

 新火種
2025-05-16
新火種
2025-05-16 


梁文鋒署名DeepSeek新論文:公開V3大模型降本方法
梁文鋒親自參與的DeepSeek最新論文,來了!
這一次,團(tuán)隊把DeepSeek-V3在訓(xùn)練和推理過程中,如何解決“硬件瓶頸”的方法公布了出來。

具體而言,DeepSeek-V3之所以可以只用2048塊H800,就能達(dá)到超大規(guī)模集群(如數(shù)萬塊GPU)相當(dāng)?shù)挠?xùn)練效果,核心在于四項創(chuàng)新技術(shù):
內(nèi)存優(yōu)化多頭潛在注意力(MLA)計算優(yōu)化混合專家模型(MoE)與FP8低精度訓(xùn)練通信優(yōu)化多層網(wǎng)絡(luò)拓?fù)渑c低延遲設(shè)計推理加速多token預(yù)測(MTP)
那么這四項優(yōu)化具體又是如何起到作用的,我們繼續(xù)往下看。
軟硬件協(xié)同的優(yōu)化設(shè)計在訓(xùn)練大模型這條路上,可以說一直有“三座大山”在占道。
首先就是內(nèi)存不夠用。
現(xiàn)在的大語言模型(比如GPT、Llama)變得越來越龐大,需要的存儲空間激增。特別是它們使用的“注意力機(jī)制”會產(chǎn)生大量臨時數(shù)據(jù)(KV Cache),占用大量顯卡內(nèi)存。
但高性能顯存的容量增長太慢了,每年才增加不到50%,遠(yuǎn)遠(yuǎn)跟不上需求。
其次是計算效率低。
訓(xùn)練超大規(guī)模模型需要海量計算資源,傳統(tǒng) “稠密模型”(如 Llama-3)每次計算都要激活所有參數(shù),導(dǎo)致計算成本極高。
而 “混合專家模型”(MoE)雖然更高效,但需要復(fù)雜的通信機(jī)制(如專家間數(shù)據(jù)傳輸),對網(wǎng)絡(luò)帶寬要求極高。
最后就是通信速度慢。
當(dāng)使用多個GPU一起訓(xùn)練時,它們之間需要不斷交換數(shù)據(jù),這個過程會產(chǎn)生延遲。即使用了高速網(wǎng)絡(luò)(如InfiniBand),這種延遲仍然會拖慢整體訓(xùn)練速度,尤其是處理長文本或需要實時響應(yīng)時更明顯。
而這篇論文所要解決的,正是上述的這些老大難的問題。
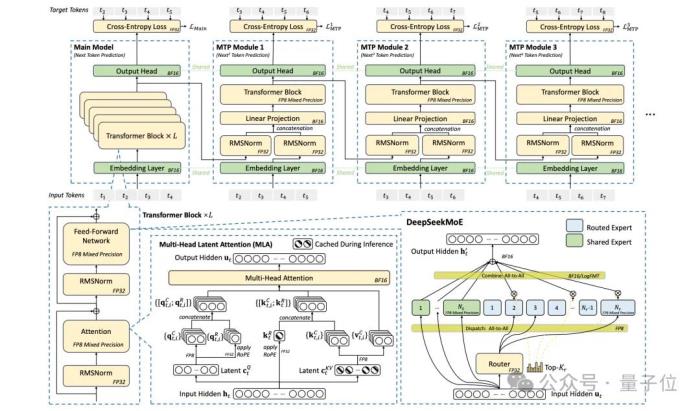
△DeepSeek-V3的基本架構(gòu)
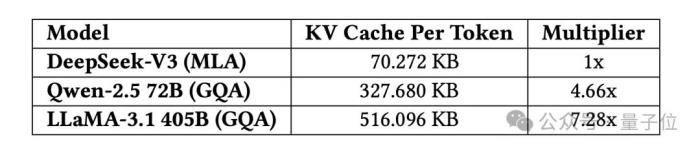
DeepSeek團(tuán)隊首先是對內(nèi)存進(jìn)行了優(yōu)化,所采用的方法則是多頭潛在注意力(MLA),為的就是減少 “鍵值緩存”(KV Cache)的內(nèi)存占用。
傳統(tǒng)模型每個注意力頭都需要獨立緩存鍵值對,而MLA通過投影矩陣將所有頭的鍵值對壓縮成一個更小的 “潛在向量”,只需緩存這一向量。
相比其他模型(如LLaMA-3、Qwen-2.5),DeepSeek-V3的KV緩存大小每token僅需70 KB,是傳統(tǒng)方法的1/7到1/4,大幅降低顯存壓力,尤其適合長文本處理。
在計算優(yōu)化方面,DeepSeek-V3所采用的方法,則是MoE和FP8低精度訓(xùn)練。
MoE,即將模型參數(shù)分成多個 “專家”,每次只激活部分專家處理輸入,顯著減少實際計算量。
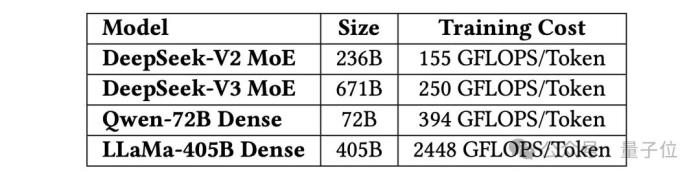
DeepSeek-V3采用類似的思路,其總參數(shù)雖然是6710億,但每次僅激活370億參數(shù),訓(xùn)練成本僅為同規(guī)模稠密模型的1/10(如Llama-3.1的訓(xùn)練成本是其近10倍)。
也正因推理時激活參數(shù)少,DeepSeek-V3可在消費級GPU(如售價1萬美元的顯卡)上運(yùn)行,每秒生成近20個token,適合個人或中小型企業(yè)使用。
至于FP8低精度訓(xùn)練,不同于傳統(tǒng)訓(xùn)練使用BF16(16 位浮點),可將內(nèi)存占用和計算量減半,同時通過 “精細(xì)量化”(如分塊壓縮)保持精度。
而DeepSeek-V3是首次在開源大模型中成功應(yīng)用FP8訓(xùn)練,訓(xùn)練成本降低50%,且精度損失小于0.25%。
除此之外,DeepSeek-V3在通信方面也做了相應(yīng)的優(yōu)化。
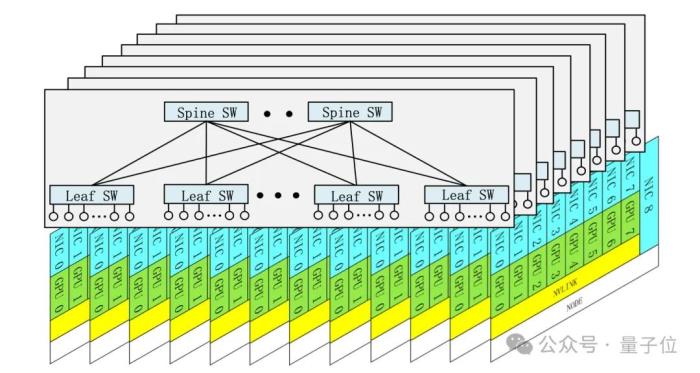
例如多層胖樹網(wǎng)絡(luò)(Multi-Plane Fat-Tree),將集群網(wǎng)絡(luò)分為多個 “平面”,每個GPU連接到獨立的網(wǎng)絡(luò)平面,避免不同任務(wù)的流量沖突(如訓(xùn)練與存儲通信分離)。
相比傳統(tǒng)三層網(wǎng)絡(luò),兩層結(jié)構(gòu)成本降低40%,延遲減少30%,支持上萬GPU擴(kuò)展。
DeepSeek-V3在做推理時,還將 “注意力計算” 與 “專家間通信” 分階段執(zhí)行,利用流水線并行(DualPipe)讓GPU在計算時同時傳輸數(shù)據(jù),避免空閑等待,吞吐量提升近1倍。
最后,在推理加速方面,DeepSeek-V3采用的是多token預(yù)測(MTP)的方法。
傳統(tǒng)模型每次只能生成1個token,而MTP通過輕量級子模型并行預(yù)測多個候選token(如一次預(yù)測2-3個),驗證后選擇最優(yōu)結(jié)果。
從實驗效果來看,生成速度提升1.8倍,例如每秒生成 oken數(shù)從10個增至18個,同時保持準(zhǔn)確率在80%-90%。
以上就是DeepSeek-V3通過硬件與模型的協(xié)同設(shè)計,在有限資源下可以實現(xiàn)高效訓(xùn)練和推理的關(guān)鍵技術(shù)了。
不過除此之外,這篇論文還對未來的工作有著一定的啟發(fā)作用。
從 “被動適配” 到 “主動設(shè)計”既然已經(jīng)知道了當(dāng)前AI在硬件上的瓶頸,就可以提出對下一代AI硬件的期待。
DeepSeek團(tuán)隊從五大維度做出了展望,希望在這一方面能夠從過去的“被動適配”逐步過渡到“主動設(shè)計”。
1、低精度計算支持
針對計算效率低的問題,下一代的AI硬件需要提高累積寄存器的精度,支持FP32累加,或可配置精度(如訓(xùn)練用FP32,推理用FP16)。這樣才能在不同的模型訓(xùn)練和推理需求中實現(xiàn)性能和準(zhǔn)確性的平衡。
硬件還需要支持本地的細(xì)粒度量化,使張量核心能夠直接接收縮放因子(scaling factors),在計算單元內(nèi)部完成量化和反量化,減少數(shù)據(jù)搬運(yùn)。
此外,建議支持LogFMT(對數(shù)浮點格式),在相同比特寬度下提供更高精度,并提高編解碼的速度。
2、擴(kuò)展與擴(kuò)展融合
針對傳輸速度慢的問題,建議未來的硬件將節(jié)點內(nèi)(縱向擴(kuò)展)和節(jié)點間(橫向擴(kuò)展)的通信整合到一個統(tǒng)一的框架中,通過集成專門用于網(wǎng)絡(luò)流量管理的協(xié)處理器。
這樣的設(shè)計可以降低軟件復(fù)雜性并最大化帶寬利用率,包括以下內(nèi)容:
統(tǒng)一網(wǎng)絡(luò)適配器:設(shè)計連接到統(tǒng)一擴(kuò)展和縮減網(wǎng)絡(luò)的NIC(網(wǎng)絡(luò)接口卡)或I/O芯片,讓網(wǎng)卡直接支持所有通信需求。專用通信協(xié)處理器:將數(shù)據(jù)搬運(yùn)、Reduce、類型轉(zhuǎn)換等任務(wù)卸載到專用硬件,釋放GPU SM資源。增加智能傳輸功能:自動轉(zhuǎn)發(fā)數(shù)據(jù),支持廣播和匯總操作,并自動處理數(shù)據(jù)順序問題。動態(tài)帶寬分配:支持流量優(yōu)先級調(diào)度(如EP通信>KV緩存?zhèn)鬏敚PU-FPU高速互聯(lián):用NVLink連接CPU與GPU,進(jìn)一步優(yōu)化節(jié)點內(nèi)通訊。3、網(wǎng)絡(luò)拓?fù)鋬?yōu)化
針對網(wǎng)絡(luò)卡頓的問題,建議以太網(wǎng)供應(yīng)商開發(fā)專門針對RDMA工作負(fù)載進(jìn)行優(yōu)化的RoCE交換機(jī),移除不必要的以太網(wǎng)功能。
還需要優(yōu)化路由策略,支持自適應(yīng)路由(Adaptive Routing,AR)通過動態(tài)向多個路徑發(fā)送數(shù)據(jù)包,即可顯著提高網(wǎng)絡(luò)性能。
或者可以通過虛擬輸出隊列(VOQ)改進(jìn)流量隔離或擁塞控制機(jī)制,隔離不同流量,避免擁塞。
4、內(nèi)存系統(tǒng)優(yōu)化
針對AI模型記性越來越差,聊天時難以記住上下文的問題,可以通過3D堆疊DRAM的方法,把內(nèi)存芯片像三明治一樣疊在計算芯片上。
或者學(xué)習(xí)Cerebras,直接在晶圓上進(jìn)行集成工程,最大化內(nèi)存帶寬和計算密度,讓硬件能記得更多。
又或者,在硬件存儲層部署稀疏注意力加速器,讓硬件直接幫忙整理記憶,只記重點。
5、魯棒性與容錯
針對大規(guī)模訓(xùn)練中網(wǎng)絡(luò)閃斷、GPU故障會導(dǎo)致任務(wù)失敗的問題,期待下一代硬件能夠支持鏈路層重試和快速故障切換,在閃斷后能夠立刻自己找備用路線。
還可以增加基于信用的流控(CBFC)+?智能擁塞控制算法(如RTT-CC),避免網(wǎng)絡(luò)集體卡死。
簡單來說,下一代AI硬件要向算數(shù)快(低精度計算+本地細(xì)粒度量化)、傳話快(直連網(wǎng)絡(luò)+智能路由)、記性好(3D內(nèi)存+近存計算)、不宕機(jī)(自愈網(wǎng)絡(luò))的方向改進(jìn),才能更好地應(yīng)用于大模型訓(xùn)練,實現(xiàn)高效擴(kuò)展。
論文地址:https://arxiv.org/pdf/2505.09343
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
