

 新火種
2023-11-15
新火種
2023-11-15 


最強大模型訓練芯片H200發布!141G大內存,AI推理最高提升90%
英偉達老黃,帶著新一代GPU芯片H200再次炸場。
官網毫不客氣就直說了,“世界最強GPU,專為AI和超算打造”。

聽說所有AI公司都抱怨內存不夠?
這回直接141GB大內存,與H100的80GB相比直接提升76%。
作為首款搭載HBM3e內存的GPU,內存帶寬也從3.35TB/s提升至4.8TB/s,提升43%。

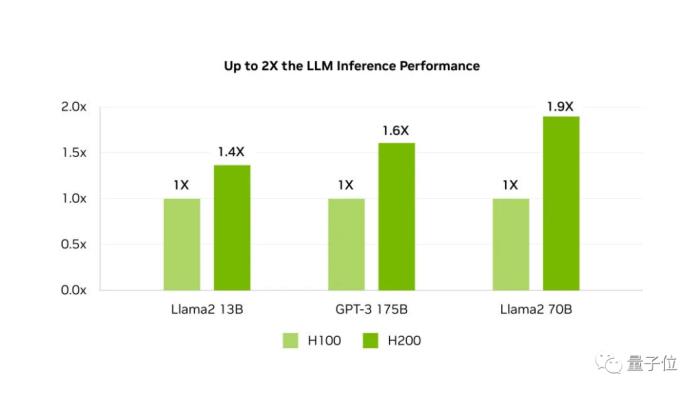
對于AI來說意味著什么?來看測試數據。
在HBM3e加持下,H200讓Llama-70B推理性能幾乎翻倍,運行GPT3-175B也能提高60%。
對AI公司來說還有一個好消息:
H200與H100完全兼容,意味著將H200添加到已有系統中不需要做任何調整。
最強AI芯片只能當半年除內存大升級之外,H200與同屬Hopper架構的H100相比其他方面基本一致。
臺積電4nm工藝,800億晶體管,NVLink 4每秒900GB的高速互聯,都被完整繼承下來。
甚至峰值力也保持不變,數據一眼看過去,還是熟悉的FP64 Vector 33.5TFlops、FP64 Tensor 66.9TFlops。
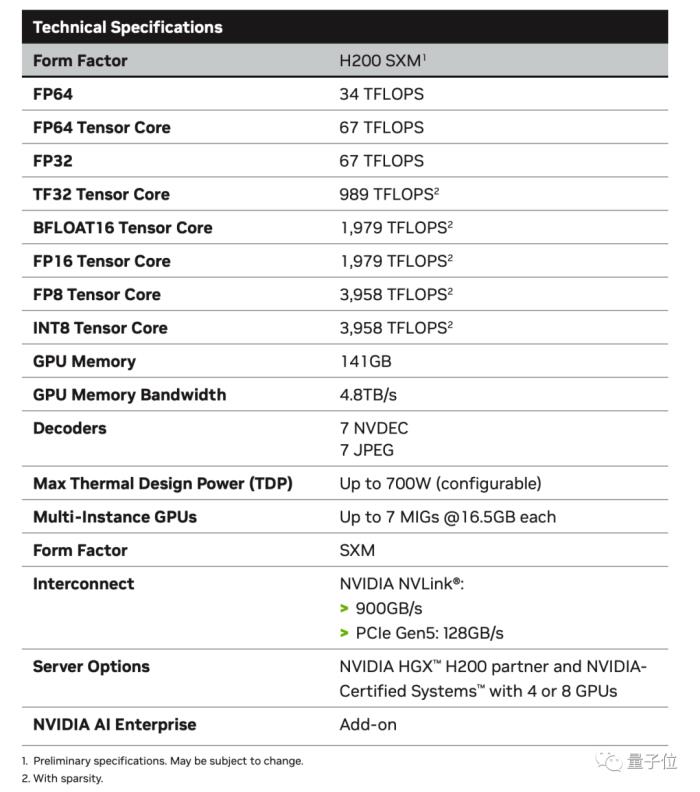
對于內存為何是有零有整的141GB,AnandTech分析HBM3e內存本身的物理容量為144GB,由6個24GB的堆棧組成。
出于量產原因,英偉達保留了一小部分作為冗余,以提高良品率。
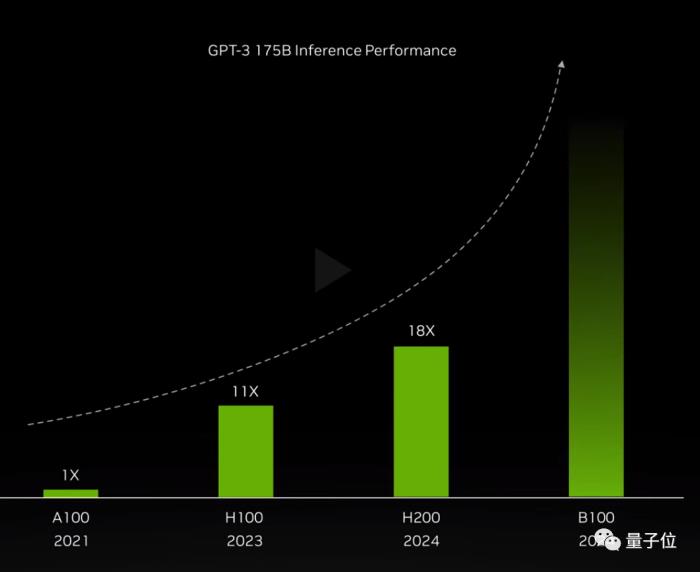
僅靠升級內存,與2020年發布的A100相比,H200就在GPT-3 175B的推理上加速足足18倍。
H200預計在2024年第2季度上市,但最強AI芯片的名號H200只能擁有半年。
同樣在2024年的第4季度,基于下一代Blackwell架構的B100也將問世,具體性能還未知,圖表暗示了會是指數級增長。
 多家超算中心將部署GH200超算節點
多家超算中心將部署GH200超算節點除了H200芯片本身,英偉達此次還發布了由其組成的一系列集群產品。
首先是HGX H200平臺,它是將8塊H200搭載到HGX載板上,總顯存達到了1.1TB,8位浮點運算速度超過32P(10^15) FLOPS,與H100數據一致。
HGX使用了英偉達的NVLink和NVSwitch高速互聯技術,可以以最高性能運行各種應用負載,包括175B大模型的訓練和推理。
HGX板的獨立性質使其能夠插入合適的主機系統,從而允許使用者定制其高端服務器的非GPU部分。

接下來是Quad GH200超算節點——它由4個GH200組成,而GH200是H200與Grace CPU組合而成的。

Quad GH200節點將提供288 Arm CPU內核和總計2.3TB的高速內存。
通過大量超算節點的組合,H200最終將構成龐大的超級計算機,一些超級計算中心已經宣布正在向其超算設備中集成GH200系統。
據英偉達官宣,德國尤利希超級計算中心將在Jupiter超級計算機使用GH200超級芯片,包含的GH200節點數量達到了24000塊,功率為18.2兆瓦,相當于每小時消耗18000多度電。
該系統計劃于2024年安裝,一旦上線,Jupiter將成為迄今為止宣布的最大的基于Hopper的超級計算機。
Jupiter大約將擁有93(10^18) FLOPS的AI算力、1E FLOPS的FP64運算速率、1.2PB每秒的帶寬,以及10.9PB的LPDDR5X和另外2.2PB的HBM3內存。

除了Jupiter,日本先進高性能計算聯合中心、德克薩斯高級計算中心、伊利諾伊大學香檳分校國家超級計算應用中心等超算中心也紛紛宣布將使用GH200對其超算設備進行更新升級。
那么,AI從業者都有哪些嘗鮮途徑可以體驗到GH200呢?
上線之后,GH200將可以通過Lambda、Vultr等特定云服務提供商進行搶先體驗,Oracle和CoreWeave也宣布了明年提供GH200實例的計劃,亞馬遜、谷歌云、微軟Azure同樣也將成為首批部署GH200實例的云服務提供商。
英偉達自身,也會通過其NVIDIA LaunchPad平臺提供對GH200的訪問。
硬件制造商方面,華碩、技嘉等廠商計劃將于今年年底開始銷售搭載GH200的服務器設備。
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
