

 新火種
2025-05-12
新火種
2025-05-12 


多模態=AGI入場券?階躍星辰姜大昕:死磕基座大模型,探索多模態理解生成一體化
當大模型賽道中不少玩家明確表示放棄基礎大模型研發,心思放在更聚焦的方向上時,階躍星辰站出來——就像這家公司第一次亮相時那樣,給外界一個明確的回答:
創始人兼CEO姜大昕解釋了背后邏輯。
一方面,大模型行業的趨勢技術發展還是在非常陡峭的區間。他也很感慨AI行業發展瞬息萬變,“去年大家覺得GPT-4很牛,今天他都快下架了”,等到明年看今年的技術,同樣會覺得微不足道。
姜大昕說,階躍不想在這個過程中放棄主流增長或前進的趨勢,所以還是會堅持做基礎模型的研發。

另一方面,從應用的角度來看,階躍仍然相信應用和模型是相輔相成的。
“模型可以決定應用的上限,應用給模型提供具體的應用場景和數據。”姜大昕表示,雖然階躍的產品形態隨著模型的演變是動態發展的,但這樣的邏輯關系還是一直保持下去的。
確實如他所說,在過去的一年里,階躍星辰旗下產品從命名、布局和形態上都發生了轉變。
主打的C端助手App,由“躍問”改名為“階躍AI”,意味著它從類ChatGPT產品到Agent的轉變;產品重點形態從用戶普遍直接使用的手機App變成了端云一體Agent平臺。
“雖然我們的智能終端Agent和頭部企業合作,但總體而言,階躍的產品最終是服務C端的。”姜大昕表示,“不管作為助手類也好、內容類也好,都有非常大的機會。”
大模型領域的兩條顯著趨勢姜大昕同時強調,模型的突破是早于商業化的。就拿OpenAI來說,是先有了GPT-3.5,才有了ChatGPT。
因此,在基座模型上面繼續投入以追求智能的上限,仍然是當下最重要的一件事。
要怎么去不停觸碰智能的邊界or天花板?不如先來看看這個領域里最前沿的趨勢有哪些。
姜大昕復盤道,趨勢共有如下兩條:
一條是“模仿學習到強化學習”,另一條是“從多模態融合走向了多模態理解生成一體化”。
從模仿學習到強化學習的技術演進大家已經非常熟悉, OpenAI的o1、o3,以及DeepSeek-R1背后采用的都是強化學習技術,也是現在大模型玩家爭先恐后著重投入的方向。
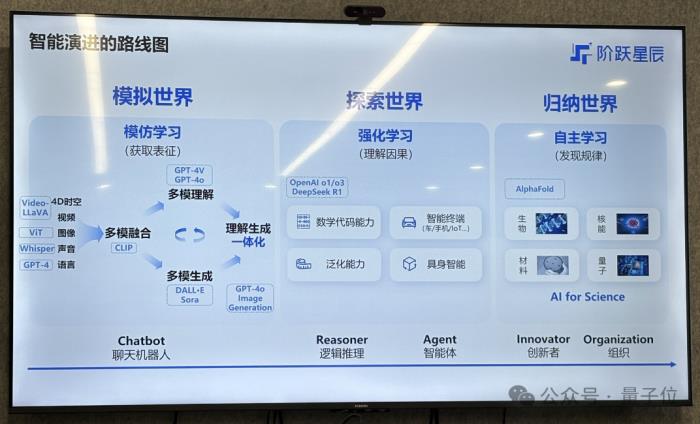
第二條趨勢則關乎多模態。
姜大昕再次提到了那句他在多個場合不停重復提及的話:多模態是實現AGI的必經之路。
無論是從人類智能的多元化角度(符號智能、視覺智能、空間智能等),還是從垂直領域AI應用需求來說,大模型的多模態能力都必不可少。
在這樣的認知指導下,階躍星辰在研發基座模型時采取了散彈式打法:
成立兩年,公司累計發布22款基座模型,覆蓋文字、語音、圖像、視頻、音樂、推理等系列。
其中有16款是多模態模型,占據總數七成;這些多模態模型又分屬圖像理解、視頻理解、圖像生成、視頻生成、圖像編輯、音樂生成、多模態推理等方向。
業界公認階躍是多模態卷王,也不是沒有道理。
多模態理解生成一體化才是未來至于如何追求智能的上限,階躍目前行進的路線與第一次公開亮相時所講的那樣一般無二,即“單模態——多模態——多模態理解和生成的統一——世界模型——AGI”。
姜大昕重點解釋了關于“多模態理解生成一體化”的部分。
它意味著多模態模型的理解和生成用一個模型來完成,而不是“視頻/圖像/語言轉文本——文本理解與生成——生成結果轉視頻/圖像/語音”的三段式過程。
大語言模型的理解生成一體化,已經有類GPT實現統一;然而在視覺領域并不如此,人們往往在理解視覺內容時選擇一個模型,在生成內容時調用另一個模型。
這并不是一個可以直接從語言模型的NTP(Next-Token-Prediction)直接遷移到視覺模型的NFP(Next-Frame-Prediction)的簡單事。
語言文本模態是低維度離散分布的,而視覺模態是高維度連續分布,這也就是說后者在進行訓練學習時,復雜性更高。

從技術角度來看,視覺領域的內容生成需要理解來控制——如果想保證生成內容有意義、有價值,實際上需要對視覺的“上下文”作出更好的理解。
反言之,理解需要生成來監督。姜大昕解釋說,就是“只有生成了的時候才是真正的理解了”。
現在,視覺領域還沒有出現自己的Transformer架構,階躍就是想做出一個視覺領域的、生成一體化架構,并且是非常scalable的。
姜大昕分享道,GPT-4o可能已經實現了多模態理解生成一體化,而階躍的圖像編輯模型Step1X-Edit也初步實現了這一點。
之所以稱其為“初步”,是階躍覺得Step1X-Edit的效果依然有很大改進空間,還可以在架構上做進一步的優化,數據上也可以做進一步的打磨,讓它的效果變得更好一些。
但具體走哪條路線能精益求精,不管是階躍內部還是業界都沒有公認的真理。姜大昕表示,在這一方面,階躍內部多有條技術路線并行,因為確實哪一條路線都會有可能出現突破。
“一旦突破以后,今后的道路會更加順暢。”姜大昕稱。
One More Thing既然認可多模態理解生成一體化才是未來,為什么階躍不把所有的精力集中在Step-R1-V-Mini這樣的多模態推理模型上,反而是要在各個模態上都發力呢?
新火種把這個問題拋給了姜大昕。
他很坦然,表示也想過做,但這行不通。
簡單點說,做理解生成一體化,必須自身具備非常強的綜合實力。
但姜大昕信心滿滿,“我們幾條線的能力都非常強,所以才可以組合起來去探索這個路徑”。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
