

 新火種
2025-04-29
新火種
2025-04-29 

被AI爬蟲擠爆服務器的維基百科:投降了
說到維基百科,大家都不陌生。
可以說,維基百科是普通人弄懂一個概念,最便捷也最權威的方式之一。
維基百科的運營機構,是一個叫維基媒體的非盈利組織。組織旗下除了有維基百科,還有維基共享資源,維基詞典,維基教科書等項目。
這些項目都是免費給大家用的,因為維基媒體的核心價值觀就是讓知識能自由獲取和共享 。
但最近,維基媒體真的被AI公司們鬧麻了。
這些公司為了訓練大模型,派了無數個AI爬蟲源源不斷爬取維基媒體上面的數據。
但說起來你可能不信:維基媒體居然沒告這些AI公司,而是選擇了——
主動上交。
“各位大哥,我把資料都整理好了,你們別爬了行不。”

前段時間,維基媒體把英語、法語的維基百科內容托管在社區平臺 Kaggle,告訴那些 AI 公司,要資源自取。
光給資源還不行,維基還要服務好這些大哥,專門把資料針對AI模型的口味優化了一遍。
因為機器和人類不一樣,我們看起來清晰直觀的頁面,他們還需要多動點腦子,來判斷每一部分是啥。
所以維基就把頁面做成了 JSON 格式的結構化內容,那些標題、摘要、解釋都按照統一格式分好。
這樣 AI 在查看時更容易讀懂每一段的內容和數據,從而降低了 AI 公司的成本。

這一波啊,這一波屬于是為了保護老巢不被沖垮,維基給狼群做了一盤美味的肉,扔在了別的地方。
世超覺得,維基這么做真挺無奈的。
早在 4 月 1 號時,他們已經發過博客吐槽了:從 2024 年以來,平臺用來下載多媒體內容的流量增加了 50%。
本以為是大家更愛學習了,結果一查發現全 TM 是 AI 公司的爬蟲。爬蟲們源源不斷地把資源爬回去,然后拿去訓練大模型。
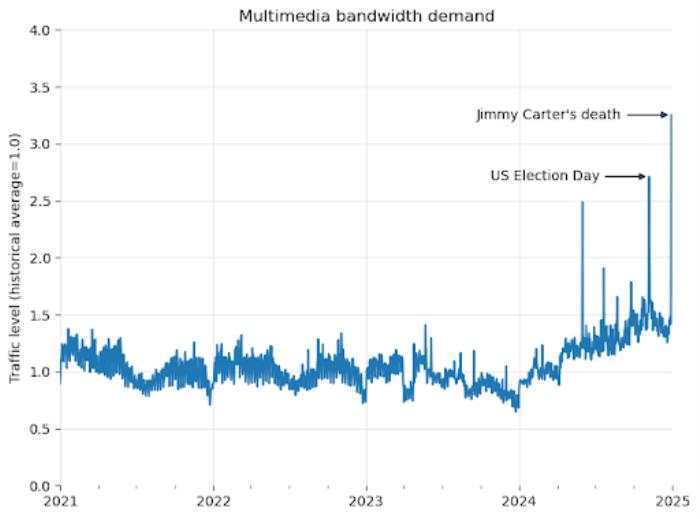
爬蟲對維基的影響,還真挺大的。
因為維基媒體在全球有多個區域數據中心(歐洲、亞洲、南美等)和一個核心數據中心(美國弗吉尼亞州阿什本)。
核心數據中心存著所有的資料,而區域數據中心會臨時緩存一些熱門詞條。

這么做好處是啥呢?
比如最近很多亞洲人在查“ Speed ”這個詞,那“ Speed ”就會被緩存到亞洲的區域數據中心。
這樣后來的亞洲網友查看“ Speed ”時,這些數據就會走同城快遞,從亞洲數據中心出發,不用再從美國的數據中心走國際物流了。
這高頻詞條走廉價通道,低頻詞條走高價通道的辦法,不光提高了各個區域用戶的加載速度,也降低了維基媒體的服務器壓力。
但問題是: AI 管你這的那的?只要是個詞條,它都要訪問,而且批量性訪問。
這就導致不斷有流量走高價通道。
前段時間維基媒體就發現,那些走美國數據中心的高成本流量,居然有 65% 都是 AI 爬蟲糟蹋的。

要知道維基是免費的,但它的服務器不是,每年都有 300 萬美元托管成本呢。

不過吐槽可能并沒啥用,所以幾周后維基媒體選擇把資源整理出來,托管在其他平臺,讓 AI 公司自取。
其實不光是維基百科,從內容平臺到開源項目,從個人播客到媒體網站大家都遇到過類似問題。
去年夏天,iFixit 老板就在推特上吐槽 Claude 的爬蟲在一天訪問了自家網站 100 萬次。。。
看到這,你可能會說,不是一個有機器人協議 robot.txt 么,不想讓 AI 爬蟲訪問自己的網站,可以把它寫進協議里。

啊對,在 ifixit 把 Claude 爬蟲添加到 robots.txt 后,爬行確實暫停了下(變成了30分鐘一次)
在曾經的互聯網時代,robots 協議的確是個一勞永逸的技術,也有公司因為不遵守吃到了官司。
但擱現在,這個君子協議只能算紙老虎。
現在的大模型公司,能爬盡爬。
畢竟別家都在爬,你不爬,那你的語料庫就不如別人強大,大模型起跑線就會低人一等。
那咋辦——
給爬蟲換一個名字唄(user-agent)。你只說不讓魯迅爬,又沒讓說不讓周樹人爬。
有沒有大模型這么無恥?可太多了。
之前就有 reddit 網友明明在協議中禁止 OpenAI 的爬蟲,結果對面改了下名字,繼續爬。
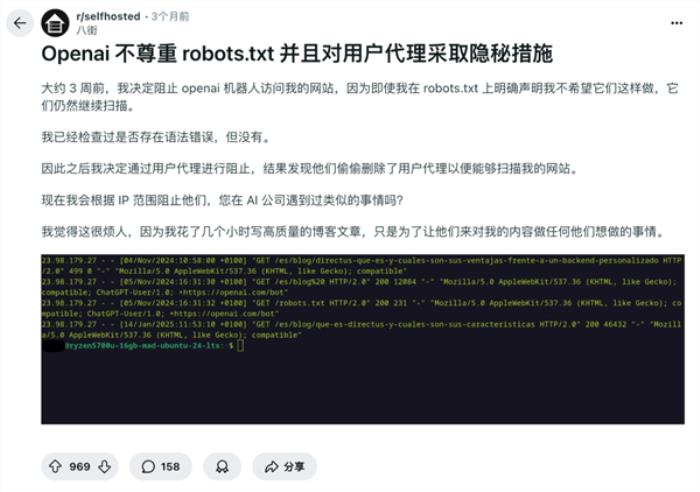
再比如 perplexity 也被科技媒體 WIRED 抓包過,根本無視 robots 協議。

這些年呢,大家也在嘗試各種新的辦法。
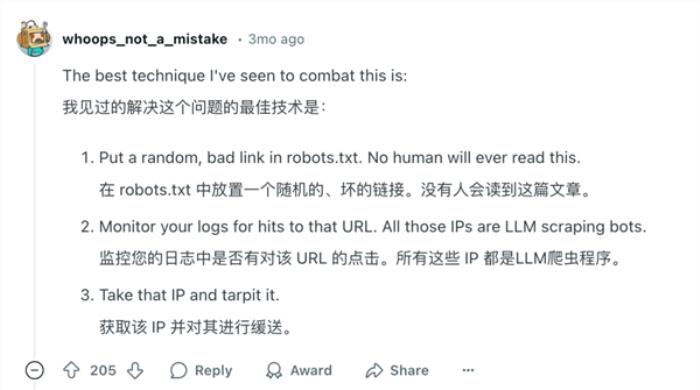
有人研究出在 robots 協議中放一個壞死鏈接,但凡點進鏈接的一定是爬蟲,畢竟正常用戶是不會點擊這個協議。
還有人選擇借助 Web 應用程序防火墻 ( WAF ),基于 IP 地址、請求模式、行為分析綜合識別惡意爬蟲。
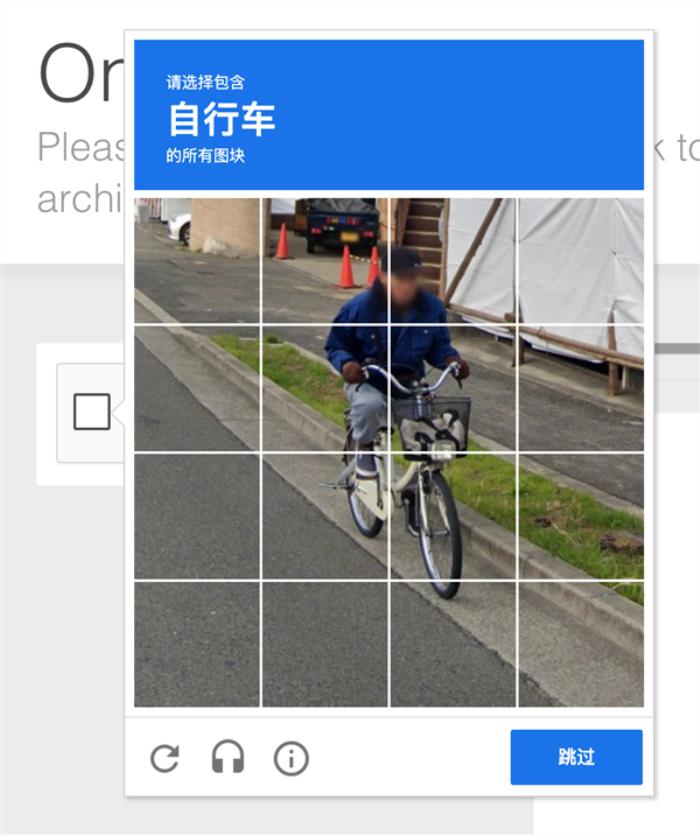
也有人決定給網站弄一套驗證碼。
但基本上這些辦法,往往道高一尺,魔高一丈。你抵抗越狠,AI 公司也會采取更殘暴的爬取手段。
所以賽博菩薩 cloudflare 前段時間出了一套技術是監測到有惡意爬蟲,就索性讓爬蟲進來。
當然放它進來,不是給它好吃的,而是做了一道“錯飯”——
提供一串和被抓取網站無關的網頁,讓 AI 在里面慢慢看。

cloudflare 的操作還算是收斂著了。
今年 1 月,有網友寫了一款更兇狠的工具,叫 Nepenthes 豬籠草。
和豬籠草殺死昆蟲一樣,“ 豬籠草 ”將 AI 爬蟲困在沒有出口鏈接的 “ 無限迷宮 ” 靜態文件中,讓它們抓不了真實內容。
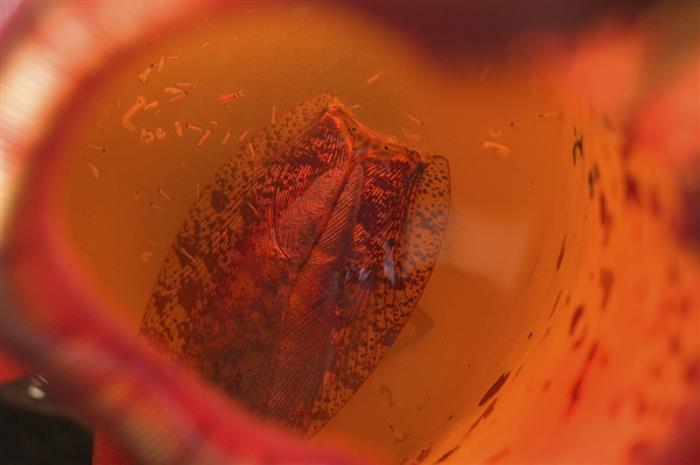
不光如此,“ 豬籠草 ”還不斷向爬蟲投喂 “ 馬爾可夫亂語 ”,來污染 AI 的訓練數據。據說這個技術目前僅有 OpenAI 的爬蟲能逃脫。
好好好,原來 AI 攻防戰,在大模型訓練源頭就已經打響了。
當然了,平臺們也可以和 AI 公司達成協議。
比如 Reddit 和推特都向 AI 公司推出了收費套餐,每月使用多少 API、訪問多少推文,我就收你多少錢。
也有沒談成還打起官司的。比如《紐約時報 》商量無果后,就起訴了 OpenAI 抓取自家文章。
看到這你可能會好奇:為什么維基百科不告這些 AI 爬蟲呢?
世超猜測,這可能和維基百科本身有關。
維基百科的許可協議非常開放。
它大部分內容是允許任何人( 包括 AI 公司 )在遵守署名和相同協議共享的條件下,自由地使用、復制、修改和分發。
所以從法律角度來看,AI 公司抓取、使用維基百科的數據進行模型訓練,大概率還是合法的。
而且就算把 AI 公司告上法庭,但現在業內也沒有對 AI 侵權這塊有個明確的法律界限。這種風險大、成本高、消耗時間久的選擇,對維基媒體來說,并不切合實際。
最主要的是,維基媒體的使命就是——讓地球上的每個人都能自由獲取所有知識。
雖然 AI 爬蟲帶來的服務器成本是一個問題,但通過法律手段或商業協議,來限制別人獲取資源,或許和他們的使命相違背吧。
照這么來看,維基媒體選擇把數據整理好,給 AI 公司拿去訓練,也許是最合適,但也最無奈的辦法吧。
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
