

 新火種
2023-10-29
新火種
2023-10-29 


AlexeiEfros團隊發布BlobGAN:靈活組合物體的布局與外形特征

作者丨OGAI
編輯丨陳彩嫻計算機視覺是人工智能技術的重要應用方向。在深度學習時代,大量以 ImageNet 為代表的數據集被用于訓練各種視覺理解模型,從而完成圖像分類、目標檢測、圖像分割、場景理解等任務。在 ImageNet 數據集中,物體往往單獨出現在圖像的中央區域。然而,真實的視覺世界則要豐富得多。

圖 1:ImageNet 數據集
對于人類視覺和計算機視覺而言,在場景的上下文中理解、建模對象是最重要的任務之一。在人類文明發展的長河中,藝術家們逐漸掌握了場景形成的規則,并發展出了超現實主義等藝術流派,能夠熟練打破這些規則。他們能夠對場景中的各種視覺元素進行解構、重組、藝術化加工,從而創作出新穎而又能夠被人類所理解的藝術作品。
 圖 2:超現實主義畫作——《記憶的永恒》
圖 2:超現實主義畫作——《記憶的永恒》遺憾的是,在深度學習時代,面向分析和合成任務的場景建模并沒有得到足夠的重視。有時,我們采用和對象建模類似的自頂向下方式建模場景,例如:對于 GAN 或圖像分類器而言,「臥室」和「廚房」等場景類別的表征方式與「床」或「椅子」的表征方式類似。有時,我們又采用和語義分割任務類似的自底向上的方式為圖像中的每一個像素賦予語義標簽。
然而,對于場景理解而言,上述兩種方法都不盡如人意,它們無法將場景中的各個部分作為實體,從而進行簡單的推理。場景中的部分要么被融合為一個耦合的潛向量(自頂向下),要么需要根據獨立的像素標簽聚合在一起(自底向上)。
為此,在資深計算機視覺學者 Alexei A.Efros 教授的指導下,來自 UC Berkeley 和 Adobe 的研究人員近期發布了論文「BlobGAN: Spatially Disentangled Scene Representations」,為場景生成模型提供了一種介于像素和圖像之間的無監督中間表征。在該工作中,研究者們將場景建模為在空間、深度上有序的高斯 Blob 連通區域的集合。
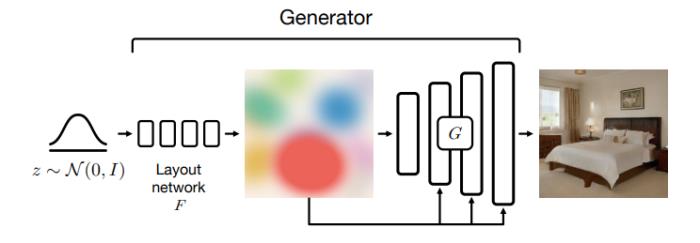
圖 3:BlobGAN 模型架構
如圖 3 所示,這些 Blob 的集合處于生成器架構的「瓶頸」處,迫使每個 Blob 對應于場景中的一個特定對象,從而產生在空間上解耦的表征。如圖 4 所示,在該模型的幫助下,我們可以在沒有語義監督的情況下完成許多場景編輯任務。
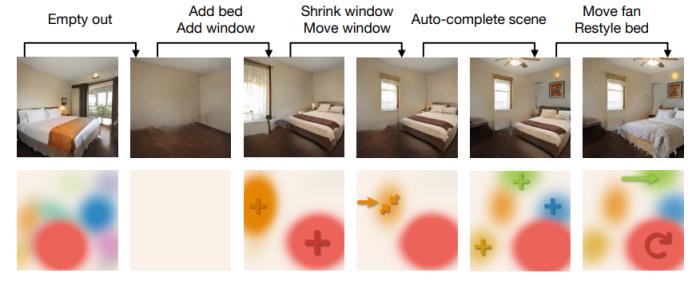
圖 4:利用 BlobGAN 完成的場景編輯任務。
該項目的地址為:https://dave.ml/blobgan/目前,該工作在 Reddit 上引起了熱議,許多網友們紛紛為 BlobGAN 的驚人表現而折服。
神奇的 BlobGAN 是如何煉成的?
BlobGAN 的實現方法充分體現了深度學習和基于手工設計的傳統計算機視覺方法的結合。如圖 1 所示,在 BlobGAN 中,滿足標準正太分布的隨機噪聲 z 會被輸入給一個布局網絡 F,布局網絡會將噪聲映射為一組描述 Blob 的參數 β(見圖 5)。Blob 可以作為一種強大的中間生成表征。接著,我們將 Blob 可微地描繪在空間網格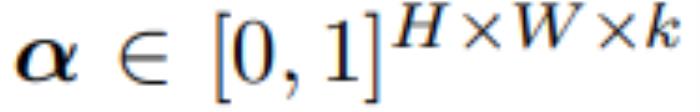 上,該網格也描述了 Blob 的透明度。接著,我們利用一個類似于 StyleGAN2 的解碼器 G 將其轉化為逼真、和諧的圖像。我們使用一個不會被修改的判別器在對抗框架下訓練模型。在沒有顯式標簽的情況下,我們的模型可以學會將場景中的實體及其布局解耦開來。
上,該網格也描述了 Blob 的透明度。接著,我們利用一個類似于 StyleGAN2 的解碼器 G 將其轉化為逼真、和諧的圖像。我們使用一個不會被修改的判別器在對抗框架下訓練模型。在沒有顯式標簽的情況下,我們的模型可以學會將場景中的實體及其布局解耦開來。
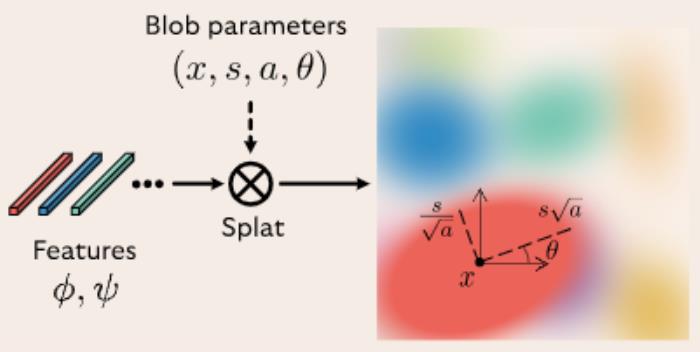 圖 5:Blob 的構建方法示意圖。
圖 5:Blob 的構建方法示意圖。算法細節
具體而言,橢圓 Blob 的參數包含 Blob 的中心坐標 x ∈ [0, 1]^2、尺度 s ∈ R、縱橫比 a ∈ R、旋轉角度 θ ∈ [?π, π]。每個 Blob 都帶有一個結構特征  和風格特征
和風格特征 ,我們在將 Blob 轉換為 2D 特征網格時會用廣播的矩陣乘法操作將兩個特征向量。Blob 表征可寫作:
,我們在將 Blob 轉換為 2D 特征網格時會用廣播的矩陣乘法操作將兩個特征向量。Blob 表征可寫作:
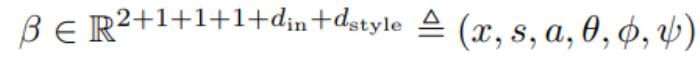
在得到了 Blob 后,我們以 StyleGAN2 為基礎構建了生成器 G 將 Blob 轉換為真實、和諧的圖像。在這里,我們基于 Blob 的結構特征采用了歲空間變化的輸入張量,而不是單一、全局的向量,并進行了隨空間變化的調制。標準的 StyleGAN 要求每個風格向量 w 必須囊括場景所有方面的信息,而 BlobGAN 則可以將布局和外觀解耦開。
直觀地說,Blob 內的所有激活值都由相同的特征向量控制,促使 Blob 產生自相似屬性的圖像區域(場景中的實體)。此外,由于卷積是局部的,輸入中的 Blob 的布局必須很強地包含圖像區域的最終組織的信息。最后,我們的潛空間通過構造過程將 Blob 的布局與外觀解耦。這有助于我們的模型學會將單個 Blob 與不同的對象綁定,并將這些 Blob 組織到合理的布局中,從空間上將場景分解為一系列組成部分。
BlobGAN 的威力
BlobGAN 學習到的表征可以從空間上解耦場景。下面,我們分別從定量和定性的角度展示 BlobGAN 如何將 Blob 與場景中的某個目標對應起來,并展示學到的表征如何捕獲場景布局的分布。
如圖 4 所示,我們對模型生成的圖像的 Blob 圖進行一系列的修改,例如:清空場景中的實體、增加床和窗戶、縮小窗戶、移動窗戶、自動補全場景、移動吊扇、改變床的風格。BlobGAN 可以靈活地編輯場景。
場景編輯可視化結果
具體而言,BlobGAN 可以將復雜的場景圖像分解為組成它們的物體。無監督表征使我們可以很容易地在場景中重新排列、移除、克隆和重塑物體。如圖 6 所示,通過修改某些 Blob 的坐標,重新組織臥室中的家具。由于表征是分層的,我們可以建模家居之間的遮擋關系。

圖 6:移動 Blob 從而重新組織物體
圖 7 展示了從表征中完全刪除某些 Blob 的影響。盡管在訓練數據中,沒有床的臥室非常罕見,但通過移除相應的 Blob,可以將床從場景中移除。我們也可以以同樣的方式移除窗戶、燈具和風扇、畫作、梳妝臺和床頭柜。

圖 7:移除 Blob
BlobGAN 生成的表征使我們可以進行跨圖像的編輯。在圖 8 中,我們通過交換 Blob 的風格向量高度模塊化地重新裝配了場景。例如,在不改變布局的情況下,我們將某一場景下的床單風格與另一場景下的床單風格交換。

圖 8:交換 Blob 風格
如圖 9 所示,如果我們想要引入新的 Blob,可以在新的位置上復制粘貼相同的 Blob,形成新的布局。

圖 9:復制粘貼 Blob
定量的 Blob 分析
Blob 和場景中的實體具有很強的關聯。我們通過將 Blob 的尺寸參數 s 隨機設置為負數來刪除它。然后,我們使用分割模型觀察消失的語義類。圖 10(左)展示了類和 Blob 之間的相關性。該矩陣十分稀疏,這表明 Blob 隨著學習專門對應到不同的場景實體。圖 10(右)展示了 Blob 的中心的分布。合成的熱力圖展示了訓練數據中物體的分布。模型會學著在特定的圖像區域定位 Blob,通過改變風格向量控制表征的物體。
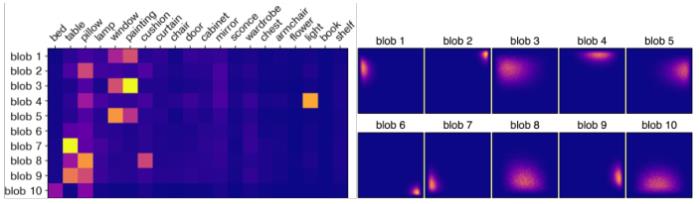 圖 10:Blob 的空間偏好屬性
圖 10:Blob 的空間偏好屬性將 Blob 組合到布局中
除了將圖像分解為若干部分,理想的場景表征還需要捕獲各部分之間豐富的上下文關系,這些關系決定了場景的生成過程。BlobGAN 的表征可以顯式地發現場景中物體的布局。
在測試時,我們通過求解一個簡單的約束優化問題,可以對滿足底層場景約束的展示圖像進行采樣,進行「場景自動補全」。如圖 11 所示,不同的空房間具有各自的背景向量 ,以及由潛變量 z 生成的裝飾,我們通過優化合理地裝飾場景,使之與背景向量相匹配。
,以及由潛變量 z 生成的裝飾,我們通過優化合理地裝飾場景,使之與背景向量相匹配。

圖 11:生成并填充空房間。
通過使用布局網絡 F 對滿足 Blob 參數子集約束的不同場景進行采樣,我們可以進行帶條件的場景自動生成/補全。圖 12 展示了特定布局條件下的風格生成、根據床和梳妝臺的位置和大小預測可信的場景。比起使用 F 自動補全場景,我們還可以生成一個隨機的場景并簡單地替換感興趣的參數以匹配所需的值。我們可以對場景進行物體的插入、移除、方向調整。

圖 12:場景自動補全
我們通過替換目標圖像中的屬性來編輯圖像,這些屬性要么是隨機生成的,要么是使用模型進行條件采樣得來的。通過改變網絡深度,我們切換 StyleGAN 中的風格。為了進一步保持全局布局并提高一致性,我們的模型還可以使用源圖片中的結構網格 Φ。我們通過 FID 來評估模型生成樣本的多樣性和質量。在所有情況下,BlobGAN 的場景自動補全性能都優于基線。
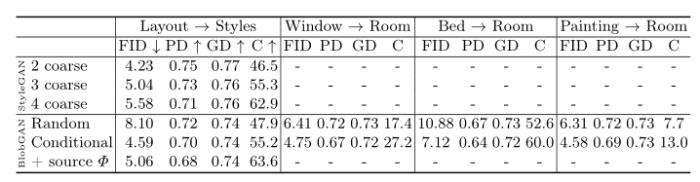
表 1:自動補全的定量分析結果
BlobGAN 可以在 LSUN 房間中獲得與 StyleGAN 相媲美的視覺質量。BlobGAN 生成的樣本更加逼真。
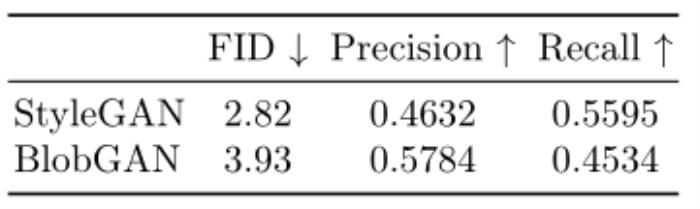
表 2:評估視覺質量和多樣性
區域級圖像解析
BlobGAN 得到的表征還可以通過將圖像反演到 Blob 空間來解析這些真實圖像。我們可以移除并重新定位真實圖像中的物體,發現其與原始圖像的差異。

圖 13:通過反演解析真實圖像
參考鏈接:https://www.reddit.com/r/artificial/comments/umhmcc/blobgan_enables_object_manipulation_in_an_image/

相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
