

 新火種
2025-02-14
新火種
2025-02-14 


AI做生物實驗?還能迭代?浙大集成PLM和「自動化生物工廠」革新蛋白質工程范式

編輯 | 蘿卜皮
傳統的蛋白質工程方法(如定向進化)雖然有效,但通常速度緩慢且勞動密集。機器學習和「自動化生物工廠」的進步為優化這些過程提供了新的機會。
浙江大學的研究人員設計了一個基于蛋白質語言模型的自動進化平臺,這是一個在設計-構建-測試-學習循環內實現蛋白質工程自動化的閉環系統。
該系統大大提高了蛋白質進化的速度和準確性,推動了蛋白質工程在工業應用方面的快速發展。
該研究以「Integrating protein language models and automatic biofoundry for enhanced protein evolution」為題,于 2025 年 2 月 11 日發布在《Nature Communications》。

蛋白質在醫藥、化學制造、能源、農業和消費品等各個領域發揮著重要作用。然而,對于工業應用,蛋白質通常需要進行工程改造以增強其穩定性、活性、選擇性和結合親和力等特性。
蛋白質工程已開發出多種策略,定向進化是一種成熟且有效的方法。傳統的定向進化依賴于隨機誘變和高通量篩選的迭代循環來識別具有所需特性的變體。
雖然這一過程非常有效,但耗時且費力。此外,由于定向進化通常一次引入一個突變,因此可能陷入局部適應度最優,從而限制進一步優化。
在最新的研究中,浙江大學的研究人員提出了一種蛋白質工程策略稱為 PLMeAE(protein language model-enabled automatic evolution),將蛋白質語言模型 (PLM)的預測能力與「自動化生物工廠」的運營效率相結合。
在設計-構建-測試-學習周期中,學習和設計階段利用 PLM 的見解來闡明蛋白質序列適應度關系并采樣新突變體,而構建和測試階段則使用自動化生物工廠高效進行。
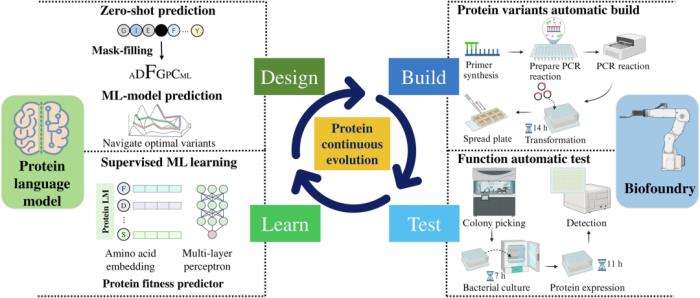
PLMeAE 概述
PLMeAE 平臺是一個在設計-構建-測試-學習(DBTL)循環內進行自動化蛋白質工程的閉環系統。該平臺采用 PLM 來促進學習和設計階段,而構建和測試階段則由「自動化生物工廠」執行。
該流程從創建變體庫開始,在設計階段采用 PLM 啟用的零樣本學習方法。具體來說,PLM 解決了兩個零樣本任務,具體取決于突變目標位點的可用性。
首先,在沒有關于目標蛋白的先驗信息的情況下,PLM 用于在零樣本設置中預測高適應度單突變體。其次,當突變位點已根據之前的實驗或通過物理建模技術(例如對接、分子動力學模擬)確定時,PLM 用于在給定目標位點預測零樣本高適應度多突變變體。
隨后,在構建和測試步驟中,通過 biofoundry 的自動化設施合成、表達和測試所提出的庫。在收集實驗數據后,在學習階段,PLM 對蛋白質序列進行編碼,并訓練監督機器學習模型以將這些變體與其適應度水平相關聯。
隨后,應用優化算法探索變體前景,促進合理設計并確定有希望進行后續測試的變體。這種類似于主動學習策略的迭代過程持續進行,直到開發出最佳變體。
用于蛋白質變體設計的 PLM
在將 PLM 應用于蛋白質變體設計時,研究人員開發了兩個模塊,分別用于預測不知道突變位點的蛋白質的高適應度突變體和已知突變位點的蛋白質。
模塊 I 用于沒有先前確定的突變位點的蛋白質。在此模塊中,PLM 預測具有高適應性可能性的單個突變體,并將此可能性作為適應性水平的代表。然后使用這些高可能性突變體來識別關鍵突變位點。
另一方面,模塊 II 針對具有已知突變位點的蛋白質,并使用 PLM 來抽取有用的突變體進行實驗表征。此外,PLM 用于編碼蛋白質序列以訓練適應度預測器。模塊 I 和模塊 II 可以組合使用或獨立使用。
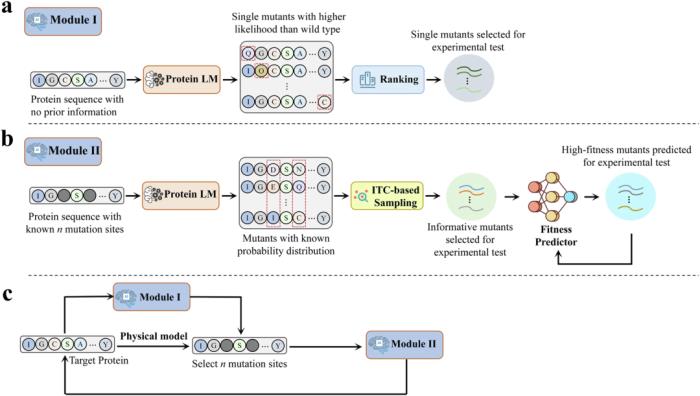
圖示:用于蛋白質自動進化的蛋白質語言模型。(來源:論文)
自動化生物工廠
該團隊的機器人系統擅長構建蛋白質變體并持續收集蛋白質變體功能數據,通過全面的元數據跟蹤和實時數據共享確保高可重復性。
通過將 PLM 的高級預測功能與機器人系統的高通量功能相結合,該方法旨在超越傳統限制并加快發現和增強對工業應用至關重要的蛋白質。
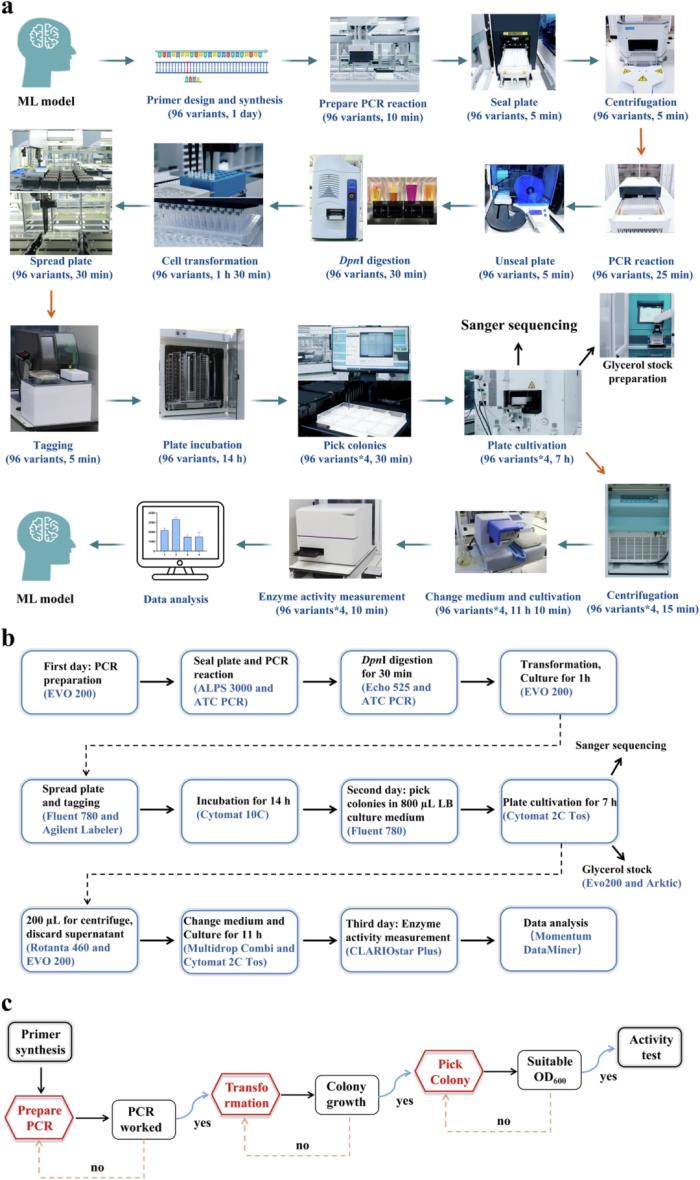
圖示:自動蛋白質變體構建和測試的概述。(來源:論文)
實踐與驗證
研究人員成功利用 PLMeAE 改造 pCNF-RS,提高酶活性,提高 ncAAs 摻入蛋白質的效率。經過四輪進化,獲得的最佳 pCNF-RS 變體使酶活性提高了 2.4 倍,摻入 pAcF 的蛋白質產量提高了 12.2 倍。
自動進化過程中,一輪自動構建并檢測了 96 個突變體,與biofoundry中自動化的 96 通道電子移液器相對應。四輪進化共構建并檢測了 384個 突變體。
以工程 pCNF-RS 為例,該團隊的生物工廠一輪實驗測試大約需要 59 小時,其中包括大約 24 小時的引物運送延遲,而 ML 模型訓練和新變體預測則需要不到 1 小時。四個設計-構建-測試-學習周期僅花費 240 小時,大約 10 天。
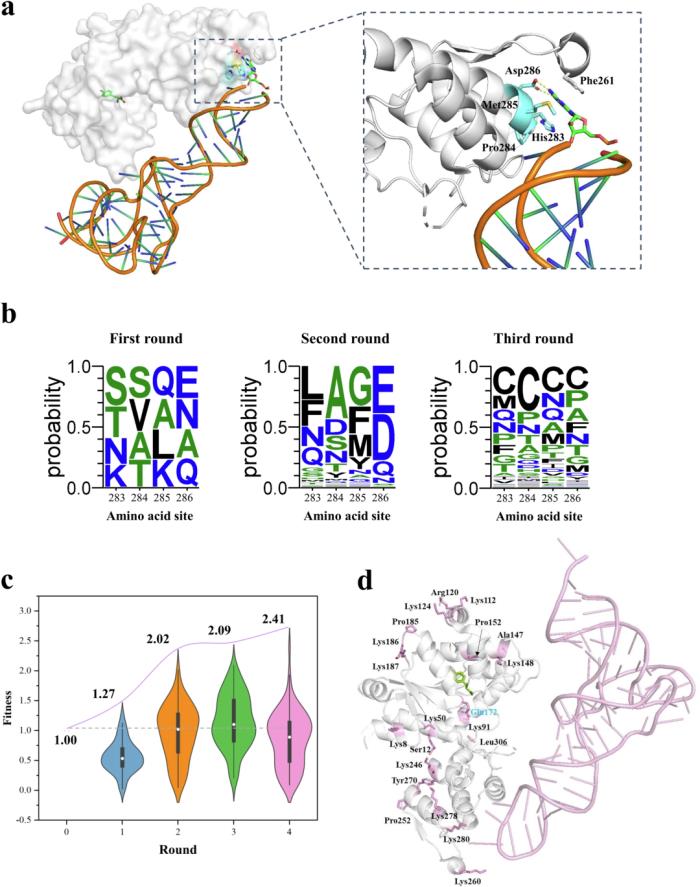
圖示:pCNF-RS 的自動進化。(來源:論文)
整個過程大約需要 5 天的準備時間、7 天的一次正向選擇時間、7 天的一次負向選擇時間以及 5 天的基于熒光的最終篩選時間,兩輪選擇總共需要 38 天。
然而,實驗失敗可能發生在突變庫構建、細胞轉化、質粒制備和分離等步驟中。此外,可能需要更多輪正負篩選才能獲得更好的變體。這會導致整個過程在實際情況下花費更長的時間。
討論
PLMeAE 與這些早期研究的不同之處在于所使用的 ML 模型和自動化設施的功能。PLMeAE 使用蛋白質語言模型對知情變體進行零樣本預測,并對蛋白質進行編碼以基于多層感知器訓練適應度預測器,而以前的研究主要應用在公共數據集上訓練的機器學習模型(例如貝葉斯優化),這些模型無法進行零樣本預測。
在自然進化過程中,蛋白質遵循一套固有原則,以實現最佳穩定性、功能和效率。在大量天然蛋白質數據集上訓練的 PLM 學習并利用了這些原則,從而實現了特定蛋白質的零樣本優化。然而,酶在類別和催化機制方面具有顯著的多樣性,使用 PLM 選擇有前途的變體仍然是一個挑戰。
此外,當設計一種酶來接受非天然底物并使其具有新功能時,很有可能沒有天然酶具有此功能。在這種情況下,PLM 可能無法學習獲得這種新功能的原理,因此可能無法提供改進的變體。
例如,在這項研究中,PLM 設計了 96 個第一輪變體,其中有 4 個突變目標位點,只有 6 個與野生型相比顯示出更高的適應度值。因此,PLMeAE 主要應用 PLM 來提出明智的突變體和新的突變位點,并將 PLM 與監督機器學習模型相結合,以探索酶的適應度景觀。
這利用了在 PLM 中學習到的原理來指導酶的進化,并確保蛋白質適應度在進化過程中不斷提高。對于更具挑戰性的任務,即目標適應度景觀與天然蛋白質的適應度景觀相差甚遠,PLM 會以非常低的準確率預測變體,導致訓練數據集中沒有陽性變體。
然而,由于研究人員使用基于 ITC 的采樣策略,PLM 預測的變體在序列中具有很高的多樣性,這有助于監督 ML 模型學習適應度景觀。此外,由于僅選擇幾種氨基酸作為突變目標,序列空間有限。使用 PLMeAE 獲得改進的變體仍然很有可能,盡管對于如此具有挑戰性的任務可能需要更多輪進化。
應用潛力
PLMeAE 平臺具有擴展應用的潛力,可以設計通過液相色譜 (LC)、氣相色譜 (GC) 和質譜 (MS) 測量活性的酶。為了加速色譜和質譜分析,已經開發了各種自動化裝置。
盡管 PLMeAE 在蛋白質工程領域具有巨大潛力,但從頭開發新的 PLMeAE 系統卻極具挑戰性,因為需要合成生物學、計算機科學以及實驗室自動化和機器人技術交叉領域的專業知識。
此外,建立新的自動化生物工廠成本高昂。為了克服這些挑戰,必須促進不同學科研究人員之間的合作,并通過人工智能和實驗室自動化的發展培養下一代合成生物學研究人員。
未來,研究人員將能夠在最少的人為干預下高效地進行蛋白質工程。
論文鏈接:https://www.nature.com/articles/s41467-025-56751-8
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
