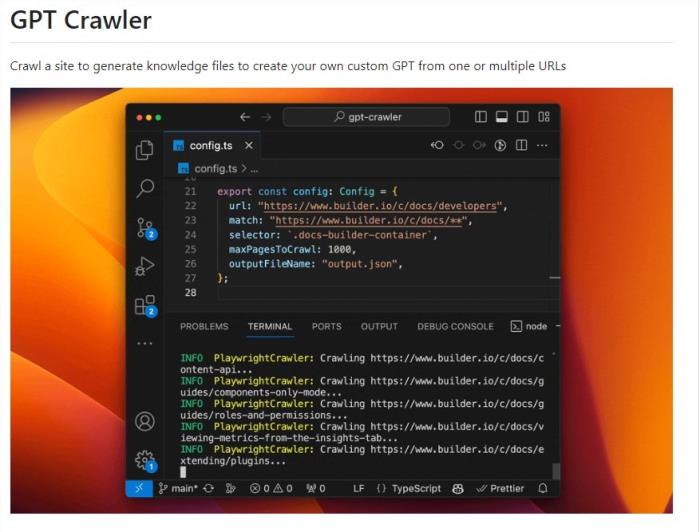
核心功能:
靈活配置爬蟲: 用戶可以通過編輯config.ts文件中的URL、選擇器等屬性,靈活配置爬蟲以適應不同的網(wǎng)站結(jié)構(gòu)和需求。
定制化知識文件生成: gpt-crawler通過爬取指定網(wǎng)站的內(nèi)容,生成包含知識數(shù)據(jù)的文件(output.json),為用戶提供定制GPT所需的基礎(chǔ)知識。
輕松上傳到OpenAI: 生成的知識文件可以方便地上傳至OpenAI,支持用戶在UI界面或通過API訪問生成的知識,用于創(chuàng)建自定義GPT或助手。
支持Docker容器化執(zhí)行: 通過容器化執(zhí)行,用戶可以獲得output.json,使整個過程更加靈活和可擴展。
貢獻和改進: 項目鼓勵用戶參與貢獻,通過提出Pull Request等方式改進工具,使其更加強大和適應更多場景。
據(jù)了解,gpt crawler背后采用了先進的技術(shù)框架crawlee。Crawlee不僅是一個高效的網(wǎng)絡(luò)爬蟲工具,還是一款強大的瀏覽器自動化工具。在實現(xiàn)上,它提供了多項關(guān)鍵功能,包括DOM解析能力、無頭瀏覽器模式、異常狀態(tài)碼處理、隊列和存儲等。這些功能的綜合運用使得爬蟲更加靈活和強大。此外,Crawlee還提供了大量的配置項,用戶可以根據(jù)自己的需求進行靈活設(shè)置,從而更好地適應不同的爬取任務(wù)。
相關(guān)推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
