

 新火種
2025-02-07
新火種
2025-02-07 


LLM自主發(fā)現(xiàn)發(fā)表在Nature上的科學假設?ICLR2025論文MOOSE-Chem深度解析

編輯 | ScienceAI
人工智能的下一個前沿,不僅是語言、圖像,而是科學發(fā)現(xiàn)本身。
近年來,人工智能(AI)已經在自然語言處理(NLP)、計算機視覺(CV)等領域取得巨大成功。但 AI 是否能夠幫助科學家發(fā)現(xiàn)新的科學理論?
在 ICLR 2025 接收的一篇論文《MOOSE-Chem: Large Language Models for Rediscovering Unseen Chemistry Scientific Hypotheses》提出了一個令人興奮的問題:
大模型(LLMs)能否在僅依賴化學研究背景信息的情況下,自動發(fā)現(xiàn)新的、有效的化學科學假設?
這項研究發(fā)現(xiàn) LLM 可以自主發(fā)現(xiàn)新穎(novel)且可行(valid)的科學假設,甚至可以重新發(fā)現(xiàn)那些已經發(fā)表在 Nature, Science 上的頂級化學科學假設。
這項研究通過劃分使用的 LLM 的 pretrain data 的截止時間,與 Nature, Science 上文章的 online 時間確保這種重新發(fā)現(xiàn)不是由于數(shù)據(jù)污染(data contamination),而是由于 LLM 本身的能力。
這項研究不僅提供了關于科學假設形成的數(shù)學建模,還提出了 Agentic AI for scientific discovery 的 framework,讓 LLM 能夠自動生成并篩選科學假設,為 AI 在科學研究中的應用提供了新思路。

MOOSE-Chem 研究的核心假設是:
化學研究假設 h 不是憑空創(chuàng)造的,而是由研究背景 b 和若干研究靈感 i 組合而成的。
研究團隊通過認知科學、論文分析和數(shù)學建模,系統(tǒng)性地驗證了這一假設的合理性,并建立了數(shù)學推導,形成 AI 可執(zhí)行的科學發(fā)現(xiàn)框架。
MOOSE-Chem 核心假設的提出
(1) 認知科學的啟發(fā)
創(chuàng)造力研究表明,創(chuàng)新通常來自已有知識的重新組合,這一點可以追溯到:
知識重組理論(Knowledge Recombination)(Koestler, 1964):科學發(fā)現(xiàn)往往源于跨領域知識的結合。聯(lián)想理論(Association Theory):創(chuàng)新通常通過已有概念的連接產生。例如:
反向傳播(Backpropagation)算法來源于「鏈式求導 + 多層神經網絡」。許多新型催化劑的發(fā)現(xiàn)來源于「已有材料 + 新工藝」的結合。這些理論表明,化學研究假設很可能是由背景知識(b)+ 研究靈感(i) 組合產生的。
(2) 頂級化學論文的分析

研究團隊通過利用核心假設,鏈式法則,和引入馬爾科夫性質,得到 P( h | b)的一個約等式。
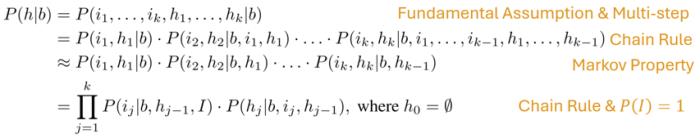
最終研究團隊得到 。其中,I代表所有的(化學)科學文獻。該約等式將復雜的難以建模的 P( h | b)轉換成了一系列難度顯著降低的可以建模的小項的乘積。
。其中,I代表所有的(化學)科學文獻。該約等式將復雜的難以建模的 P( h | b)轉換成了一系列難度顯著降低的可以建模的小項的乘積。
MOOSE-Chem 框架詳解:AI 如何進行自動科學發(fā)現(xiàn)?


1. 文獻檢索(Literature Retrieval)——找到潛在研究靈感: 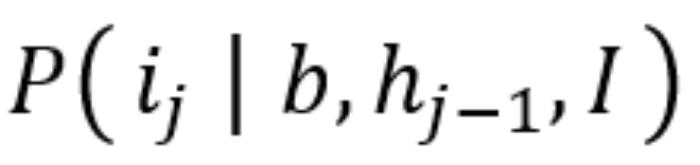
MOOSE-Chem 在這一過程中使用了大語言模型(LLMs)結合信息檢索的方法,幫助 AI 從大量化學論文中篩選出可能的研究靈感。
方法:
基于 LLM 的語義檢索
·研究背景 作為輸入,LLM 通過語義相似性搜索(Semantic Search)在論文數(shù)據(jù)庫 中找到相關研究。·例如,如果研究背景涉及某種新型催化劑,LLM 會檢索相關的催化劑研究,并提取其中的關鍵技術或方法。2. 假設生成(Hypothesis Generation)——從背景和靈感構造研究假設: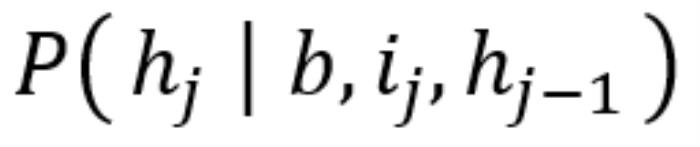
有了研究靈感后,MOOSE-Chem 需要根據(jù)背景信息和靈感,構造新的科學假設。這個過程類似于科學家在頭腦風暴時結合已有知識提出研究方向。
方法:
(1)基于 LLM 的 Prompt 生成
 例如,如果背景涉及某種電化學反應,靈感來自某種新的催化材料,LLM 會根據(jù)新的催化材料來構造新型電化學方案。
例如,如果背景涉及某種電化學反應,靈感來自某種新的催化材料,LLM 會根據(jù)新的催化材料來構造新型電化學方案。(2)進化優(yōu)化(Evolutionary Optimization)
僅靠 LLM 直接生成假設并不能保證其高質量,因此 MOOSE-Chem 進一步采用進化算法(Evolutionary Algorithm)優(yōu)化假設。這一過程包含三個關鍵步驟:
變異(Mutation):對初始假設進行調整,例如改變催化劑的類別、調整反應條件等,以探索更多可能性。精煉(Refinement):讓 LLM 通過自我反饋機制對假設進行改進,使其更加科學合理。例如,模型可能會檢查是否有足夠的實驗依據(jù)支持假設,或調整表達方式以提高清晰度。重組(Recombination):從多個假設變體中篩選最佳元素,組合成最終的高質量假設。這類似于科學家在論文寫作過程中不斷優(yōu)化研究思路的過程。3. 假設排序(Hypothesis Ranking)——篩選最優(yōu)科學假設
MOOSE-Chem 生成了多個可能的研究假設,但并非所有假設都合理。因此,MOOSE-Chem 需要對生成的假設進行評估,并篩選出最優(yōu)的科學假設。
方法:
基于 GPT-4o 的評分
讓 GPT-4o 評估每個假設的創(chuàng)新性、合理性、實驗可行性。主要實驗結果
1、LLM 能夠成功識別與研究背景相關但未知的啟發(fā)性論文
在 3000 篇論文庫中,LLM 能夠找到 75% 以上的真實啟發(fā)論文,即使只篩選出 4% 的論文。結果表明,LLM 可能已經學習到了許多科學家未知的知識關聯(lián)。2、LLM 能夠基于已知知識推理出高質量的新知識
采用嚴格背景信息和文獻篩選策略后,LLM 生成的假設與真實假設的相似度較高:28個假設的最高匹配評分(Top MS)為 4 或 5 分(滿分 5 分)其中 9 個假設的最高匹配評分達到了 5 分(幾乎與真實假設一致)說明 LLM 具備從背景+啟發(fā)中推理出創(chuàng)新性假設的能力。3、LLM 能夠有效地對假設進行排名
采用 LLM 評分機制,高質量假設通常排名更高。與真實論文中使用的啟發(fā)數(shù)量相關性較強,即:啟發(fā)匹配越多,排名越高
匹配評分越高,排名越高
說明 LLM 在一定程度上能夠篩選出更有價值的假設。最終發(fā)現(xiàn)
1、MOOSE-Chem 生成的假設可以在不訪問真實假設的情況下,覆蓋論文的核心創(chuàng)新點。
在51篇論文的評測中,近 40% 的實驗生成假設與真實假設高度相似。
專家評估顯示,在模擬現(xiàn)實科學研究環(huán)境(300 篇論文庫)下,MOOSE-Chem 仍能生成接近真實論文的假設。
2、多步啟發(fā)和變異/重組策略有效提升了假設質量。
相比現(xiàn)有方法(如SciMON, MOOSE),MOOSE-Chem 在最高匹配評分(Top MS)和平均匹配評分(Average MS)上均有顯著提升:MOOSE-Chem:Top MS = 4.02, Avg MS = 2.56MOOSE: Top MS = 2.88, Avg MS = 2.46SciMON(NLP/Biochemical 領域):Top MS = 2.55, Avg MS = 2.28說明進化算法(mutation & recombination)能夠提升假設的創(chuàng)造性和合理性。3、在實際應用中,MOOSE-Chem 可作為科研助理協(xié)助研究人員提出高質量假設。
在科學研究過程中,MOOSE-Chem 可用于自動檢索啟發(fā)性文獻、生成研究假設,并提供初步篩選排名,減少研究人員的篩選和構思時間。相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
