

 新火種
2023-11-20
新火種
2023-11-20 


酷睿輕薄本上跑StableDiffusion,英特爾這項絕活背后的價值
自從 ChatGPT 火熱出圈,生成式 AI 大模型在全球掀起了新的技術浪潮。而 AI 作為數字化未來最重要的底層技術,也必然會對人類社會的生活、生產帶來顛覆性的改變。
但是就現階段而言,AI 距離真正改變世界還有很長的路要走,推動生成式 AI 大規模擴展和應用,也還面臨很多挑戰。
比如,如今生成式 AI 大模型產品主要部署在云端,在傳統認知上,云端能夠提供遠超終端的算力和存儲,但現實并非絕對,我們在使用這些云端大模型產品時其實也經常遇到響應緩慢、生成失敗等問題,這是因為在使用高峰期,即便是云端服務器也頂不住極端的算力需求。
而且,對于服務提供商來說,生成式 AI 每一次搜索查詢,成本都是傳統搜索方法的 10 倍。目前每天有超過 100 億次的搜索查詢產生,這樣它對云端算力帶來的負載以及產生的成本規模難以想象。

在這種情況下,生成式 AI 向終端側發展,就顯得尤為重要了。
盡管單一終端能提供的算力顯然無法和云端服務器相比,但如果把全球數十億甚至數百億終端的算力都調用起來,那無疑就可以大大分流云端的壓力。這也就是 AI 要往終端側發展的基本邏輯。
更重要的是,在半導體產業的努力下,這幾年終端的 AI 性能和算力也在突飛猛進,就拿生產力擔當的 PC 來說,行業引領者英特爾就為生成式 AI 在 PC 終端上的落地做出了突出的貢獻。

比如,在我們傳統的認知里,運行多模態的 AI 大模型必須要有超大顯存的專業顯卡加持以完成大量的 AI 并行運算,那么,對于輕薄筆記本或者消費級臺式機來說,是否也能支持 AI 大模型的順利運行呢?這其實就是英特爾在終端側 AIGC 努力的方向之一。
目前在硬件上,英特爾第 12、13 代酷睿處理器以及英特爾銳炫顯卡都可以滿足 AIGC 在 PC 本地端的高速算力需求。
針對銳炫顯卡,首先英特爾在持續增強其本身的性能體驗。自推出以來,英特爾銳炫顯卡已累計發布超過 20 版驅動更新,今年早些時候,英特爾還通過 Game On 驅動的發布,提升了銳炫顯卡在運行一系列備受歡迎的 DX11 游戲時的性能,可以讓游戲幀率得到平均約 19% 的幀率提神以及平均約 20% 的 99th Percentile 幀率流暢度提升。

而在今年 5 月,英特爾還展示了用生成式 AI 加速創作文生圖的示例,基于英特爾 OpenVINO,AI 繪圖開源模型 Stable Diffusion 可以使用開源圖片編輯軟件 GIMP 在英特爾銳炫 A750、A770 等顯卡上流暢運行。只需要輸入簡單的文本,就能智能實現創意繪圖,對于圖片創作者來說很實用。
今年 8 月,英特爾又展示了基于 OpenVINO PyTorch 后端的方案,用 Pytorch API 讓社區開源模型在英特爾的客戶端處理器、集成顯卡、獨立顯卡和專用 AI 引擎上很好的運行。
比如針對開源圖像生成模型 Stable Diffusion,英特爾就啟用了 OpenVINO 的加速,他們開發了一套 AI 框架,通過一行代碼的安裝,就可以加速 PyTorch 模型的運行。通過 Stable Diffusion 的 WebUI,可以在銳炬集成顯卡和 Arc 獨立顯卡上運行 Stable Diffusion Automatic1111。

這其中,尤其是讓 Stable Diffusion 在搭載集成顯卡的輕薄本上運行,可以說是一件具有重要意義的事情。
比如這里,就選擇一款輕薄本來做測試,這款產品是通過英特爾 Evo 平臺認證的華碩破曉 Air,搭載英特爾 13 代酷睿 i7-1355U 處理器,銳炬 Xe 集成式顯卡,16GB LPDDR5 內存。

可以看到 Stable Diffusion 在華碩破曉 Air 集成顯卡上的表現效果。96EU 版本的英特爾銳炬 Xe 顯卡強大的算力,可以支持 Stable Diffusion 軟件上運行 FP16 精度的模型,快速生成高質量圖片。小編讓 Stable Diffusion 生成一張“有黑色耳朵的小狗”,華碩破曉 Air 只用了大約十幾秒的時間就生成出來了。這是一幅 512×512 的圖,如果想畫的更好,你還可以自己調節參數。
再比如讓 Stable Diffusion 生成一張“一大堆煎餅壘起來的食物攝影”,在華碩破曉 Air 上同樣也可以輕松生成出來,并且是在實現的。
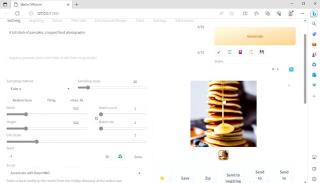
通常我們會認為,輕薄本不太適合做 AI 方面的工作,因為它的配置比較低。但通過上面 Stable Diffusion 的演示,相信大家可以看到 Evo 高性能輕薄本確實可以勝任這些簡單的 AIGC 圖片創作工作。
如果放在過去,我們很難想象輕薄本可以擁有這樣的性能,但隨著 13 代酷睿處理器在性能、功耗比方面的進步,以及銳炬 Xe Graphics (96EU) 在 FP16、FP32 浮點性能的大幅提升,同時加入了 INT8 整數計算能力,這些都大大增強了 GPU 整體的 AI 圖形計算能力。這也就是華碩破曉 Air 這樣的輕薄本也能在本地側很好地運行 Stable Diffusion 的重要因素。
值得一提的是,在英特爾下一代酷睿處理器 Meteor Lake 中,GPU 核顯性能還會得到進一步提升,將擁有 8 個 Xe GPU 核心 128 個渲染引擎,更增加了 8 個硬件的光追單元,還會引入 Arc 顯卡的異步拷貝,亂序采樣等功能,也對 DX12U 做了優化。
不僅如此,英特爾還在 Meteor Lake 中加入了集成式 NPU 單元,實現更高效能的 AI 計算,它包含了 2 個神經計算引擎,能夠更好地支持包括生成式 AI、計算機視覺、圖像增強和協作 AI 方面的內容。
同時除了 NPU,CPU 和 GPU 也都可以進行 AI 運算,不同場景下會用不同的 AI 單元去應對,彼此協調,如此一來,其整體能耗比相比前代最多可以提升 8 倍之多。因此,未來搭載 Meteor Lake 處理器的輕薄本在本地 AIGC 創作方面的表現會更加令人期待。

此外,如果追求更好性能,大家也可以選擇英特爾銳炫 Arc 獨顯的設備,在 Arc 獨顯上跑 Stable Diffusion,速度會快很多。比如今年早些時候英特爾也還展示了在搭載 i7-13700K CPU + Arc A770 獨顯的機器上運行 Stable Diffusion “圖生圖”、“人物動作三維數字重建”的效果,速度非常快。

總之,未來對于 PC 來說,所謂的性能將不僅局限在處理器的核心數、線程數、主頻這些傳統參數,而更在于 AI 運算和創作能力是否強大,換句話說,AI 定義芯片的時代正在到來,而 AI PC 將真正幫助我們實現生產力的大解放。因此,英特爾對于實現終端側 AIGC 所做的努力無疑具有重要意義,他們為用戶提供更智能、高效的移動計算體驗,推動人工智能技術的發展和應用走向終端和云端協同的新階段。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
