

 新火種
2023-11-11
新火種
2023-11-11 


生成式AI落地,有沒有「萬能公式」?

年初看到ChatGPT掀起生成式AI熱潮時,螞蟻集團百靈代碼大模型(開源名稱CodeFuse)負責人技術總監李建國迫不及待地想找合作伙伴NVIDIA聊聊。
李建國所在的辦公樓與NVIDIA北京辦公室僅一路之隔,步行幾分鐘就能到達。
來到NVIDIA北京辦公室,接待李建國的是NVIDIA開發與技術部門亞太區總經理李曦鵬。
兩位AI圈里的資深人士一見面,就討論起了生成式AI落地的工程化問題。更具體的說,是CodeFuse的推理加速。
與GitHub在3月份發布的代碼編寫助手Copilot X類似,CodeFuse是螞蟻集團自研的代碼生成專屬大模型。
算法和應用優化是李建國團隊擅長的。算法和應用層優化完成之后,CodeFuse的體驗還是不夠理想,需要擅長底層硬件和軟件的NVIDIA幫忙。
自從年初的那次見面之后,李建國的團隊和李曦鵬的團隊不僅有了雙周會,有時候問題很緊急,周末還會有臨時的會議,目標就是讓CodeFuse的體驗達到理想狀態。
靠著兩個團隊相互的信任和支持,CodeFuse突破了推理中的量化難題,在大幅節省推理的成本的同時,極大提升了使用體驗。
如今,借助CodeFuse,簡單幾條文字指令就能在線制作貪吃蛇小游戲,CodeFuse距離為程序員提供全生命周期AI輔助工具的目標越來越近,變革也將悄然而至。
“傳統的軟件研發人員的思維需要做一些改變。”李建國認為這是生成式AI將帶來的變化。
這種變化未來將發生在千行百業,“有了大模型,接下來就是如何把這些模型“變小”,讓它在各種環境中應用。今年底或者明年初,會有大量AI推理的需求。”李曦鵬判斷。
螞蟻集團和NVIDIA一起摸索出了生成式AI落地的路徑,這兩家走在生成式AI最前列的公司同時做了一件對整個AI業界非常有價值的事情,將合作的細節和成果開源到NVIDIA TensorRT-LLM社區。
這給正在探索AI推理加速的團隊提供了一個參考,即便這不是萬能公式,但一定能激發AI創新,也將加速AI無處不在的進程。
單打獨斗很難落地大模型
想要占領生成式AI時代的先機,即便是業界領先的公司,靠單打獨斗還不夠,和生態伙伴合作成了必選項。
“螞蟻集團和業界一樣,對于研發效率的提升都有非常大的訴求,這是我們研發CodeFuse的初衷。”李建國對說,“去年開始,我們就開始用插件的方式來提升研發效率,后來ChatGPT讓我們意識到我們不僅可以通過插件的方式提升效率,還可以借助大模型讓CodeFuse有更多的功能。”
有探索精神的螞蟻集團去年開始自研的代碼生成專屬大模型,要實現根據開發者的輸入,幫助開發者自動生成代碼、自動增加注釋、自動生成測試用例、自動修復和優化代碼、自動翻譯代碼等,達到提升研發效率的終極目標。
簡單說,CodeFuse的目的是重新定義下一代AI研發,提供全生命周期AI輔助工具。
上半年,螞蟻從0訓練了多個十億和百億級參數的CodeFuse代碼大模型訓練,CodeFuse又適配加訓了一系列開源模型,比如LLaMA、LLaMA-2、StarCoder、Baichuan、Qwen、CodeLLaMA等。
圖片來自github
訓練好的模型到了推理落地階段,出現了不一樣的難題。
“模型的推理部署分很多層,有最底層的軟件優化,往上還有算法優化和服務優化。”李建國知道,“算法和服務優化是自己團隊擅長的,底層的軟件優化我們也能做,但最好的選擇還是NVIDIA。”
之所以說NVIDIA是最好的選擇,有兩方面的原因,一方面是因為李建國和他的團隊在通過插件提升研發效率的時候,經過綜合評估,選擇了最適合他們的NVIDIA開源項目FasterTransformer。“為了實現一些定制化功能,我們為開源端口貢獻了上千行代碼。”李建國團隊超前的需求沒得到完全的滿足,需要和NVIDIA有更深度的合作。
另一方面,作為GPU加速硬件提供方,NVIDIA更加擅長結合底層的硬件和軟件優化,強強聯合能更快速探索出AI推理的路徑。
這個合作其實是典型的雙向奔赴,CodeFuse遇到落地難題的時候,NVIDIA也非常需要螞蟻集團一起協同設計出好產品。
FasterTransformer是NVIDIA2018年推出的開源項目,目標是解決生成式AI模型推理的問題,2018年之后AI技術有了很大的進步,但FasterTransformer為了效率,很多實現寫得比較固定,2023年則走到了產品轉型的時期。
“螞蟻集團非常有探索精神,從FasterTransformer到如今的TensorRT-LLM,螞蟻集團都是我們最早的用戶和貢獻者,也最早提出了需求,TensorRT-LLM有很多我們的協同設計。”李曦鵬深深感受到螞蟻集團的信任。
對于NVIDIA這家數據中心級全棧AI平臺公司,面對每年各類AI國際學術會議上,成千上萬篇論文討論AI的訓練和推理加速,要兼顧所有方向其實不太容易,只有和最終的用戶合作,才能最大化NVIDIA軟硬件的價值。
通過與客戶合作,將其正向需求結合到產品迭代,NVIDIA從而在今年正式推出了加速大模型推理的開源解決方案NVIDIA TensorRT-LLM,TensorRT-LLM提供了Python接口,有靈活的模塊化組件,豐富的預定義主流模型,能夠極大地方便開發者在NVIDIA平臺上部署基于大模型的服務。
圖片來自NVIDIA官網
大模型推理落地的關鍵——低成本,大吞吐量
螞蟻集團的CodeFuse從訓練到推理,NVIDIA的AI推理加速方案從FasterTransformer到TensorRT-LLM,雙方要一起解決的是低延遲的響應,還有能回答更長的問題。
“自動生成代碼特別是在IDE里面的代碼補全對延時有很高要求,如果代碼一個字符一個字符蹦出來,程序員肯定受不了,一般來說代碼補全的響應時間在200毫秒以下才會有好的體驗,更長的時延程序員一般受不了。”李建國指出了CodeFuse落地的一個難題。
解決這個問題的一個好辦法是量化。模型量化,就是將使用高精度浮點數比如FP16訓練的模型,使用量化技術后,用定點數比如INT4表達。量化的關鍵點是對齊兩個精度(FP16和INT4)的輸出,或者說讓兩個精度輸出的數據分布盡可能保持一致。量化的好處是可以有效的降低模型計算量、參數大小和內存消耗,提高處理吞吐量。
“我們內部做了一些評估,8比特量化損失的精度比較少,基本是無損,同時可以帶來30%左右的加速。如果是量化到4比特,一般量化方法的精度損失會達到7-8%,但如果能把精度損失做到1%以內,可以帶來2倍左右的加速。”李建國說,“要實現量化到4比特的同時精度損失小于1%,我們需要在核心的算法層面創新,也同時需要NVIDIA TensorRT-LLM的軟件優化確保推理加速。”
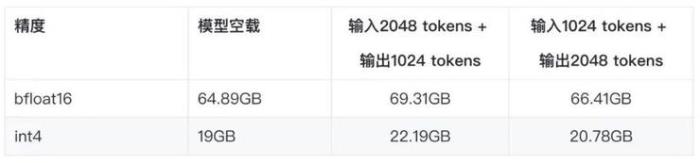
量化的價值顯而易見,CodeFuse-CodeLLama-34B模型在FP16和INT8精度下,至少需要4張A10 GPU做最小配置部署。量化到INT4之后,模型占用顯存從64.9G顯著減小到19G,一張A10 GPU即可部署。
從需要4張A10減少到只需要1張A10,成本的降低顯而易見,速度也讓人滿意。
使用GPTQ或者NVIDIA TensorRT-LLM early access版本量化部署,實測發現A10上的INT4優化后的推理速度,已經和A100上FP16推理速度持平。
在程序生成的HumanEval評測和幾個NLP任務(CMNLI/C-EVAL)的評測中表現也非常出色。
結果讓人滿意,但過程中難免出現意外,李建國和團隊同事將CodeFuse量化部署到A100運行正常,但部署到A10 GPU上時,輸出出現了亂碼,但沒有找到問題根因,而此時恰逢周末。
“了解到我們的問題之后,NVIDIA的伙伴說可以馬上來幫我們一起解決問題。”李建國印象深刻,“后來NVIDIA的伙伴發現其實問題很簡單,就是容器的一個配置錯了,物理機并沒有問題,改完容器的配置就正常了。”
李曦鵬對這件事情也印象深刻,“周末一起調試,是建立在雙方通過長期合作信任的基礎上。彼此愿意相信,相互協同才能更快達成目標。”
想要達到雙方技術團隊默契配合,必須要有充分的溝通和信任,還要有優先級。
“為了快速響應螞蟻集團的需求,以前我們的軟件更新一般3個月才更新一次,現在不到一個月就會給他們一版。”李曦鵬感嘆這種變化,“我們的代碼拿過去也會有bug,螞蟻的伙伴給了我們包容。”
至于如何適應客戶的快節奏,李曦鵬認為關鍵在于要有優先級,“NVIDIA所有產品,最重要的優先級都來自于客戶的需求。”
對于AI推理來說,與量化一樣影響體驗的是推理長度。
更大的推理長度意味著用戶可以一次性輸入更長的文檔,也可以實現多輪對話,目前業界標準的推理輸入長度是4K、16K,并朝著1Million的長度在努力。
CodeFuse-CodeLLama-34B模型目前在A10上,4比特量化支持總長為3K+長度的輸入和輸出。
“如果只是單純加長輸入長度,挑戰非常大,因為計算量需求會出現O(n^2)增長。”李曦鵬介紹。
要解決客戶的問題,還要求NVIDIA有極強的技術敏感度和技術創新能力。“最近有一個Flash-Decoding的技術,可以更好的加速長序列的推理。而實際上,我們早已經在TensorRT-LLM中獨立的實現了這個特性,叫做multi-block mode,目前還在對更多模型進行測試,下個版本會放出來。”李曦鵬表示。
李建國有些驚喜,“上周末知道TensorRT-LLM已經支持Flash-decoding時非常開心,NVIDIA有前瞻性,能夠快速支持最新的技術,這對于提升CodeFuse的體驗非常重要。”
螞蟻集團和NVIDIA依舊在繼續優化CodeFuse的部署,目標就是提供低成本、低時延、高吞吐量的AI大模型使用體驗。
CodeFuse正在變得越來越強大,這會帶來一個問題,AI會帶來怎樣的變革?
大模型落地沒有萬能公式,但很快會無處不在
就像電剛發明的時候人們會擔心會產生事故一樣,大模型也處于這樣的時刻。“未來五年或者十年,人工智能大模型會深入我們生活的各個角落。”這是李建國的判斷。
就拿他在負責的CodeFuse來說,軟件研發人員的思維需要前移或者后移,前移的意思是要考慮整個APP的概念設計、創意,后移是考慮APP后續的運維和增長。
“當寫重復代碼的工作被AI提效之后,軟件研發人員有更多時間需要思考更復雜、更有創意的東西。而不僅僅只是關心算法、數據,要去兼顧更多內容,要有技能的增長。”李建國觀察認為,“前端設計比較標準化,可能會更快受到影響。”
“但現在看來AI依舊是提升效率的輔助工具。”李建國和李曦鵬都認為。
這種影響會隨著AI模型的成熟逐步影響到越來越多行業和領域。螞蟻集團和NVIDIA就將其在CodeFuse方面的合作進行了非常細節的開源,這對于TensorRT-LLM開源社區來說是一個巨大的貢獻,也將深刻影響生成式AI的落地和普及。
比如生成式AI落地部署非常關鍵的量化,有NVIDIA和螞蟻集團實踐開源的例子,基于TensorRT-LLM量化就會更加容易。
“論文介紹了一些方法,但還需要算法工程師針對具體的場景和模型去做調整和測試的。”李曦鵬說,“NVIDIA要做的是做好絕大部分底層的工作,讓整個業界在此基礎上做更多的創新。”
李建國看到了開源對于AI無處不在的重要價值,“就像數學分析里有個萬能公式,它不是所有場景都能用,但開源可以讓更多的場景使用,相當于普惠大眾。”
李曦鵬表示,TensorRT-LLM開源兩周,就有超過200個issue,大家熱情非常高漲。
NVIDIA也在通過2023 TensorRT Hackathon生成式AI模型優化賽這樣的賽事完善TensorRT-LLM,加速生成式AI的落地和普及。
比爾·蓋茨曾說,“我們總是高估未來兩年的變化,低估未來10 年的變革。”
以CodeFuse為例,NVIDIA和螞蟻集團的合作和成果,將會對未來10年的變革產生深遠影響。
Tags:
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
