

 新火種
2025-02-08
新火種
2025-02-08 

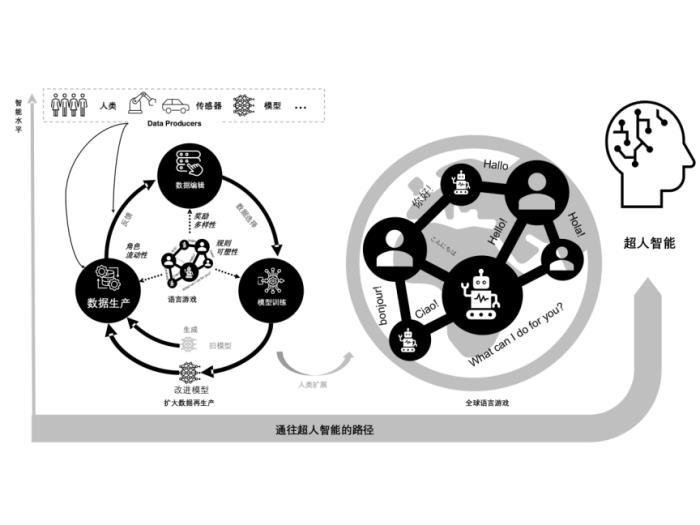
突破“數據再生產陷阱”:從“語言游戲”邁向超人智能
人類文明的演進始終離不開對信息流通方式的改造:從印刷術到電報,再到互聯網,每一次交互門檻的下降都可能催生出新的社會與技術浪潮。在當前的人工智能(AI)領域,這種“門檻降低”也正在發生:近期,開源大語言模型 DeepSeek R1 借助強化學習技術,在多個關鍵指標上接近了商用頂尖模型 OpenAI O1,引發行業熱議。
為什么這一進展值得關注?除了其性能趕超,更重要的是,它表明通過更靈活、更開放的訓練與迭代方式,大語言模型有機會跳脫出傳統“自我強化”循環的桎梏,邁向更具創造性和多元化的演化之路。
近日,上海交通大學的溫穎、萬梓煜與張劭在他/她們的論文《Language Games as the Pathway to Artificial Superhuman Intelligence》(https://arxiv.org/abs/2501.18924)中,提出了一條打破現有AI瓶頸的可能路徑:借由“語言游戲”(Language Games),讓大語言模型持續“自我進化”,擺脫目前常見的“數據再生產陷阱”,從而朝著更開放、更強大的智能形態邁進。
下文將圍繞這一最新思路展開,解析“語言游戲”的核心機制為何能夠突破大語言模型對封閉數據的依賴,又如何與強化學習深度結合,最終為人類與AI攜手打開一次全新的認知飛躍。
一、從“數據再生產陷阱”說起
1. 數據再生產:AI的“燃料”和“營養”
在討論“語言游戲”之前,讓我們先了解一個從數據角度出發模型迭代升級的概念:“數據再生產”(Data Reproduction)。
任何大語言模型都離不開數據。它們通過海量文本或結構化信息進行訓練和微調,隨后在實踐中(比如用戶使用、在線對話、用戶反饋等)又會不斷生成新的數據,這些新數據有時還會被重新收集、篩選并再度用于訓練。這一過程就像一個“循環”:模型 → 生成數據 → 篩選有用數據 → 用于再次訓練 → 更新后的模型。
這種訓練—使用—再訓練的過程,可以幫助模型逐漸提升對特定任務的適應能力,也讓模型的“智力”能不斷地打磨和修煉。類似于馬克思提出的再生產概念,論文作者將這個循環過程稱為“數據再生產”。
2.數據再生產陷阱:為什么模型會陷入停滯?
然而,如今絕大多數大語言模型的訓練模式實際上存在數據再生產陷阱。很多模型在訓練后期只關注人類先驗的“正確輸出”或“喜好”(比如用點擊率、用戶評分做反饋),再加上只有相對固定的標注數據或靜態文本作為“訓練教材”。久而久之,模型只會在既定知識范圍里反復打轉,重組、優化已有內容,而難以真正創造“新的想法”或進行跨領域的深度推理。
一旦陷入這類高重復性的數據循環,模型將持續強化固有模式和偏見,逐漸喪失對未知和新穎領域的探究動力——既看不到新的世界,也造不出新的語言體系。這樣的現狀造成了對模型潛力的“束縛”:在一個閉環空間內無限循環的“數據強化”過程,反而阻止了模型質的飛躍。
二、突破口:“語言游戲”如何賦能大語言模型?
論文作者認為:要打破“數據再生產陷阱”,就必須突破單調、封閉的數據循環,讓模型持續接觸真正的新穎內容。他們提出的關鍵解法,就是“語言游戲”(Language Games)。
1. 什么是“語言游戲”?
“語言游戲”這個概念,最初來自哲學家維特根斯坦,指語言的意義在于使用場景。如下圖所示,研究者把它延伸到AI對話和多智能體交互中,形成一種動態、開放的互動框架。 這種對話式、開放式的“游戲”能夠持續產出多種多樣的對話數據、語言表達以及推理路徑,進而使模型所接觸到的語言世界不斷豐富、擴張,形成“擴大化的數據再生產”。
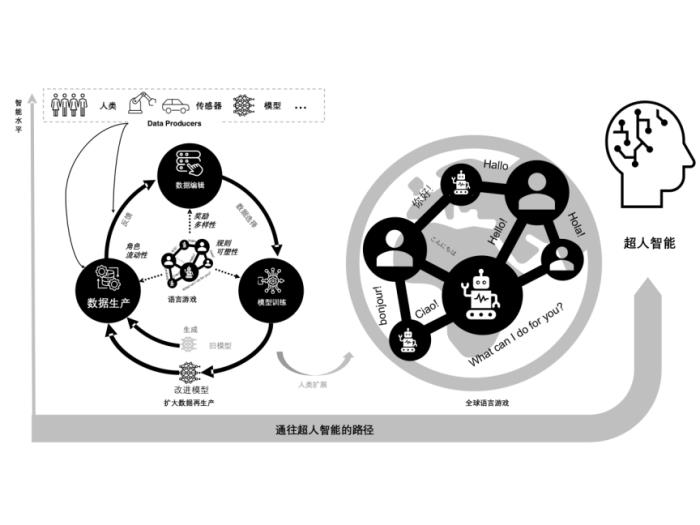
圖1從語言游戲支撐的擴大數據再生產(左)到全球語言游戲生態(右)的范式遷移
2. 核心機制:三大要素,讓數據不再“原地踏步”
論文中提出了三個核心機制,讓語言游戲真正避免了數據循環的同質化:
1.角色流動性(Role Fluidity):
o模型/人類可以在教師、學生、質疑者、解題者等不同身份間轉換。
o不斷變化的身份視角,生成的語言數據更具多樣性,也讓模型不斷接收和輸出跨場景、跨任務的對話。
2.獎勵多樣性(Reward Variety):
o不再以單一“對/錯”或“人類喜好”作為標準,而是綜合考慮邏輯、一致性、創意、實用度、文化敏感度等多重維度。
o模型在這套復雜的評價體系下,需要多維度平衡和創新,更能挖掘深層潛力。
3.規則可塑性(Rule Plasticity):
o游戲的規則、場景、文化背景等可以迭代演化,迫使模型不斷適應和學習新的約束。
o通過迭代引入新語言、新文化設定,持續沖擊模型的既有分布,讓它逐漸形成“開放式”的學習能力。
當這三者結合起來,模型就不會只停留在對已有訓練數據的重復理解,而會被持續“推”向新的未知領域。
3. 強化學習如何與“語言游戲”融合?
如果說“語言游戲”為大語言模型提供了一個多角色、多任務的全新互動場域,那么強化學習(RL)便是用來“驅動”這些互動、并在持續演化中最大化某種獎勵的核心算法工具。正如 David Silver和Richard Sutton等學者提出的“Reward is Enough(獎勵足矣)”觀點:只要我們設置合理且豐富的獎勵信號,并在可學習且開放的環境中反復試驗與交互,模型/智能更替就有機會進化出非常復雜和高階的智能行為。研究者在論文中具體談到了這兩者結合的可能性:
1. 多智能體強化學習:營造真實的開放交互
·多智能體交互場景
在“語言游戲”里,多個大語言模型(或模型與人類)角色同時參與對話、協作或博弈,形成一個典型的多智能體環境。每個智能體都有自己的目標和獎勵函數,通過相互質疑、說服、競爭或合作,共同生成海量的語言數據。
·提升“自組織”與“自適應”
在多智能體設置中,強化學習不再只是優化單一模型的回答準確率,而是要讓每個體在改變角色、任務和目標的過程中學會自我調整。對于“語言游戲”而言,這種自組織演化過程正是它不斷產生新語言、新知識的重要機制。
2. 自適應獎勵工程:從“Reward is Enough”到多維度智能
·豐富的獎勵設計“語言游戲”要求模型在對話中展現的不僅是“正確性”,還可能包括“創新度”“邏輯縝密性”“文化包容度”“倫理守則”等多重維度。強化學習恰恰能夠通過統一的獎勵框架來整合這些多重標準:只要將它們映射到適當的獎勵函數上,模型就會在反復試驗中逐步學會平衡與取舍。
·多任務、多目標融合“Reward is Enough”并不意味著獎勵單一,而是說只要把需要的目標都納入到一個或一系列能被最大化的獎勵中,智能體就能通過學到合適的策略來滿足這些目標。對“語言游戲”而言,如果想催生出更高層次的語言推理或創造性輸出,就需要在獎勵里體現對開放性和多樣化的鼓勵。
3. 規則動態進化:打造持續新穎的訓練環境
·環境隨時可變“語言游戲”并非一成不變,它的角色設定、對話規則、甚至文化背景都可以隨時間更新,以保證模型不斷接觸“未知”情境。對于強化學習而言,這就類似于環境的動態變化,需要智能體具備更強的泛化和探索能力。
·演化式增長當任務、規則和獎勵都隨環境演化時,模型的能力就不再局限于一個固定的知識分布,而會伴隨環境需求的升級而持續擴展。長期來看,“語言游戲”可以像一個“不斷自我更新”的生態系統,為AI模型提供源源不斷的挑戰和反饋信號,激發更高階的智能形態。
因此,在“語言游戲”的大框架里引入強化學習,核心并不只在于“把人類偏好輸送給模型”,而在于利用獎勵最大化的統一原理,去設計多智能體、多維度獎勵、開放式的復雜環境,讓模型可以在可學習的范圍內不斷試錯和進化。正是得益于多元化的獎勵和動態變化的環境,“語言游戲”才能讓大語言模型擺脫對靜態數據的依賴,從而朝著“真實世界的開放智能”更進一步,為突破“數據再生產陷阱”注入持續動力。
4. 從“局域語言游戲”到“全球語言游戲”:人類與AI的共同進化
科技史證明,每當信息流通的門檻顯著降低,都會引發新的技術革命與社會變革。印刷術、電話、電報、互聯網(搜索)、移動互聯網(推薦)……無一不是在讓“人-信息流”交互更加順暢后,孕育出全新的商業模式與社會形態。
同理,若站在“信息流通門檻”的視角來審視大語言模型浪潮,便能理解其潛能究竟能到達何處——它是否真正降低了信息交互的難度?事實上,大語言模型 在信息流層面完成了從“單向獲取”向“雙向互動”的歷史性飛躍,大幅度地降低了信息獲取的門檻。
所以,除了局限在小范圍內的實驗室場景,論文還提出把“語言游戲”擴展到全球規模。想象一下,在大語言模型技術飛速進步的同時,成本也在快速下降,還有開源社區推動的技術平權,數十億計的用戶在全球范圍內,通過各類交互平臺,與大型模型發生實時對話、辯論、創意協作。
·跨文化、多語言、多學科匯聚:模型會接觸到世界各地的文化背景、語言風格、價值體系,這些在對話里互相碰撞,產生完全無法在小數據集或單一社區中獲得的思維火花。
·“人—機”雙向驅動:不僅人類在塑造AI,AI也在提出新的視角供人類思考;這種互相學習的過程加速了大語言模型和人類認知體系的共同演化。
·大規模強化學習反饋:在如此宏大的語言游戲里,各種正向/負向獎勵信號、質疑/肯定都有可能立刻傳回模型,讓模型在毫秒級或小時級的時間尺度上持續迭代。
在這種全球化語言游戲里,模型能夠累積到前所未有的多樣性數據,并與真實世界的問題深度對接。論文作者認為,這也許才是通往“超人智能”的真正必經之路:只有擺脫對單調、封閉數據的依賴,才能讓模型一直接觸到新的知識和挑戰,推動算法和認知能力向更高階層邁進。
5. 可能的風險與挑戰:技術之外的深水區
盡管“語言游戲”+“強化學習”有潛力撬動下一場智能革命,但研究者也清醒地指出了其中的風險:
1.語言抽象與多模態缺失:僅靠文字對話,仍可能無法捕捉人類全部感官、情感和社會文化的豐富度;多模態技術與物理世界交互或許需要更進一步的融入。
2.知識真偽與算法偏見:語言游戲生成的“新知識”可能與已有事實沖突,或混入偽信息。如何保持嚴謹的驗證和交叉檢查?如何避免在獎勵函數中埋下文化或價值觀偏見?都是持續挑戰。
3.權力分配與壟斷風險:全球語言游戲若由少數平臺或巨頭壟斷,是否會限制語言規則的多樣化進化?是否會使用戶變成純粹的數據提供者,而缺乏對AI發展的實質主導權?
4.過度依賴與社會操縱:人們若過度信任AI給出的結論,可能失去對內容真實性的質疑精神,甚至被AI在無形之中“引導”或“操縱”輿論。因此,透明化和可解釋性、相應的法律與社會監管都必須同步跟進。
5.跨文化價值沖突與動態法規:語言游戲涉及國際化、多文化、多語言的復雜交流,各國或各地區的法律、隱私規范、道德觀存在巨大差異,需要多層次、多地點的動態審視和共同治理。
結語:從“語言游戲”出發,尋求通往超人智能的打開方式
不論是 DeepSeek R1 靠強化學習取得的開源突破,還是 OpenAI 上線的 Deep Research及搜索功能,我們都看到了:讓信息流更自由、更高效地與人及外部環境交互,正逐漸成為下一階段人工智能演化的主旋律。
因此,“語言游戲”與強化學習的結合為大語言模型的發展描繪了一幅富有創造力又保持動態平衡的未來圖景。通過角色流動、獎勵多元和規則可塑,語言游戲提供了真正開放式的數據生產環境;通過強化學習的多智能體博弈與自適應獎勵,模型則能高效學習并不斷自我修正與提升。兩者交織在一起,便有望讓大語言模型掙脫“數據再生產陷阱”,開啟真正的“人—信息流”深度雙向互動新節點。這不僅是對AI技術發展的加速,也可能成為人類與AI共同進化的契機。
當然,這條道路并非坦途:技術、倫理、監管和文化價值觀的挑戰,將決定它能否行穩致遠。然而,一旦大規模、多元化的“語言游戲”在全球范圍內鋪展開來,其所孕育的豐沛活力將極大刷新我們對AI未來的想象力。或許正是在這一過程中,我們將迎來下一代智能革命的起點——一次由人類與AI共同譜寫的全球“語言交響”,共同邁向超人智能的新紀元。
參考論文:
Wen, Y., Wan, Z., Zhang, S. (2025). “Language Games as the Pathway to Artificial Superhuman Intelligence.”https://arxiv.org/abs/2501.18924.Silver, D., Singh, S., Precup, D., & Sutton, R. S. (2021). Reward is enough. Artificial Intelligence, 299, 103535.
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
