

 新火種
2023-09-09
新火種
2023-09-09 


CVPR2021首次!王言治教授和色拉布團隊把GAN壓縮22倍
來源:金慶
編輯:好困
【新智元導讀】王言治教授團隊與美國色拉布公司(Snap Inc.)首次提出了一種GAN剪枝的方法,除了使壓縮時間減少了四個數量級以外,還在遠低于原始計算量的條件下,獲得來比原有模型更好的性能,并且實現了更高的生成圖片質量。論文已被CVPR 2021收錄。
神經網絡結構搜索有助于得到在計算機視覺任務中效果更好的深度神經網絡,同時可以減小模型尺寸, 提高運行效率,實現移動端高速處理。
近年來,深度神經網絡在圖像、語音、文本等領域的進展使得其廣泛應用在不同功能的系統中,包括圖像分類、目標識別、語義分割、語音處理等。
不同于判別式模型只需要得到比較簡單的判斷結果(如分類結果),生成式模型需要生成更加復雜的圖像結構。
相比于前者,后者通常需要更大的計算量和更大規模的模型,這使得將生成式模型壓縮以提高運行效率面臨巨大挑戰。
為此,美國東北大學王言治教授研究團隊與美國色拉布公司(Snap Inc.)的創意視覺研究組共同提出了壓縮與教學技術。論文已經被CVPR 2021會議收錄。

通過將inception模塊引入生成模型并進行神經網絡結構搜索,從而使搜索空間擴展至包含多種不同核尺寸的卷積模塊。
并且利用知識蒸餾用搜索過程中訓練的大模型指導搜索出的小模型的訓練過程,在遠低于原始超大規模生成模型計算量的條件下實現優于原始超大規模生成模型的生成圖片質量。
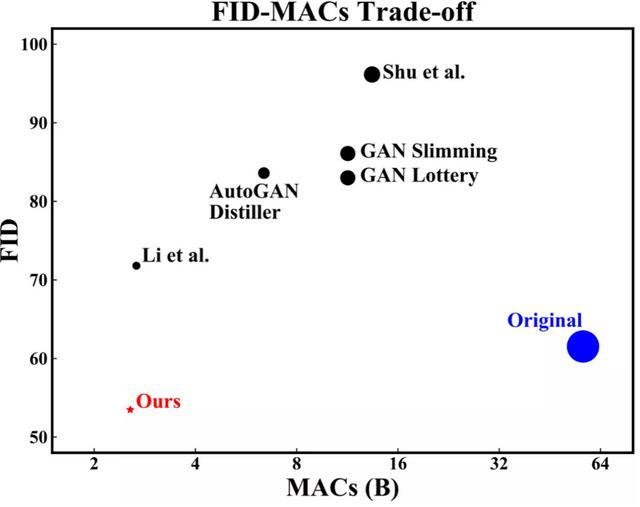
與原有的巨型生成模型相比,論文的方法得到的模型在壓縮的同時可以生成更高質量的圖片(FID越低圖片質量越好),并且實現了SOTA的性能-效率取舍。
網絡模型
實現高效率網絡模型主要包括網絡壓縮和模型結構搜索兩種方式。
相比于前者,后者通常獲得的網絡結構更多樣,效果也更優,并且現代壓縮算法通常也包含搜索步驟。
然而,直接將傳統的用于壓縮或搜索的方法用在生成模型中,通常會導致模型性能具有較大損失,特別是生成的圖像畫質通常較差,容易產生額外的噪點和花斑。
此外,生成模型因其計算量龐大,通常訓練時間較長,直接使用網絡搜索一般不容易得到最優解,使得網絡結構優化面臨更多的挑戰。
而且,對于高復雜度的大型網絡(如GauGAN),傳統方法通常導致性能損失更為明顯。
因此,研究出高速有效的網絡結構搜索方法和訓練方法,對于提高生成模型的性能-效率取舍具有重要意義。
為了保證壓縮后的生成模型產生出高質量的圖像,需要解決的幾個主要問題是:
網絡搜索空間需要足夠廣,使得搜索過程的自由度足夠高;網絡搜索的過程需要足夠快,使得搜索過程中遍歷的備選模型盡可能多,迭代過程也盡可能快(如超參調優等);搜索出的模型的在訓練時需要充分利用已有信息,盡量保證模型得到充分訓練。
為了擴展網絡搜索空間,傳統方法通過在不同類型操作之間進行選擇來實現網絡結構搜索。
與之相比,近年來提出的AtomNAS算法通過引入Inception模塊,將多種不同類型的神經層同時使用,在提升模型性能的同時,將搜索過程和訓練過程合并,顯著降低了模型搜索所需的額外計算開銷。
受此啟發,作者將多種不同核尺寸的卷積模塊同時使用,并同時包含普通卷積模塊與depthwise卷積模塊,實現網絡搜索空間的擴充。
所用的模塊包含1x1、3x3、5x5三種不同核尺寸的卷積模塊,并且同時使用了普通卷積模塊與depthwise卷積模塊。
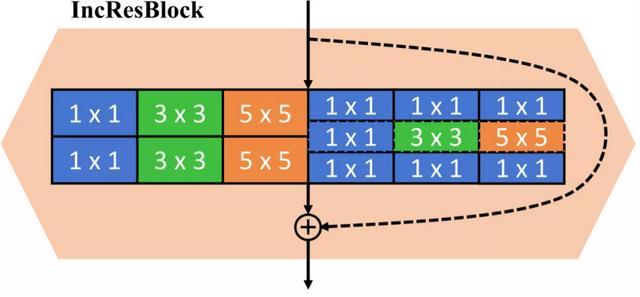
用在生成模型中的Inception殘差模塊
該模塊使用不同核尺寸的卷積模塊,并且同時使用普通卷積模塊與depthwise卷積模塊,在搜索過程中有助于擴充搜索空間。
作者將這一模塊用在大型網絡GauGAN中,用來替代其中主干中的卷積層和第一個歸一化層中使用的SPADE模塊中的卷積網絡。
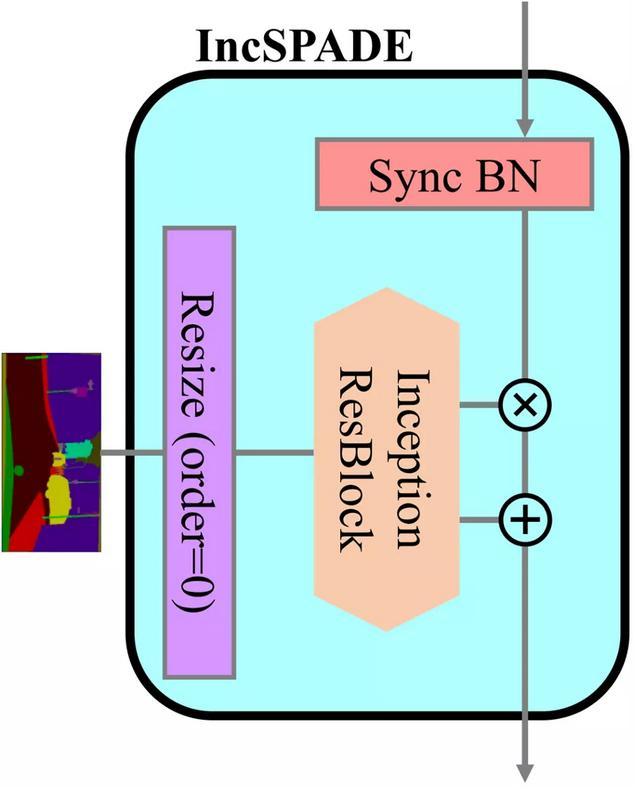
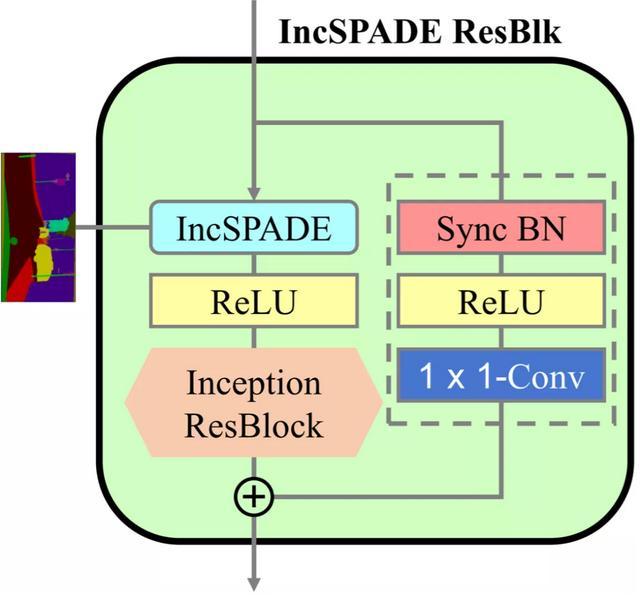
將Inception模塊用在GauGAN的SPADE模塊中
此外,主干中的第二個卷積層和分支中的卷積層可以使用普通的歸一化層,而不需要使用計算量很大的SPADE模塊。
網絡空間的擴展不僅使得搜索過程簡單高效,而且可以提高網絡的靈活度,使得模型在相同計算量下能實現更高性能。
網絡搜索
在網絡空間擴展的同時,提高網絡搜索效率成為網絡搜索的主要問題。參照傳統的網絡搜索辦法,作者選擇使用歸一化層的權重模大小作為搜索依據。
論文提出的搜索過程直接參考目標計算量,使用半分法來確定網絡壓縮所需的權重閾值。

使用半分法根據目標計算量確定壓縮閾值對網絡進行壓縮
首先根據訓練好的網絡中歸一化層的權重大小預設搜索上界和下界,由此算出一個權重閾值對網絡進行預壓縮,根據預壓縮所得網絡的大小與目標大小的相對關系,調整上下界,直至所得網絡大小滿足要求。
相比于文獻中提出的生成模型壓縮方法,論文提出的方法可以使得壓縮過程所需時間減少至少四個數量級。
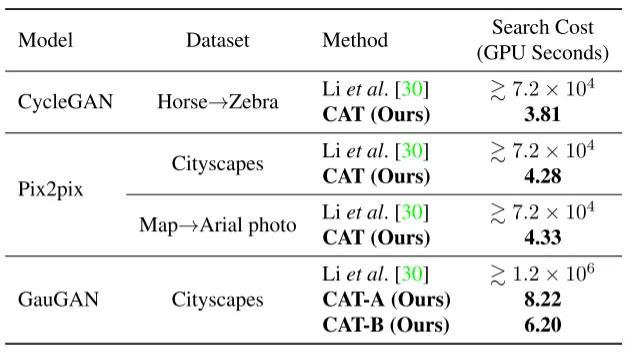
不同壓縮方法在不同數據集和不同生成模型上所需壓縮時間比較
搜索出模型結構后,通常原有模型的權重無法直接使用,需要重新訓練。由于模型較小,訓練過程中可能會出現較難優化甚至不收斂的問題。
為使得訓練結果較好,文獻中提出先額外訓練一個較大的模型作為導師,再使用此模型訓練搜索出的小模型。然而這種方法增加了額外的訓練開銷,使得搜索和訓練過程的更加冗長。
為此,作者提出使用用于搜索的原有大模型作為導師模型,相當于將用于搜索的模型再次利用,進行知識蒸餾。
這樣,大模型不僅用來作為小模型的導師指導訓練,也因為其本身的結構特征用作網絡結構搜索。這種方法可以最大限度地利用大模型,減少訓練開銷和時間。
知識蒸餾
知識蒸餾技術通常包含直接蒸餾和間接蒸餾。
前者一般只利用網絡的最終輸出進行比較實現蒸餾的目的,后者則利用網絡內部卷積層的中間結果進行比較,作為指導原則。作者則選取后者對搜索的結構進行訓練。
然而,由于作為導師的大模型的中間層特征與經過搜索壓縮后得到的作為學生的小模型的中間層特征的通道數存在差異,無法通過直接比較完成蒸餾的目的。
文獻中引入一個額外的可訓練的線性層,將學生模型的特征映射到導師模型特征的空間中。
這樣做不僅會導致引入額外的訓練層,增加訓練復雜度,而且蒸餾辦法較為間接,可能效果并非最優。
為此,作者采用一種更直接的辦法,通過比較導師模型特征和學生模型特征,通過最大化二者相似度,實現蒸餾目的。
Hinton等人于2019年通過詳細分析,比較了不同的相似度判斷標準,并且提出一種稱為中心化核對齊(CKA)的指標。
作者采用類似的核對齊(KA)指標,并且發現中心化對最終結果不具有決定性的影響。
如下圖所示,作者通過計算導師模型特征與學生模型特征的核對齊指標并將其最大化作為損失函數進行訓練,實現知識蒸餾的目的。
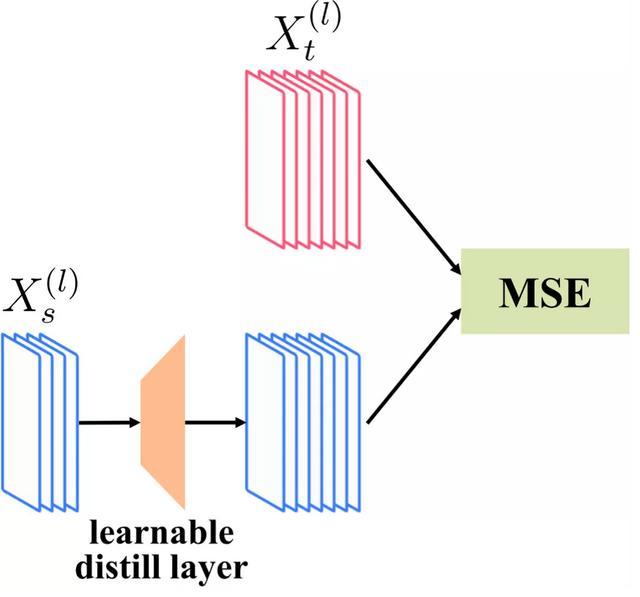
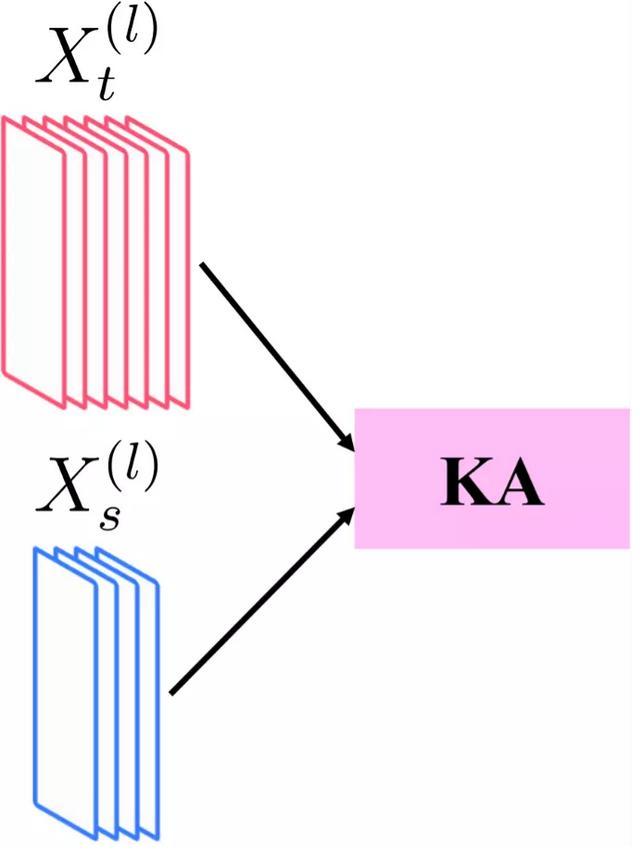
與傳統的通過引入額外的訓練線性層進行知識蒸餾相比(左圖),論文提出一種直接比較特征相似度的方法進行蒸餾(右圖)。
結果分析
作者在多個數據集和多種類型的網絡上驗證了論文提出的方法,并且與原有的大模型和文獻中已有的生成模型進行了比較。
論文提出的方法在將生成模型計算量壓縮數十倍的基礎上,仍然可以獲得比原有模型更好的性能(高mIoU或低FID),并且與文獻中的方法相比,實現了SOTA的性能-效率取舍。
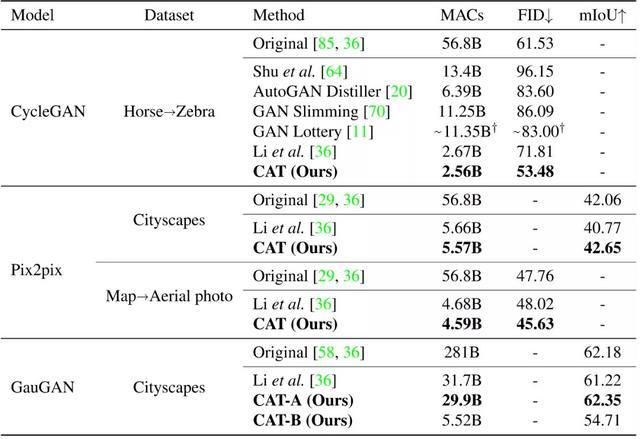
不同壓縮方法在不同數據集和不同生成模型上性能比較
為了更直觀地展示結果,作者在不同數據集和模型上將壓縮模型生成的圖片和原有模型生成的圖片進行對比。
可以看到,論文提出的模型在遠低于原有模型計算量的條件下,可以生成更高質量的圖片。

Horse2Zebra數據集上壓縮CycleGAN模型

Map2Aerial數據集上壓縮Pix2pix模型


Cityscapes數據集上壓縮GauGAN模型
作者介紹
第一作者金慶,美國東北大學ECE系PhD一年級學生。
主要研究領域為Deep Learning algorithm,研究內容已經在發表在CVPR,AAAI等機器學習和計算機視覺會議中。
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
