

 新火種
2025-05-20
新火種
2025-05-20 

個人開發(fā)者訓(xùn)400億參數(shù)大模型:分布式算力,DeepSeek架構(gòu),3090單卡部署
打破科技巨頭算力壟斷,個人開發(fā)者聯(lián)手也能訓(xùn)練超大規(guī)模AI模型?
Nous Research宣布推出Psyche Network,可以將全球算力整合起來訓(xùn)練強(qiáng)大的人工智能。
Psyche是一個基于Deepseek的V3 MLA架構(gòu)的去中心化訓(xùn)練網(wǎng)絡(luò),測試網(wǎng)首次啟動時直接對40B參數(shù)LLM進(jìn)行預(yù)訓(xùn)練,可以在單個H/DGX上訓(xùn)練,并在3090 GPU上運(yùn)行。

以往類似規(guī)模的模型訓(xùn)練往往需要耗費(fèi)大量的資源和時間,并且通常是由大型科技公司或?qū)I(yè)研究機(jī)構(gòu)憑借其雄厚的資金和算力優(yōu)勢來完成的。
Psyche的出現(xiàn)讓個人和小團(tuán)體也可獲取資源創(chuàng)建獨(dú)特大規(guī)模模型。

對此,有網(wǎng)友表示,Nous Research有潛力成為新的前沿AI實(shí)驗(yàn)室。
 技術(shù)突破和網(wǎng)絡(luò)架構(gòu)DisTrO優(yōu)化器
技術(shù)突破和網(wǎng)絡(luò)架構(gòu)DisTrO優(yōu)化器在傳統(tǒng)AI訓(xùn)練中,數(shù)據(jù)需在中心服務(wù)器與分布式GPU之間高頻傳輸,帶寬不足會導(dǎo)致GPU利用率暴跌。
2024年Nous研發(fā)的DisTrO分布式訓(xùn)練優(yōu)化器,通過梯度壓縮(僅傳輸關(guān)鍵參數(shù)更新)和異步更新策略,將跨節(jié)點(diǎn)通信的數(shù)據(jù)量降低90%以上,突破了訓(xùn)練過程中的帶寬限制,使得訓(xùn)練可以去中心化。
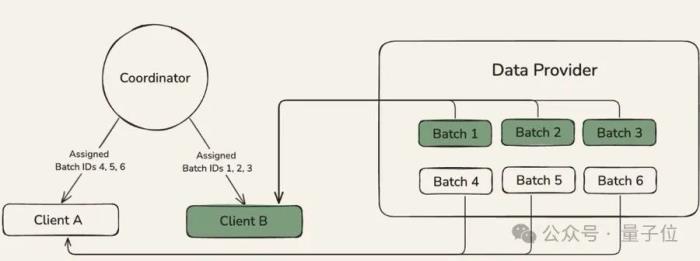 點(diǎn)對點(diǎn)網(wǎng)絡(luò)堆棧
點(diǎn)對點(diǎn)網(wǎng)絡(luò)堆棧Psyche創(chuàng)建了一個自定義的點(diǎn)對點(diǎn)網(wǎng)絡(luò)堆棧,用于協(xié)調(diào)全球分布式GPU運(yùn)行DisTrO。
這個基于P2P(點(diǎn)對點(diǎn))協(xié)議的專用網(wǎng)絡(luò)層,無需依賴中心化服務(wù)器協(xié)調(diào),全球GPU可直接通過加密通道交換梯度數(shù)據(jù)。
這一設(shè)計(jì)徹底擺脫了對傳統(tǒng)云服務(wù)商高帶寬網(wǎng)絡(luò)的依賴,即使是家用寬帶連接的GPU,也能穩(wěn)定參與訓(xùn)練。
系統(tǒng)架構(gòu)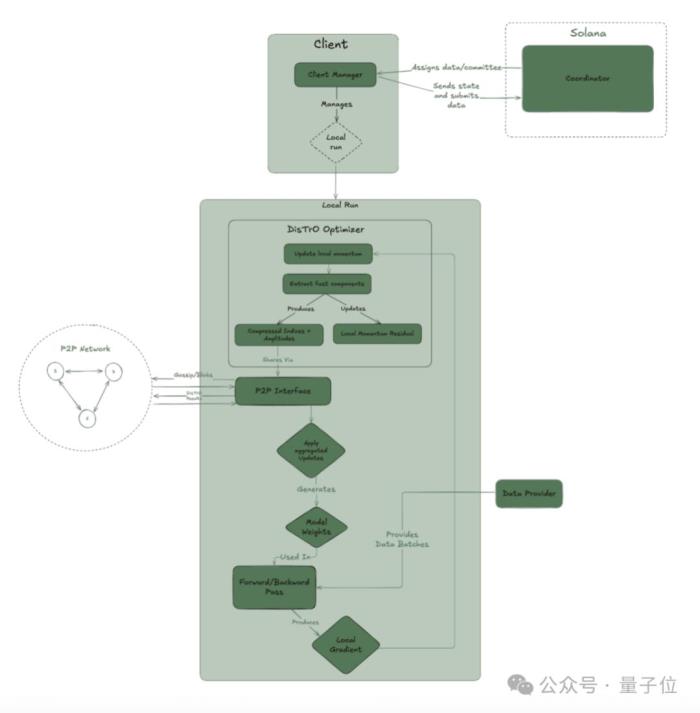
Psyche網(wǎng)絡(luò)架構(gòu)有三個主要部分:
coordinator:協(xié)調(diào)器,存儲有關(guān)訓(xùn)練運(yùn)行狀態(tài)和參與者列表的元數(shù)據(jù)。處理一輪訓(xùn)練中每個階段之間的轉(zhuǎn)換,且負(fù)責(zé)為運(yùn)行中的所有客戶端提供同步點(diǎn)。
clients:客戶端,負(fù)責(zé)訓(xùn)練、見證和驗(yàn)證。每個客戶端都保持自身狀態(tài)與協(xié)調(diào)器同步。
data provider:負(fù)責(zé)提供訓(xùn)練所需的數(shù)據(jù)。可以是本地的也可以是HTTP或 CP提供者。
40B參數(shù)LLM預(yù)訓(xùn)練此前互聯(lián)網(wǎng)公開的大規(guī)模預(yù)訓(xùn)練多由Meta、Google等巨頭主導(dǎo)(如LLaMA 2的700億參數(shù)模型),Psyche以去中心化模式實(shí)現(xiàn)同等級別訓(xùn)練。

Psyche首次測試網(wǎng)運(yùn)行使用的是Deepseek的V3 MLA架構(gòu)。
MLA通過低秩聯(lián)合壓縮鍵值和矩陣分解技術(shù),降低計(jì)算復(fù)雜度與內(nèi)存占用,使 400 億參數(shù)大語言模型在有限算力下高效訓(xùn)練。
多頭注意力機(jī)制與潛空間表示學(xué)習(xí)相結(jié)合,提升模型語言理解與生成能力;并且,旋轉(zhuǎn)位置嵌入的運(yùn)用,有效解決長序列位置依賴問題,從多維度保障了訓(xùn)練的高效性與模型性能的優(yōu)質(zhì)性。
數(shù)據(jù)集:
使用了FineWeb(14T)、去除部分不常見語言的FineWeb-2(4T)和The Stack v2(1T),些數(shù)據(jù)集涵蓋豐富信息,為模型訓(xùn)練提供了有力支持。
分布式訓(xùn)練策略:
模型并行與數(shù)據(jù)并行結(jié)合:將400億參數(shù)拆解為128個分片,分布在不同節(jié)點(diǎn)進(jìn)行 “模型并行” 訓(xùn)練,同時每個節(jié)點(diǎn)處理獨(dú)立的數(shù)據(jù)批次(“數(shù)據(jù)并行”),通過DisTrO優(yōu)化器同步梯度更新。動態(tài)自適應(yīng)批量大小:根據(jù)節(jié)點(diǎn)網(wǎng)絡(luò)延遲自動調(diào)整每個批次的訓(xùn)練數(shù)據(jù)量(如高延遲節(jié)點(diǎn)使用較小批次,減少等待時間),使全局訓(xùn)練效率提升25%。未來將是分布式訓(xùn)練的天下?隨著AI模型參數(shù)規(guī)模呈指數(shù)級增長,傳統(tǒng)集中式訓(xùn)練模式正面臨算力壟斷、成本高昂和擴(kuò)展性瓶頸的嚴(yán)峻挑戰(zhàn)。
分布式訓(xùn)練的崛起,正在徹底改寫這一格局。
就在幾天前,Prime Intellect發(fā)布了首個分布式RL訓(xùn)練模型INTELLEC-2,引起了廣泛關(guān)注。
Nous Research也稱Psyche初始訓(xùn)練只是起點(diǎn),后續(xù)計(jì)劃整合監(jiān)督微調(diào)、強(qiáng)化學(xué)習(xí)等完整的訓(xùn)練后階段工作,以及推理和其他可并行工作負(fù)載。
誰能站穩(wěn)分布式訓(xùn)練擂臺?當(dāng)然,我們期待更多更優(yōu)秀的成果~
感興趣的小伙伴可以到官方查看更加詳細(xì)的內(nèi)容。博客:https://nousresearch.com/nous-psyche/訓(xùn)練儀表板:https://psyche.network代碼:https://github.com/PsycheFoundation/psyche文檔:https://docs.psyche.network論壇:https://forum.psyche.networkHuggingFace:https://huggingface.co/PsycheFoundationDiscord:https://discord.com/invite/jqVphNsB4H參考鏈接:[1]https://x.com/NousResearch/status/1922744494002405444[2]https://x.com/PrimeIntellect/status/1921730059620196772
— 完 —
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
