

 新火種
2023-11-17
新火種
2023-11-17 


MIT學者獨家撰文:ChatGPT的瓶頸與解藥
圖片來源@視覺中國
文 | 甲子光年科技產(chǎn)業(yè)智庫,作者|羅鴻胤,編輯|王博、蘇霍伊
*本文為麻省理工學院(MIT)學者羅鴻胤獨家供稿,「甲子光年」經(jīng)其授權后編輯發(fā)布。羅鴻胤是人工智能領域的青年科學家、MIT 計算機學與人工智能實驗室(CSAIL)的博士后研究員,主要關注自然語言處理方向,包括自訓練算法、蘊含模型、語言模型推理問題。他博士畢業(yè)于 MIT 電子工程與計算機科學系,師從 Jim Glass 博士;本科畢業(yè)于清華大學計算機系,師從劉知遠教授。
人工智能領域一直存在著學派之爭。
曾經(jīng),“建制派”的符號主義 AI 被看作“唯一的主導力量”,“邏輯驅動”的人工智能曾主宰數(shù)十年;另一派則是代表經(jīng)驗主義 AI 的深度學習,不追求解釋和邏輯,以神經(jīng)網(wǎng)絡和大數(shù)據(jù)開啟”暴力美學“的大門。
以 GPT 系列為代表的大語言模型就是這條“暴力美學”路線的產(chǎn)物。這條路現(xiàn)在看來是成功的,但也存在一定的局限性。
從人工智能誕生的第一天起,計算機科學家們一直在比較以神經(jīng)網(wǎng)絡為代表的經(jīng)驗主義 AI 與以數(shù)理邏輯為代表的符號主義 AI 的優(yōu)劣。簡單來說,經(jīng)驗主義 AI 主張通過對大量數(shù)據(jù)的學習來獲取知識,而符號主義 AI 則強調精確的任務定義和嚴謹?shù)臄?shù)學工具。
隨著近十年的算力進化,神經(jīng)網(wǎng)絡這一最典型的經(jīng)驗主義 AI 模型得到了飛速的發(fā)展。由于無法匹敵神經(jīng)網(wǎng)絡處理非結構化信息的能力和泛用性、無法生成非結構化數(shù)據(jù)(如自然語言),符號主義 AI 的存在感和影響力快速降低。
但是在我看來,基于符號和邏輯的推理 (reasoning) 遠比基于經(jīng)驗和數(shù)據(jù)的感知 (perception) 復雜。經(jīng)驗主義 AI 發(fā)展的頂點,正是符號主義 AI 大放異彩的起點。
著名語言模型批評者 Gary Marcus 博士曾銳評道:“大語言模型沒法做一些有嚴格定義的工作:遵守國際象棋規(guī)則、五位數(shù)字相乘、在家譜中進行可靠的推理、比較不同物體的重量等等。”
“火力全開”的 Marcus 博士指出了目前大語言模型存在的問題,但是這個問題并非沒有解決方法,我認為:大語言模型(LLM)只是不能通過生成文本做有嚴格定義的工作。大語言模型可以通過生成 “自然語言嵌入式程序” (natural language embedded program, NLEP)準確完成上述工作。
NLEP 是我與麻省理工學院(MIT)、香港中文大學(CUHK)研究團隊共同研發(fā)的一種兼顧符號推理和自然語言生成的程序。它將語言智能抽象為「“思維”編程 + 程序執(zhí)行」兩個步驟,能讓大語言模型同時具有生成自然語言和精確執(zhí)行復雜推理任務的能力。
在傳統(tǒng)認知里,符號 AI 無法處理非結構化數(shù)據(jù)和生成自然語言。而 NLEP 的方法證明,符號 AI 可以處理非結構化數(shù)據(jù)、自然語言,還可以強化非結構化數(shù)據(jù)深層的結構規(guī)律和推理能力。
或許在不久的將來,符號主義有潛力替代經(jīng)驗主義。
接下來,我將從 Marcus 博士的銳評出發(fā),討論以下內(nèi)容:
01 大模型與醉酒的人相似當前最先進的神經(jīng)網(wǎng)絡模型其實與醉酒的人相似。
他們都努力與人互動、跟隨簡單指令生成信息,少數(shù)還試圖駕駛交通工具。同時,他們也都帶來了商業(yè)機遇和社會風險,并可能引起廣泛討論。
人類認知功能不完整時(如醉酒、夢囈、疾病等),語言行為往往是脫離邏輯思維的。
這時,人類只是依賴語言本能,把輸入信號強行拼湊成有一定語法結構的句子(文本補全)。表達的內(nèi)容可能是如李白斗酒詩百篇般的藝術瑰寶,也可能只是毫無意義的胡言亂語。
事實上,人類大腦語言區(qū)域的發(fā)現(xiàn)正是基于臨床醫(yī)生對認知功能受損、保留了部分語言能力患者的研究。類似的科學方法也被大量應用于探索 AI 模型行為和規(guī)律的研究中。
隨著算力的快速發(fā)展,OpenAI 等機構花費數(shù)百億美元構建了參數(shù)量遠超人類語言器官的神經(jīng)網(wǎng)絡,和文本量遠超人類閱讀極限的訓練數(shù)據(jù),為體積遠大于人腦的機器賦予了類似的文本補全能力。
但此類模型生成的究竟是 “語言” 還是 “夢囈”?
這個問題已經(jīng)在學術界引起了激烈爭論。爭論的結果關乎社會和業(yè)界對 AI 可解釋性、可靠性、安全性的認可程度。而決定結果的關鍵就在于語言模型是否存在可控、準確的思維能力。
為了回答這一核心問題,谷歌旗下研究機構 DeepMind 的最新論文指出,語言模型本質上是信息的壓縮模型。
只要模型的表示能力足夠強(參數(shù)量足夠)、被壓縮的訓練數(shù)據(jù)量足夠大,語言模型就能在壓縮信息的過程中抽象出一定的思維能力,包括推理、計算、預測等等。
最先進的語言模型(例如 GPT-4)展現(xiàn)出的回答問題、跟隨指令、編寫代碼的能力顯然早已超越了任何人類的 “夢囈”。但如果說 GPT-4 和基于 GPT-4 的種種 Agent 足夠可靠,似乎為時尚早。
GPT-4 是極端經(jīng)驗主義 AI 的代表:把世界上所有的高質量文本、程序、數(shù)學、對話數(shù)據(jù)壓縮到算力允許的最大模型里,再抽象出這一技術路線蘊含的最強思維能力。它沒有可靠推理引擎的支撐,完全依賴簡單粗暴、類似“死記硬背”的大量訓練。無論多少計算和數(shù)據(jù)資源,都無法掩蓋和彌補 GPT-4 本質的推理缺陷。就如同酒駕的司機,無論酒量多好、多么僥幸,都無法避免酒精對人反應和判斷能力的本質危害。
正如不同的任務對人的思維嚴謹程度有不同要求,當前的語言模型更適用于能容忍甚至歡迎一些噪聲的應用場景,但在需要執(zhí)行準確、可控的復雜推理任務時,其可靠性有根本的缺陷。GPT-4 甚至會在回答一些并不復雜的問題時生成自相矛盾的文本,如下圖所示:


實際上,吳丹(U Thant)是第一位來自于亞洲的聯(lián)合國秘書長,潘基文(Ban Ki-moon)是第二位來自于亞洲的聯(lián)合國秘書長,上圖中 GPT-4 的回答并不準確。
能力如此強大的 GPT-4,卻依然會在簡單的問答中生成自相矛盾的語言,這也佐證了現(xiàn)階段語言模型推理的不可靠性。
02 文本補全模型的瓶頸就在文本人類運用語言的能力可以抽象成知識、推理、計算三大模塊,并且語言絕對不等于文本。
許多語言模型(文本補全模型)的問題難以解決,絕非模型不夠強大,而是因為自然語言文本是思維結果的表達,并不是思維過程的載體。
比如,我們想要學好物理,“事半功倍”的辦法就需要從物理定律、求解問題、設計實驗的思路出發(fā);反之“事倍功半”的辦法則是死記硬背一百本物理習題卻不理解牛頓定律。采用這種方法的學習者花費更多的時間,但還是無法融會貫通地解決沒見過的問題。
這個缺陷并不是解題模型——人類大腦的問題,而是訓練數(shù)據(jù)的缺陷——問題的答案只是物理定律的表象,而解題思維代表著對物理定律的直接應用。
不可否認,“死記硬背”是實現(xiàn)“答對考題”的技術路線之一。與之相似,使用大型神經(jīng)網(wǎng)絡在大規(guī)模數(shù)據(jù)集上學習文本補全能力,也是當前 AI “獲得思維”的技術路線。
雖然巨量的計算資源與數(shù)據(jù)的投入讓這種技術路線取得了成功,但諸多的研究和應用已經(jīng)證明,這種技術路線的可靠性瓶頸會帶來諸多挑戰(zhàn):臆想、推理能力有限、隱私泄露、合規(guī)問題等等。
大語言模型的能力是一把雙刃劍:可以處理不存在于訓練數(shù)據(jù)中的新問題,但也會在其不知情的情況下,輸出錯誤的推理結果。
作為通過壓縮文本提煉思維的黑盒模型,其知識、思維、推理能力都儲存在神經(jīng)網(wǎng)絡的權重中。AI 的優(yōu)勢和不足都體現(xiàn)在以下幾個方面:
抽取真實或失實的知識和信息;規(guī)劃非結構化的推理流程;由模型執(zhí)行有誤差的計算。由于以上三個模塊都有可能出錯,大模型的行為難以驗證、解釋、控制、改進。
針對“在美國,哪種新冠病毒造成了最高的 ICU 占用量”這個問題,GPT-4模型的回答是“德爾塔變種導致的 ICU 占用量最高”。
那真實的情況是什么?
在 11 月 6 日的 OpenAI 開發(fā)日前,沒有搜索引擎增強的 GPT-4 模型會給出定性的回答和解釋:

開發(fā)日后的 GPT-4 系統(tǒng)默認調用必應搜索引擎,會基于搜索結果給出數(shù)據(jù)、作出一定解釋和參考資料引用:
 中文翻譯:
中文翻譯:
獲得搜索增強的 ChatGPT 生成了更有說服力、文本更專業(yè)的回復。尤其是在其中三處引用了參考資料網(wǎng)址,更加提高了用戶閱讀答案后的滿意度(和被誤導的可能性)。
遺憾的是, ChatGPT 的用戶很難驗證答案的正確性。事實上,重復問最新的(2023 年 11 月 13 日)、搜索引擎加持的 GPT-4 同樣的問題,它還會生成各種不同的回答:
回答 a:“奧密克戎變異 – 占用了高達 30.4% 的 ICU 病床。”
回答 b:“雖然感染了德爾塔變異的病人最多占用了 31% 的 ICU 病床,但奧密克戎病人占用了更多。”
回答 c:“好像不是奧密克戎變異,好像是德爾塔變異。”
雖然在不同嘗試中 GPT-4 的回答自相矛盾,但是每一次回答生成的文本看起來都很正式、客觀、有說服力、甚至附帶搜索引擎給出的參考文獻。未經(jīng)多次驗證答案的讀者很容易受到誤導。
語言模型的這種能力非常適合于創(chuàng)作和想象:給一個標題,寫三個小故事之類的任務對于 ChatGPT 而言恰到好處。但遺憾的是,這種不可控的行為模式,在回答需要嚴謹推理的問題時應該被盡量避免。
更遺憾的是,雖然給了 GPT-4 多次嘗試的機會甚至搜索引擎的加持,上述新老 GPT-4 猜測的答案中沒有一個是正確的。
根據(jù)權威統(tǒng)計機構數(shù)據(jù)看世界(Our World in Data)信息,美國因新冠病毒導致的 ICU 病床日占用量峰值應發(fā)生在 2020 年冬天阿爾法變異流行期間。GPT-4 基于必應搜索引擎提供的大量“比較德爾塔與奧密克戎變種病毒”的文章得出“德爾塔或奧密克戎變異造成了最高的 ICU 病床占用量”是不準確的。
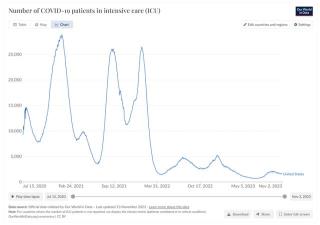
那么,GPT-4 在知識、推理、計算的哪一步出現(xiàn)了錯誤?是搜索的數(shù)據(jù)出了問題,還是對于三個峰值比較大小的運算出了問題?用戶并不了解。
在上述例子中,GPT-4 的可解釋性和可靠性都會受到質疑。為了改進語言模型的事實性、可解釋性、可控性和可靠性,OpenAI、Meta、麻省理工學院、香港中文大學(CUHK)、卡耐基梅隆大學、滑鐵盧大學等機構的研究人員分別提出了不同的基于編程語言以及程序解釋器增強的技術方案。
其中,比較廣為人知的方案是 OpenAI 開發(fā)的 ChatGPT 代碼解釋器和 Meta 提出的 Toolformer 模型。它們在文本生成的過程中將一部分內(nèi)容“外包”給程序或 API,例如數(shù)學運算。
代碼解釋器或者可靠 API 能夠保證在輸入正確的情況下永遠計算出一致、正確的結果,并將結果返回到語言模型生成的內(nèi)容里,比如:
 最后的總分是由一段 python 代碼計算得到:
最后的總分是由一段 python 代碼計算得到: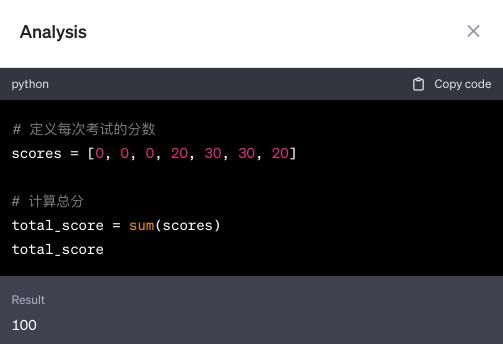
雖然“外包”了一部分推理任務給可靠的代碼解釋器,ChatGPT 的主干仍然是自然語言。上述例子只在最后一步計算總分時調用了代碼解釋器,而步驟 3 中 “30 分” 的中間結果仍然是由自然語言完成的推理。
最新的研究表明,在很多任務上 ChatGPT 負責調用代碼解釋器的數(shù)據(jù)分析(Data Analysis) Agent 仍不能取得準確的推理效果。比如,它拒絕用代碼解決一些非結構化問題中的結構化推理任務,因此得到錯誤的結果:

在這個例子中,我們的問題是“有幾位聯(lián)合國秘書長不是來自歐洲?”雖然使用了 ChatGPT 的數(shù)據(jù)分析 agent,但它拒絕使用代碼分析,而是使用自然語言“敷衍了事”。這也就造成了,雖然 GPT-4 生成了正確的人物列表及國籍,最后的計數(shù)卻漏了來自亞洲的潘基文秘書長。
這里正確答案應為 5 位聯(lián)合國秘書長來自歐洲,而 ChatGPT 數(shù)據(jù)分析 Agent 偷工減料推理得到的結果是 4 位。
03 NLEP方案:符號主義AI的極致嘗試NLEP 是一種同時提高自然語言、符號推理能力的神經(jīng)符號 (neuro-symbolic) 方法。
針對 ChatGPT 代碼解釋器的種種痛點,麻省理工學院(MIT)和香港中文大學(CUHK)的研究人員提出了一個大膽的假設:“哪里有自然語言,哪里就有不嚴謹?shù)乃季S。”
基于這種假設,我們提出了一種獨特的語言生成方案:natural language embedded program (NLEP,自然語言嵌入式程序)。
OpenAI 采取了“文本補全+代碼解釋器插件”的范式,在自然語言中必要處添加代碼和插件的調用。NLEP 則通過生成可一鍵運行的程序解決一切自然語言、數(shù)學、符號推理、編程問題,只在程序中必要的地方嵌入自然語言。
在完成程序生成后,點擊“運行”按鈕,由程序打印出自然語言的回答。例如在之前的聯(lián)合國秘書長計數(shù)問題中,NLEP 生成的內(nèi)容如下:

在圖中可以看到,語言模型生成了一段逐步解決問題的程序:定義結構化知識、實現(xiàn)計算結果的函數(shù)、打印自然語言回復。完成程序的生成后,運行完整的程序,即可得到正確的結果。在五次獨立重復實驗中, GPT-4 API 的正確率為 40%,ChatGPT 代碼解釋器的正確率為 60%,而 NLEP 的正確率為 100%。
NLEP 與 ChatGPT 代碼解釋器相比有顯著的區(qū)別:
ChatGPT 以自然語言文本為主干回復用戶輸入。在生成某個詞的時候切換到代碼運行,再將代碼運行結果添加到生成的內(nèi)容里,然后繼續(xù)生成文本;而 NLEP 以程序為主干,首先生成完整的程序,然后執(zhí)行程序、打印出包含自然語言文本、圖表等要素的回復。
同時,NLEP 的編程語言框架也可以比自然語言框架更自然地鏈接數(shù)據(jù)。
相比于自然語言框架,NLEP 作為完整的可運行程序,可以更自然地鏈接知識庫和數(shù)據(jù)庫。NLEP 可以準確調用谷歌知識圖譜里的真實數(shù)據(jù),回答此前“哪個新冠變種導致了最高的 ICU 日占用率”的問題并提供數(shù)據(jù)可視化作為解釋:
NLEP 的回答是“The COVID variant caused the highest daily ICU occupation in United States is Alpha (在美國造成最高 ICU 占用的新冠病毒變種是阿爾法).”并以此生成出自動可視化數(shù)據(jù):
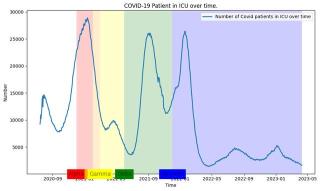
以上功能由 NLEP 的生成工具 LangCode 實現(xiàn)。
此外,NLEP 還可以自動生成結構化 Agent。
NLEP 與 ChatGPT 的本質區(qū)別在于是否采用結構化的語言生成框架。ChatGPT 以非結構化的自然語言文本補全為基本范式。因此在上周的 OpenAI 開發(fā)日,OpenAI 公布的 GPT store 也更多集中于非結構化的 agent,即 chatbot 的自動搭建。
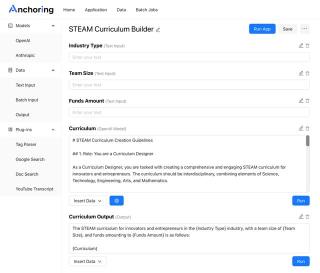
而早在 OpenAI 公布 GPT store 一個月前,我們就利用融合了符號、結構、自然語言的能力的 NLEP 為 Anchoring AI 平臺實現(xiàn)了自動生成結構化 Agent 的功能。
如圖所示,Anchoring AI Agent 可以服務結構化的輸入和輸出。其推理過程、自動生成的提示信息也顯示在自動生成的獨立模塊中,透明可控、清晰準確,便于團隊協(xié)作開發(fā)AI應用。
如 GPTs Agent:
以及根據(jù)一句自然語言指令自動生成的Anchoring.ai Agent:
 04 符號主義終將“接棒”
04 符號主義終將“接棒”經(jīng)驗主義與符號主義AI爭議紛擾六十余年,其核心矛盾在于:經(jīng)驗主義 AI 側重強大的泛化能力,而符號主義AI側重精確地推理能力。
近二十年來,拔地而起、粗放增長的 AI 研究和產(chǎn)業(yè)強調擴展 AI 的應用場景。因此,泛化能力成為了近十年 AI 的主題。尤其在 ChatGPT 橫空出世的 2022 年底,經(jīng)驗主義 AI 發(fā)展到了極致:GPT 模型有著極強的泛化性能,能夠處理非常廣泛的數(shù)據(jù)和應用。
但在后 GPT-4 時代,AI 的粗放增長會迅速來到瓶頸期,轉而進入精益發(fā)展的階段。下一個十年AI領域的主題將是精確推理、可解釋性、安全可控。依托于經(jīng)驗主義AI的堅實基礎和強大泛化能力,符號主義將接過解決AI諸多挑戰(zhàn)的重任,在未來的AI發(fā)展中大放異彩,帶來無數(shù)嶄新的可能。
甲小姐對本文亦有貢獻
*本文配圖由作者提供
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
