

 新火種
2025-01-17
新火種
2025-01-17 

阿里云通義開源最強過程獎勵PRM模型,7B尺寸比GPT-4o更能發現推理錯誤
1月16日,阿里云通義開源全新的數學推理過程獎勵模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同類開源過程獎勵模型;在識別推理錯誤步驟能力上,Qwen2.5-Math-PRM以7B的小尺寸就超越了GPT-4o。同時,通義團隊還開源首個步驟級的評估標準ProcessBench,填補了大模型推理過程錯誤評估的空白。
在當前大模型推理過程中,不時存在邏輯錯誤或編造看似合理的推理步驟,如何準確識破過程謬誤并減少它,對增強大模型推理能力、提升推理可信度尤為關鍵。過程獎勵模型(Process Reward Model, PRM)為解決這一問題提供了一種極有前景的新方法:PRM對推理過程中的每一步行為都進行評估及反饋,幫助模型更好學習和優化推理策略,最終提升大模型推理能力。
基于PRM的理念,通義團隊提出了一種簡單有效的過程獎勵數據構造方法,將PRM模型常用的蒙特卡洛估計方法(MC estimation)與大模型判斷(LLM-as-a-judge)創新融合,提供更可靠的推理過程反饋。通義團隊基于Qwen2.5-Math-Instruct模型進行微調,從而得到72B及7B的Qwen2.5-Math-PRM模型,模型的數據利用率和評測性能表現均顯著提高。
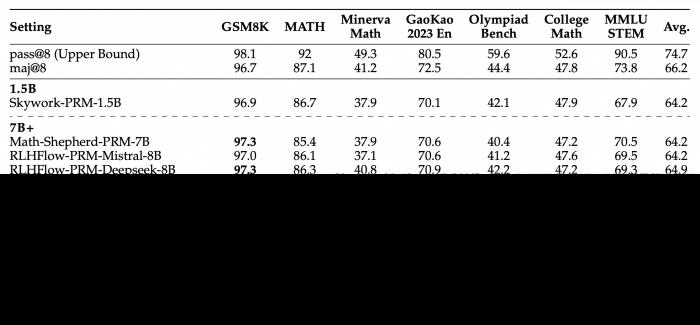
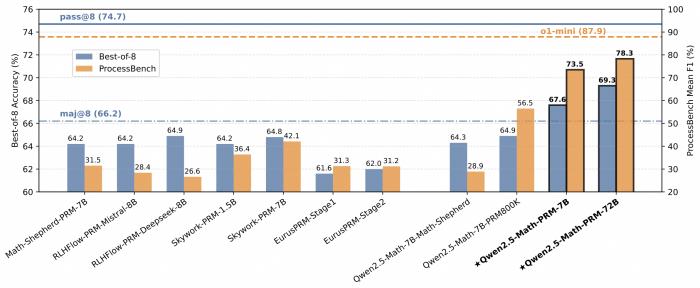
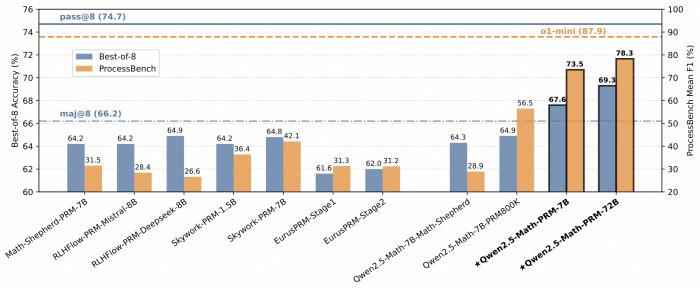
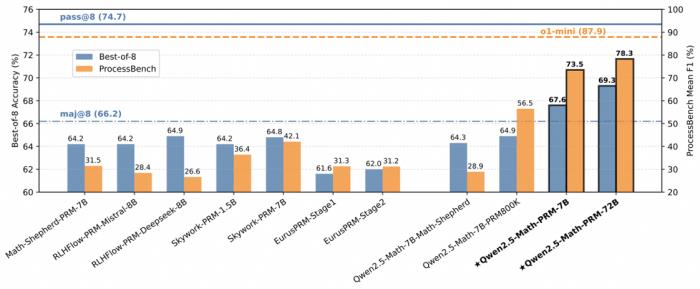
在包含GSM8K、MATH、Minerva Math等7個數學基準測試的 Best-of-N 評測中,Qwen2.5-Math-PRM-7B性能表現超越了同尺寸的開源PRMs;Qwen2.5-Math-PRM-72B的整體性能在評測中拔得頭籌,優于同尺寸ORM(Outcome Reward Model )結果獎勵模型Qwen2.5-Math-RM-72B。
同時,為更好衡量模型識別數學推理中錯誤步驟的能力,通義團隊提出了全新的評估標準ProcessBench。該基準由3400個數學問題測試案例組成,其中還包含奧賽難度的題目,每個案例都有人類專家標注的逐步推理過程,可綜合全面評估模型識別錯誤步驟能力。這一評估標準也已開源。
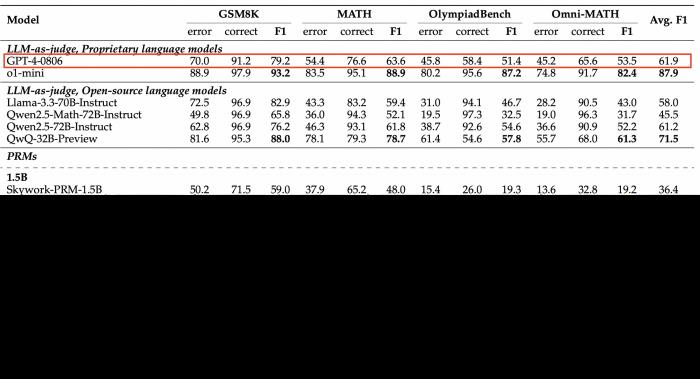
在ProcessBench上對錯誤步驟的識別能力的評估中,72B及7B尺寸的Qwen2.5-Math-PRM均顯示出顯著的優勢,7B版本的PRM模型不但超越同尺寸開源PRM模型,甚至超越了閉源GPT-4o-0806。這印證了過程獎勵模型PRM可有效提升推理可靠性,對未來推理過程監督技術的研發提供新思路。
相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
