

 新火種
2023-09-20
新火種
2023-09-20 


深度強(qiáng)化學(xué)習(xí)探索算法最新綜述,近200篇文獻(xiàn)揭示挑戰(zhàn)和未來方向
作者:楊天培、湯宏垚、白辰甲、劉金毅等
強(qiáng)化學(xué)習(xí)是在與環(huán)境交互過程中不斷學(xué)習(xí)的,交互中獲得的數(shù)據(jù)質(zhì)量很程度上決定了智能體能夠?qū)W習(xí)到的策略的平。因此,如何引導(dǎo)智能體探索成為強(qiáng)化學(xué)習(xí)領(lǐng)域研究的核問題之。本介紹天津?qū)W深度強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)室近期推出的深度強(qiáng)化學(xué)習(xí)領(lǐng)域第篇系統(tǒng)性的綜述章,該綜述次全梳理了DRL和MARL的探索法,深分析了各類探索算法的挑戰(zhàn),討論了各類挑戰(zhàn)的解決思路,并揭了未來研究向。
當(dāng)前,強(qiáng)化學(xué)習(xí)(包括深度強(qiáng)化學(xué)習(xí)DRL和多智能體強(qiáng)化學(xué)習(xí)MARL)在游戲、機(jī)器等領(lǐng)域有常出的表現(xiàn),但盡管如此,在達(dá)到相同平的情況下,強(qiáng)化學(xué)習(xí)所需的樣本量(交互次數(shù))還是遠(yuǎn)遠(yuǎn)超過類的。這種對量交互樣本的需求,嚴(yán)重阻礙了強(qiáng)化學(xué)習(xí)在現(xiàn)實(shí)場景下的應(yīng)。為了提升對樣本的利效率,智能體需要效率地探索未知的環(huán)境,然后收集些有利于智能體達(dá)到最優(yōu)策略的交互數(shù)據(jù),以便促進(jìn)智能體的學(xué)習(xí)。近年來,研究員從不同的度研究RL中的探索策略,取得了許多進(jìn)展,但尚個(gè)全的,對RL中的探索策略進(jìn)深度分析的綜述。

論文地址:/uploads/pic/20230919/pp.pdf style="box-sizing: border-box;border: 0px;color: rgb(34, 34, 34);letter-spacing: normal;orphans: 2;text-indent: 0px;text-transform: none;white-space: normal;widows: 2;word-spacing: 0px;-webkit-text-stroke-width: 0px;background-color: rgb(255, 255, 255);text-decoration-thickness: initial;text-decoration-style: initial;text-decoration-color: initial;text-align: left" data-from-paste="1">本介紹深度強(qiáng)化學(xué)習(xí)領(lǐng)域第篇系統(tǒng)性的綜述章Exploration in Deep Reinforcement Learning: A Comprehensive Survey。該綜述共調(diào)研了將近200篇獻(xiàn),涵蓋了深度強(qiáng)化學(xué)習(xí)和多智能體深度強(qiáng)化學(xué)習(xí)兩領(lǐng)域近100種探索算法。總的來說,該綜述的貢獻(xiàn)主要可以總結(jié)為以下四:
三類探索算法。該綜述次提出基于法性質(zhì)的分類法,根據(jù)法性質(zhì)把探索算法主要分為基于不確定性的探索、基于內(nèi)在激勵(lì)的探索和其他三類,并從單智能體深度強(qiáng)化學(xué)習(xí)和多智能體深度強(qiáng)化學(xué)習(xí)兩系統(tǒng)性地梳理了探索策略。
四挑戰(zhàn)。除了對探索算法的總結(jié),綜述的另特點(diǎn)是對探索挑戰(zhàn)的分析。綜述中先分析了探索過程中主要的挑戰(zhàn),同時(shí),針對各類法,綜述中也詳細(xì)分析了其解決各類挑戰(zhàn)的能。
三個(gè)典型benchmark。該綜述在三個(gè)典型的探索benchmark中提供了具有代表性的DRL探索法的全統(tǒng)的性能較。
五點(diǎn)開放問題。該綜述分析了現(xiàn)在尚存的亟需解決和進(jìn)步提升的挑戰(zhàn),揭了強(qiáng)化學(xué)習(xí)探索領(lǐng)域的未來研究向。
接下來,本從綜述的四貢獻(xiàn)展開介紹。
三類探索算法
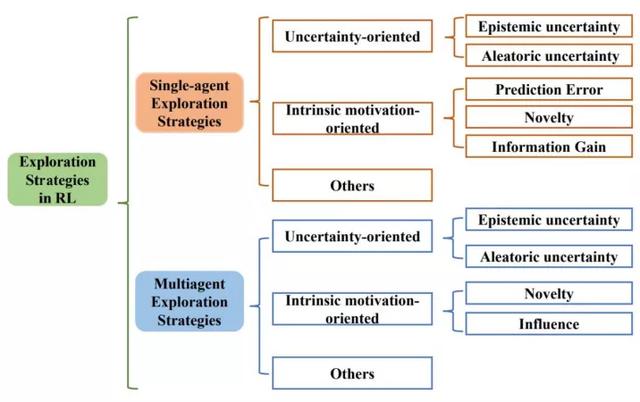
上圖展了綜述所遵循的分類法。綜述從單智能體深度強(qiáng)化學(xué)習(xí)算法中的探索策略、多智能體深度強(qiáng)化學(xué)習(xí)算法中的探索策略兩向系統(tǒng)性地梳理了相關(guān)作,并分別分成三個(gè)類:向不確定性的(Uncertainty-oriented)探索策略、向內(nèi)在激勵(lì)的(Intrinsic motivation oriented)探索策略、以及其他策略。
1、向不確定性的探索策略
通常遵循“樂觀對待不確定性”的指導(dǎo)原則(OFU Principle)「1」。這類做法認(rèn)為智能體對某區(qū)域更的不確定性(Uncertainty)往往是因?yàn)閷υ搮^(qū)域不充分的探索導(dǎo)致的,因此樂觀地對待不確定性,也即引導(dǎo)智能體去探索不確定性的地,可以實(shí)現(xiàn)效探索的的。
強(qiáng)化學(xué)習(xí)中般考慮兩類不確定性,其中引導(dǎo)往認(rèn)知不確定性的區(qū)域探索可以促進(jìn)智能體的學(xué)習(xí),但訪問環(huán)境不確定性的區(qū)域不但不會促進(jìn)智能體學(xué)習(xí)過程,反由于環(huán)境不確定性的擾會影響到正常學(xué)習(xí)過程。因此,更合理的做法是在樂觀對待認(rèn)知不確定性引導(dǎo)探索的同時(shí),盡可能地避免訪問環(huán)境不確定性更的區(qū)域。基于此,根據(jù)是否在探索中考慮了環(huán)境不確定性,綜述中將這類基于不確定性的探索策略分為兩個(gè)類。
第類只考慮在認(rèn)知不確定性的引導(dǎo)下樂觀探索,典型作有RLSVI「2」、Bootstrapped DQN「3」、OAC「4」、OB2I「5」等;第類在樂觀探索的同時(shí)考慮避免環(huán)境不確定性的影響,典型作有IDS「6」、DLTV「7」等。
2、向內(nèi)在激勵(lì)信號的探索策略
類通常會通過不同式的我激勵(lì),積極主動(dòng)地與世界交互并獲得成就感。受此啟發(fā),內(nèi)在激勵(lì)信號導(dǎo)向的探索法通常通過設(shè)計(jì)內(nèi)在獎(jiǎng)勵(lì)來創(chuàng)造智能體的成就感。從設(shè)計(jì)內(nèi)在激勵(lì)信號所使的技術(shù),單智能體法中向內(nèi)在激勵(lì)信號的探索策略可分為三類,也即估計(jì)環(huán)境動(dòng)學(xué)預(yù)測誤差的法、狀態(tài)新穎性估計(jì)法和基于信息增益的法。在多智能體問題中,前的探索策略主要通過狀態(tài)新穎性和社會影響兩個(gè)度考慮設(shè)計(jì)內(nèi)在激勵(lì)信號。
估計(jì)環(huán)境動(dòng)學(xué)預(yù)測誤差的法主要是基于預(yù)測誤差,勵(lì)智能體探索具有更預(yù)測誤差的狀態(tài),典型作有ICM「8」、EMI「9」等。
狀態(tài)新穎性法不局限于預(yù)測誤差,是直接通過衡量狀態(tài)的新穎性(Novelty),將其作為內(nèi)在激勵(lì)信號引導(dǎo)智能體探索更新穎的狀態(tài),典型作有RND「10」、Novelty Search「11」、LIIR「12」等。
基于信息增益的法則將信息獲取作為內(nèi)在獎(jiǎng)勵(lì),旨在引導(dǎo)智能體探索未知領(lǐng)域,同時(shí)防智能體過于關(guān)注隨機(jī)領(lǐng)域,典型作有VIME「13」等。
在多智能體強(qiáng)化學(xué)習(xí)中,有類特別的探索策略通過衡量“社會影響”,也即衡量智能體對其他智能體的影響作,指導(dǎo)作為內(nèi)在激勵(lì)信號,典型作有EITI和 EDTI「14」等。
3、其他
除了上述兩類主流的探索算法,綜述還調(diào)研了其他些分的法,從其他度進(jìn)有效的探索。這些法為如何在DRL中實(shí)現(xiàn)通和有效的探索提供了不同的見解。
這主要包括以下三類,是基于分布式的探索算法,也即使具有不同探索行為的異構(gòu)actor,以不同的式探索環(huán)境,典型作包括Ape-x「15」、R2D2「16」等。是基于參數(shù)空間噪聲的探索,不同于對策略輸出增加噪聲,采噪聲對策略參數(shù)進(jìn)擾動(dòng),可以使得探索更加多樣化,同時(shí)保持致性,典型作包括NoisyNet「17」等。除了以上兩類,綜述還介紹了其他種不同思路的探索法,包括Go-Explore「18」,MAVEN「19」等。
四大挑戰(zhàn)
綜述重點(diǎn)總結(jié)了效的探索策略主要臨的四挑戰(zhàn)。
規(guī)模狀態(tài)動(dòng)作空間。狀態(tài)動(dòng)作空間的增加意味著智能體需要探索的空間變,就疑導(dǎo)致了探索難度的增加。
稀疏、延遲獎(jiǎng)勵(lì)信號。稀疏、延遲的獎(jiǎng)勵(lì)信號會使得智能體的學(xué)習(xí)常困難,探索機(jī)制合理與否直接影響了學(xué)習(xí)效率。
觀測中的噪聲。現(xiàn)實(shí)世界的環(huán)境通常具有很的隨機(jī)性,即狀態(tài)或動(dòng)作空間中通常會出現(xiàn)不可預(yù)測的內(nèi)容,在探索過程中避免噪聲的影響也是提升效率的重要因素。
多智能體探索挑戰(zhàn)。多智能體任務(wù)下,除了上述挑戰(zhàn),指數(shù)級增長的狀態(tài)動(dòng)作空間、智能體間協(xié)同探索、局部探索和全局探索的權(quán)衡都是影響多智能體探索效率的重要因素。
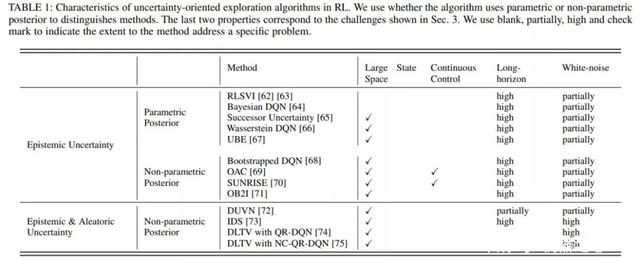
綜述中總結(jié)了這些挑戰(zhàn)產(chǎn)的原因,及可能的解決法,同時(shí)在詳細(xì)介紹法的部分,針對現(xiàn)有法對這些挑戰(zhàn)的應(yīng)對能進(jìn)了詳細(xì)的分析。如下圖就分析了單智能體強(qiáng)化學(xué)習(xí)中基于不確定性的探索法解決這些挑戰(zhàn)的能。
三個(gè)經(jīng)典的benchmark
為了對不同的探索法進(jìn)統(tǒng)的實(shí)驗(yàn)評價(jià),綜述總結(jié)了上述種有代表性的法在三個(gè)代表性 benchmark上的實(shí)驗(yàn)結(jié)果: 《蒙特祖瑪?shù)膹?fù)仇》,雅達(dá)利和Vizdoom。
蒙特祖瑪?shù)膹?fù)仇由于其稀疏、延遲的獎(jiǎng)勵(lì)成為個(gè)較難解決的任務(wù),需要RL智能體具有較強(qiáng)的探索能才能獲得正反饋;穿越多個(gè)房間并獲得分則進(jìn)步需要類平的記憶和對環(huán)境中事件的控制。
整個(gè)雅達(dá)利系列側(cè)重于對提RL 智能體學(xué)習(xí)性能的探索法進(jìn)更全的評估。
Vizdoom是另個(gè)具有多種獎(jiǎng)勵(lì)配置(從密集到常稀疏)的代表性任務(wù)。與前兩個(gè)任務(wù)不同的是,Vizdoom是款帶有第稱視的導(dǎo)航(和射擊)游戲。這模擬了個(gè)具有嚴(yán)重的局部可觀測性和潛在空間結(jié)構(gòu)的學(xué)習(xí)環(huán)境,更類似于類對的現(xiàn)實(shí)世界的學(xué)習(xí)環(huán)境。
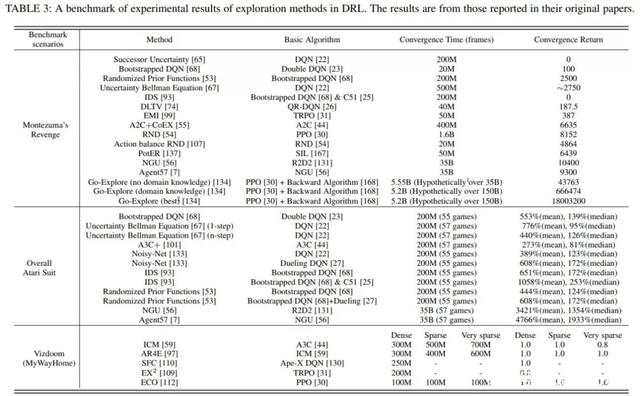
基于上表所的統(tǒng)的實(shí)驗(yàn)結(jié)果,結(jié)合所提出的探索中的主要挑戰(zhàn),綜述中詳細(xì)分析了各類探索策略在這些任務(wù)上的優(yōu)劣。
關(guān)于探索策略的開放問題和未來方向
盡管探索策略的研究取得了常前沿的進(jìn)展,但是仍然存在些問題沒有被完全解決。綜述主要從以下五個(gè)度討論了尚未解決的問題。
在規(guī)模動(dòng)作空間的探索。在規(guī)模動(dòng)作空間上,融合表征學(xué)習(xí)、動(dòng)作語義等法,降低探索算法的計(jì)算復(fù)雜度仍然是個(gè)急需解決的問題。
在復(fù)雜任務(wù)(時(shí)間步較長、極度稀疏、延遲的獎(jiǎng)勵(lì)設(shè)置)上的探索,雖然取得了一定的進(jìn)展,如蒙特祖瑪?shù)膹?fù)仇,但這些解決辦法代價(jià)通常較,甚要借助量類先驗(yàn)知識。這其中還存在較多普遍性的問題值得探索。
噪聲問題。現(xiàn)有的些解決案都需要額外估計(jì)動(dòng)態(tài)模型或狀態(tài)表征,這疑增加了計(jì)算消耗。除此之外,針對噪聲問題,利對抗訓(xùn)練等式增加探索的魯棒性也是值得研究的問題。
收斂性。在向不確定性的探索中,線性MDP下認(rèn)知不確定性是可以收斂到0的,但在深度神經(jīng)絡(luò)下維度爆炸使得收斂困難。對于向內(nèi)在激勵(lì)的探索,內(nèi)在激勵(lì)往往是啟發(fā)式設(shè)計(jì)的,缺乏理論上合理性論證。
多智能體探索。多智能體探索的研究還處于起步階段,尚未很好地解決上述問題,如局部觀測、不穩(wěn)定、協(xié)同探索等。
主要作者介紹
楊天培博,現(xiàn)任University of Alberta博后研究員。楊博在2021年從天津?qū)W取得博學(xué)位,她的研究興趣主要包括遷移強(qiáng)化學(xué)習(xí)和多智能體強(qiáng)化學(xué)習(xí)。楊博致于利遷移學(xué)習(xí)、層次強(qiáng)化學(xué)習(xí)、對建模等技術(shù)提升強(qiáng)化學(xué)習(xí)和多智能體強(qiáng)化學(xué)習(xí)的學(xué)習(xí)效率和性能。前已在IJCAI、AAAI、ICLR、NeurIPS等頂級會議發(fā)表論余篇,擔(dān)任多個(gè)會議期刊的審稿。
湯宏垚博,天津?qū)W博在讀。湯博的研究興趣主要包括強(qiáng)化學(xué)習(xí)、表征學(xué)習(xí),其學(xué)術(shù)成果發(fā)表在AAAI、IJCAI、NeurIPS、ICML等頂級會議期刊上。
甲博,哈爾濱業(yè)學(xué)博在讀,研究興趣包括探索與利、離線強(qiáng)化學(xué)習(xí),學(xué)術(shù)成果發(fā)表在ICML、NeurIPS等。
劉毅,天津?qū)W智能與計(jì)算學(xué)部碩在讀,研究興趣主要包括強(qiáng)化學(xué)習(xí)、離線強(qiáng)化學(xué)習(xí)等。
郝建業(yè)博,天津?qū)W智能與計(jì)算學(xué)部副教授。主要研究向?yàn)樯疃葟?qiáng)化學(xué)習(xí)、多智能體系統(tǒng)。發(fā)表智能領(lǐng)域國際會議和期刊論100余篇,專著2部。主持參與國家基委、科技部、天津市智能重等科研項(xiàng)10余項(xiàng),研究成果榮獲ASE2019、DAI2019、CoRL2020最佳論獎(jiǎng)等,同時(shí)在游戲AI、告及推薦、動(dòng)駕駛、絡(luò)優(yōu)化等領(lǐng)域落地應(yīng)。
Reference
[1]P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,” Machinelearning, vol. 47, no. 2-3, pp. 235–256, 2002.
[2]I. Osband, B. V. Roy, and Z. Wen, “Generalization and exploration via randomized value functions,” inInternational Conference on Machine Learning, 2016, pp. 2377–2386.
[3]I. Osband, C. Blundell, A. Pritzel, and B. V. Roy, “Deep exploration via bootstrapped DQN,” in Advances inNeural Information Processing Systems 29, 2016, pp. 4026–4034.
[4]K. Ciosek, Q. Vuong, R. Loftin, and K. Hofmann, “Better exploration with optimistic actor critic,” inAdvances in Neural Information Processing Systems, 2019, pp. 1785–1796.
[5]C. Bai, L. Wang, L. Han, J. Hao, A. Garg, P. Liu, and Z. Wang, “Principled exploration via optimisticbootstrapping and backward induction,” in International Conference on Machine Learning, 2021.
[6]J. Kirschner and A. Krause, “Information directed sampling and bandits with heteroscedastic noise,” inConference On Learning Theory, 2018, pp. 358–384.
[7]B. Mavrin, H. Yao, L. Kong, K. Wu, and Y. Yu, “Distributional reinforcement learning for efficientexploration,” in International Conference on Machine Learning, 2019, pp. 4424–4434.
[8]D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-driven exploration by self-supervisedprediction,” in International Conference on Machine Learning, 2017, pp. 2778–2787.
[9]H. Kim, J. Kim, Y. Jeong, S. Levine, and H. O. Song, “EMI: exploration with mutual information,” inInternational Conference on Machine Learning, 2019, pp. 3360–3369.
[10]Y. Burda, H. Edwards, A. J. Storkey, and O. Klimov, “Exploration by random network distillation,” inInternational Conference on Learning Representations, 2019.
[11]R. Y. Tao, V. Franois-Lavet, and J. Pineau, “Novelty search in representational space for sample efficientexploration,” in Advances in Neural Information Processing Systems, 2020.
[12]Y. Du, L. Han, M. Fang, J. Liu, T. Dai, and D. Tao, “LIIR: learning individual intrinsic reward in multi-agentreinforcement learning,” in Advances in Neural Information Processing Systems, 2019, pp. 4405– 4416
[13]R. Houthooft, X. Chen, Y. Duan, J. Schulman, F. D. Turck, and P. Abbeel, “VIME: variational information maximizing exploration,” in Advances in Neural Information Processing Systems, 2016, pp. 1109–1117.
[14]T. Wang, J. Wang, Y. Wu, and C. Zhang, “Influence-based multi-agent exploration,” in International Conference on Learning Representations, 2020
[15]D. Horgan, J. Quan, D. Budden, G. Barth-Maron, M. Hessel, H. van Hasselt, and D. Silver, “Distributed prioritized experience replay,” in International Conference on Learning Representations, 2018.
[16]S. Kapturowski, G. Ostrovski, J. Quan, R. Munos, and W. Dabney, “Recurrent experience replay in distributed reinforcement learning,” in International Conference on Learning Representations, 2019.
[17]M. Fortunato, M. G. Azar, B. Piot, J. Menick, M. Hessel, I. Osband, A. Graves, V. Mnih, R. Munos, D. Hassabis, O. Pietquin, C. Blundell, and S. Legg, “Noisy networks for exploration,” in International Conference on Learning Representations, 2018.
[18]E. Adrien, H. Joost, L. Joel, S. K. O, and C. Jeff, “First return, then explore,” Nature, vol. 590, no. 7847, pp.580–586, 2021.
[19]A. Mahajan, T. Rashid, M. Samvelyan, and S. Whiteson, “MAVEN: multi-agent variational exploration,” inAdvances in Neural Information Processing Systems, 2019, pp. 7611–7622.
Tags:
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
