

 新火種
2023-11-13
新火種
2023-11-13 


微美全息(NASDAQ:WIMI)推出g
資料顯示,AI視覺領先企業(yè)微美全息(NASDAQ:WIMI)一直以來都致力于推動人工智能和機器學習領域的創(chuàng)新。近日,該公司的研發(fā)團隊宣布開發(fā)一項創(chuàng)新的技術應用——Graph-Enhanced Unsupervised Meta-Training Few-Shot Node Classification (g-UMFSNC),這一技術不僅擴展了圖元學習的邊界,還解決了少鏡頭節(jié)點分類(Few-Shot Node Classification,F(xiàn)SNC)問題,為復雜任務的元學習提供了強大工具。
近年來,機器學習領域取得了巨大的進展,這部分得益于計算能力的提升、大規(guī)模數(shù)據(jù)集的可用性以及深度學習方法的興起。這些進展使得機器學習技術在各種應用領域中取得了顯著的成果,如圖像識別、自然語言處理、語音識別等。然而,盡管取得了許多成功,機器學習面臨著一系列挑戰(zhàn),其中之一是對大量標記數(shù)據(jù)的依賴。傳統(tǒng)的監(jiān)督學習方法通常需要大量標記樣本來訓練模型,這在某些情況下是不切實際的,特別是當標記數(shù)據(jù)稀缺或昂貴時,而這在實際應用中并不總是可行的。
標簽稀缺性問題在實際應用中廣泛存在。許多任務要求構建準確的機器學習模型,但是獲得足夠數(shù)量的標記數(shù)據(jù)用于訓練這些模型是一項巨大的挑戰(zhàn)。這一問題在各種領域都有所體現(xiàn),包括醫(yī)療診斷、金融風險評估、社交、生物信息、推薦系統(tǒng)等都有發(fā)生。例如,在醫(yī)療診斷領域,訓練一個準確的疾病分類模型通常需要大量的醫(yī)療圖像或病例數(shù)據(jù),但這些數(shù)據(jù)可能只在有限的情況下可用,這就導致了標簽稀缺性問題,制約了模型性能的提升。因此,少鏡頭節(jié)點分類問題是一個典型的場景,其中在訓練數(shù)據(jù)中標記節(jié)點的數(shù)量非常有限。WIMI微美全息的g-UMFSNC技術的應用可以有效解決這些問題。g-UMTRA 的技術原理建立元學習、圖神經(jīng)網(wǎng)絡、無監(jiān)督學習和圖增強等多個理論基礎之上:
元學習: 元學習是一種基于“學習如何學習”的理論。它的核心思想是模型通過從多個任務中學習,可以更好地適應新任務。通過這一理論支持 g-UMTRA 的元學習部分,使模型能夠從不同的情境中學習并提高泛化性能。
圖神經(jīng)網(wǎng)絡: 圖神經(jīng)網(wǎng)絡是處理圖結構數(shù)據(jù)的重要工具,它們能夠捕捉節(jié)點之間的復雜關系。g-UMTRA 利用圖神經(jīng)網(wǎng)絡來表示圖數(shù)據(jù),這有助于模型理解圖中的節(jié)點和邊的信息。
無監(jiān)督學習: 無監(jiān)督學習是一種學習模型從未標記的數(shù)據(jù)中提取信息的方法。g-UMTRA 利用無監(jiān)督情節(jié)生成來生成具有多樣性的情節(jié)數(shù)據(jù),這有助于模型更好地理解數(shù)據(jù)的不確定性和變化。
圖增強: 圖增強是一種通過對圖數(shù)據(jù)進行變換和擾動來生成新數(shù)據(jù)的技術。它為 g-UMTRA 提供了生成情節(jié)數(shù)據(jù)的基礎,使模型能夠從多個角度觀察和學習數(shù)據(jù)。
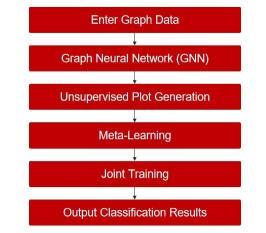
微美全息(NASDAQ:WIMI)g-UMFSNC 技術的突破之處在于它不再依賴于大量標記數(shù)據(jù)。相反,它通過無監(jiān)督的情節(jié)生成方法,使得圖元學習能夠泛化到標簽稀缺的情況,這是一個具有挑戰(zhàn)性的問題。此技術的創(chuàng)新點在于利用圖增強和鄰居查詢,使得無監(jiān)督生成的情節(jié)能夠更好地適應元學習任務。g-UMTRA 的核心原理是將無監(jiān)督情節(jié)生成與元學習相結合,以解決少鏡頭節(jié)點分類問題。它通過以下關鍵步驟實現(xiàn):
圖數(shù)據(jù)表示: 首先,將輸入的圖數(shù)據(jù)進行表示,使用圖神經(jīng)網(wǎng)絡(GNN)或其他圖嵌入技術來獲取節(jié)點的特征表示。這一步驟旨在捕捉節(jié)點之間的結構和關系信息。
無監(jiān)督情節(jié)生成: g-UMTRA 通過對抗網(wǎng)絡,無監(jiān)督學習。它使用圖增強技術,通過對訓練集中的圖數(shù)據(jù)進行多次增強,生成一系列的情節(jié)(episode)。每個情節(jié)是原始圖數(shù)據(jù)的隨機變化版本,但保持了數(shù)據(jù)的拓撲結構。這些情節(jié)包含了數(shù)據(jù)的不同視角和變化。
元學習: 接下來,使用生成的情節(jié)數(shù)據(jù)進行元學習。元學習是一種學習-to-learn 的方法,目的是使模型能夠快速適應新任務。在 g-UMTRA 中,每個情節(jié)被視為一個元任務,模型在每個情節(jié)上進行少鏡頭節(jié)點分類的訓練。這種方式迫使模型從多個情境中學習,并提高了其泛化能力。
聯(lián)合訓練: 最后,將無監(jiān)督生成的情節(jié)數(shù)據(jù)和元學習任務一起進行聯(lián)合訓練。這意味著模型在生成的情節(jié)數(shù)據(jù)上進行訓練,同時也進行少鏡頭節(jié)點分類的元學習任務。這使模型能夠充分利用情節(jié)數(shù)據(jù)的信息,提高對標簽稀缺情況的泛化性能。
WIMI微美全息g-UMTRA 的技術原理建立在元學習、圖神經(jīng)網(wǎng)絡、無監(jiān)督學習和圖增強等多個理論基礎之上,這些理論基礎共同支撐了這一技術的有效性和泛化能力。通過將這些原理和理論結合在一起,g-UMTRA 為少鏡頭節(jié)點分類問題提供了一種新穎而強大的解決方案,使機器學習模型能夠更好地應對標簽稀缺性和復雜的圖數(shù)據(jù)任務。
WIMI微美全息g-UMFSNC 技術的開發(fā)源于對圖元學習和元學習領域的深刻理解,以及對標簽稀缺性問題的現(xiàn)實挑戰(zhàn)的認識。相信,g-UMFSNC這一技術的推出,可以為各種應用領域提供更強大的工具,幫助解決現(xiàn)實世界中的復雜問題。比如在社交網(wǎng)絡中g-UMTRA 技術可以用于更準確地識別和分類社交網(wǎng)絡中的用戶,尤其是在標簽數(shù)據(jù)有限的情況下。在推薦系統(tǒng)上商品或內(nèi)容分類是一個關鍵任務,尤其是在涉及大量未標記物品時,g-UMTRA 可以提高推薦系統(tǒng)的分類準確性和個性化程度。在醫(yī)療、金融領域都將有很好的應用。這一技術的誕生是機器學習領域持續(xù)創(chuàng)新的一部分,在未來將可在解決各種復雜問題中應用。
免責聲明:此文內(nèi)容為本網(wǎng)站轉載企業(yè)資訊,僅代表作者個人觀點,與本網(wǎng)無關。所涉內(nèi)容不構成投資、消費建議,僅供讀者參考,并請自行核實相關內(nèi)容。
原文轉自:信陽日報相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關的任何行動之前,請務必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
