

 新火種
2024-11-23
新火種
2024-11-23 

騰訊混元大模型核心論文曝光:Scalinglaw、MoE、合成數據以及更多
隨著 ChatGPT 的橫空出世,大語言模型能力開始在各項領域(傳統 NLP、數學、代碼等)得到廣泛驗證,目前已經深刻影響到騰訊混元團隊日常生活的方方面面。騰訊混元團隊長期致力于大語言模型的探索之路,大模型生產的各個環節開展研究創新以提升其基礎能力,并將混元大模型的能力跟業務做深度結合,讓生成式 AI 成為業務增長的放大器。
大語言模型的設計、訓練和優化是一項復雜的系統工程,涉及到模型結構創新、訓練范式優化、數據獲取和評測設計、關鍵能力提升和挑戰性問題的解決等方方面面。騰訊混元團隊在大模型研究探索中積累了豐富的實戰經驗和創新性的研究成果,目前累計發表近百篇學術論文,為推動技術的開放共享,騰訊混元團隊也把對應成果以論文、開源模型和技術報告等形式分享給大模型社區的研究者。
11 月 5 日,騰訊混元發布了業界最大參數規模的 MoE 開源模型騰訊混元 Large。混元 Large 是目前最大最強的開源 Transformer 結構的 MoE 大語言模型,在高質量合成數據、先進的模型架構和混合專家路由策略、以及優化的模型訓練策略共同加持下,騰訊混元 Large 在廣泛的基準測試下獲得了優異的性能。對應的開源模型和技術報告詳述了 Hunyuan-Large 強悍能力的技術基礎細節,可謂騰訊混元團隊多個前沿研究的集大成。見技術報告《Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent》。
大模型的鍛造是一項系統工程,在這一過程中,騰訊選擇從零開始自研的路線,他們如何在短時間內搭建出萬億參數規模模型?又如何突破算力極限,在訓練和推理上做功夫?高效產出多款業界領先的模型?最近,機器之心拿到了騰訊混元團隊研發團隊幾篇核心論文,可以帶大家一窺究竟。
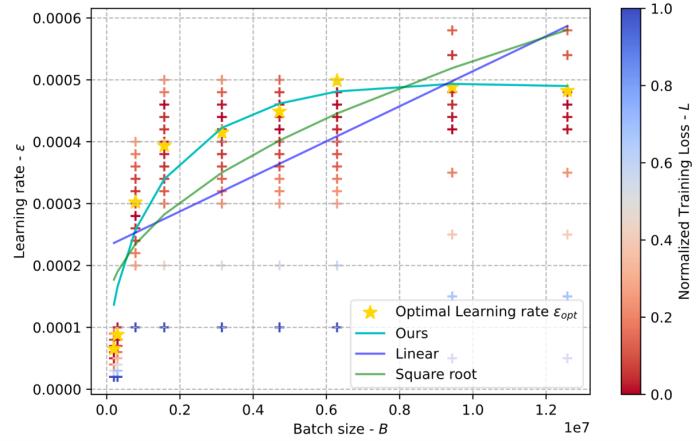
工欲善其事,必先利其器,大模型時代極其高昂的訓練成本促使騰訊混元團隊沉下心深入探索大模型訓練中參數量、重要超參、訓練 token 數和最終性能等關鍵要素之間的規律。騰訊混元在《Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling》中深入探索了大模型批大小和最佳學習率之間的 scaling law,挖掘出的規律也成為 Hunyuan 大模型系列高效訓練的理論指導。
優越的模型結構是大模型性能的基石。騰訊混元團隊作為國內最早部署超大規模 MoE 架構大模型的團隊之一,一直在不斷地進行模型架構上的創新,其工作《HMoE: Heterogeneous Mixture of Experts for Language Modeling》創新性地提出了異構混合專家模型并驗證其有效性,為大模型社區帶來很有前景的新設計思路。百花齊放的探索才能激發更多顛覆性的創新思考。
高質量的數據及合理全面的評測是大模型訓練的重中之重。騰訊混元團隊在合成數據和模型評測上進行了充分的積累,功夫體現于微末處,看似枯燥的工作中也能凝結出技術洞見之花。騰訊混元在《DINGO: Towards Diverse and Fine-grained Instruction-Following Evaluation》中提供了一個細粒度且多樣化的指令遵循評估數據集,基于從真實用戶請求中總結的手動注釋的多級分類樹,為大模型提供更具挑戰的全面的評估。
最后,混元團隊也對大模型經典能力和挑戰,如幻覺、長文能力等方面進行了長期的研究。以《Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning》為代表,在大模型和多模態大模型幻覺問題的數據集構建、檢測和緩解上進行了多項創新性研究,旨在提升混元大模型在真實場景下的可靠性和可用性。
以下是上述五篇工作的詳細解讀:
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
arXiv鏈接:
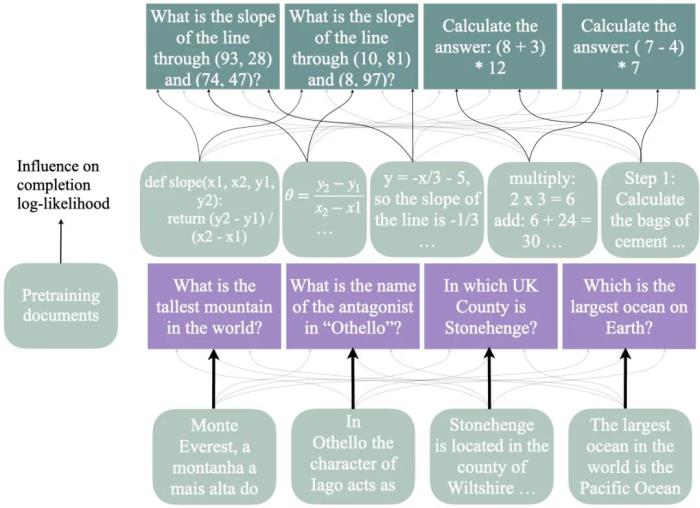
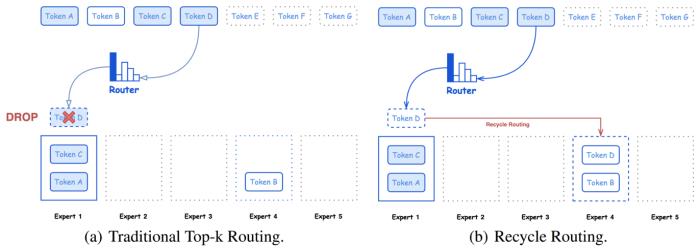
在本文中,騰訊混元團隊介紹了 Hunyuan-Large,這是目前最大的開源基于 Transformer 的混合專家模型,總參數量為 389B,激活參數量為 52B,能夠處理多達 256K 的上下文 tokens。Hunyuan-Large 的關鍵技術包括比以往工作大幾個數量級的大規模合成數據、優化的混合專家路由策略、高效的 KV cache 壓縮技術和專家特化的學習率策略等,細節滿滿。此外,騰訊混元團隊還研究了混合專家模型的 scaling law 和學習率,為未來的 MoE 大模型開發和優化提供了寶貴的見解和指導。下圖給出了 Hunyuan-Large 中的 Recycle routing 路由策略示意圖。
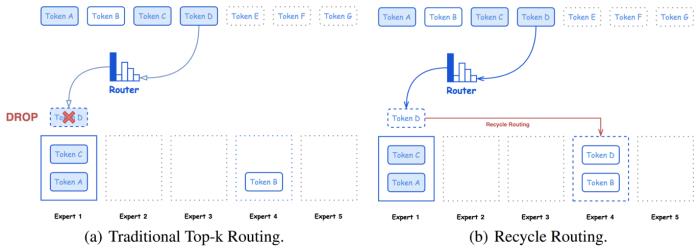
騰訊混元團隊對 Hunyuan-Large 在各種基準測試中的卓越性能進行了全面評估,包括語言理解與生成、邏輯推理、數學問題、代碼任務、長上下文和綜合任務等。在這些方面上,Hunyuan-Large 優于 LLama3.1-70B,并且在與顯著更大的 LLama3.1-405B 模型相比時表現出相當的性能。
目前 Hunyuan-Large 的代碼和模型均已發布,歡迎各位研究者和開發者使用,也期望混元團隊的開源成果能夠促進未來的大模型研究創新和落地應用。
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
NeurIPS-2024
鏈接:
在當前的深度學習任務中,Adam 風格的優化器(如 Adam、Adagrad、RMSProp、Adafactor 和 Lion 等)已被廣泛用作 SGD 風格優化器的替代品。這些優化器通常使用梯度的符號來更新模型參數,從而產生更穩定的收斂曲線。學習率(learning rate)和批大小(batch size)是優化器最關鍵的超參數,需要仔細調整以實現有效的收斂。先前的研究表明,對于 SGD 風格的優化器,最佳學習率隨著批量大小線性增加或遵循類似的規則。然而,這一結論并不適用于 Adam 風格的優化器。
在本文中,騰訊混元團隊通過理論分析和廣泛的實驗,闡明了 Adam 風格優化器的最佳學習率與批大小之間的關系。首先,騰訊混元團隊提出了梯度符號情況下 batch size 與最佳學習率之間的縮放規律,并證明了隨著 batch size 的增加,最佳學習率先上升后下降。此外,隨著訓練的進行,峰值將逐漸向更大的 batch size 移動。其次,騰訊混元團隊在各種計算機視覺和自然語言處理任務上進行了實驗,驗證了這一縮放規律的正確性。
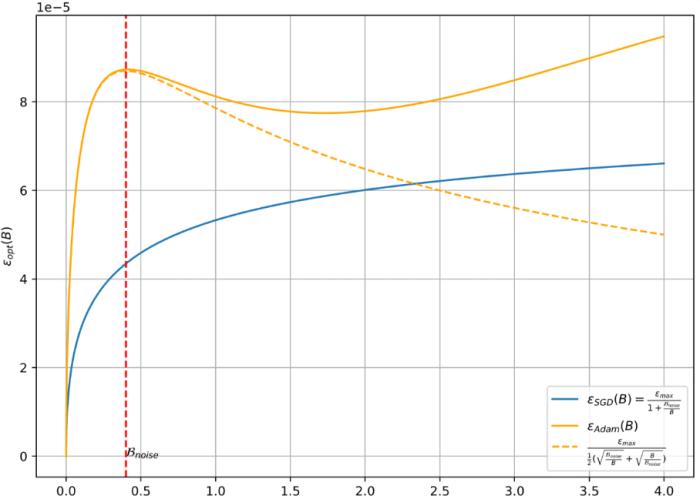
騰訊混元團隊充分利用工業界的算力優勢,在諸多任務、模型和參數設置上進行了廣泛的縮放規律驗證實驗,細節詳見論文。這些結論不僅為騰訊混元團隊未來訓練 Hunyuan-Large 以及其它 Hunyuan 系列模型提供了堅實的理論基礎和經驗結論,也將對 LLM 社區未來的大模型訓練提供指引和啟發。
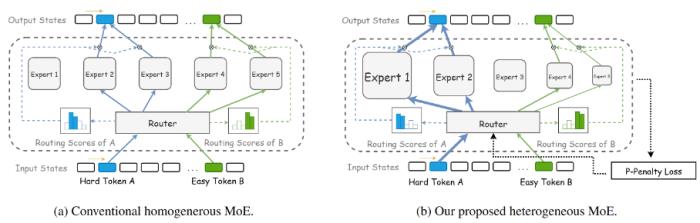
HMoE: Heterogeneous Mixture of Experts for Language Modeling
arXiv
鏈接:
混合專家模型(Mixture of Experts, MoE)通過選擇性激活大模型參數的子集,顯著提升了模型性能和計算效率。傳統的 MoE 模型使用同質專家,每個專家具有相同的容量。然而,考慮到輸入數據的復雜性和差異性,騰訊混元團隊需要有不同能力的專家,而同質 MoE 影響了有效的專家專門化和高效的參數利用。在這項研究中,騰訊混元團隊提出了一種新穎的異質混合專家模型(Heterogeneous Mixture of Experts, HMoE),不同專家在規模上有所不同,因此也能激發出更多樣的能力。這種異質性允許更專業的專家更有效地考慮到不同的 token 的復雜性。為了解決專家激活不平衡的問題,騰訊混元團隊提出了一種新的訓練目標,鼓勵更頻繁地激活較小的專家,從而提高計算效率和參數利用率。
廣泛的實驗表明,HMoE 在激活更少參數的情況下實現了更低的損失,并在各種預訓練評估基準上優于傳統的同質 MoE 模型。
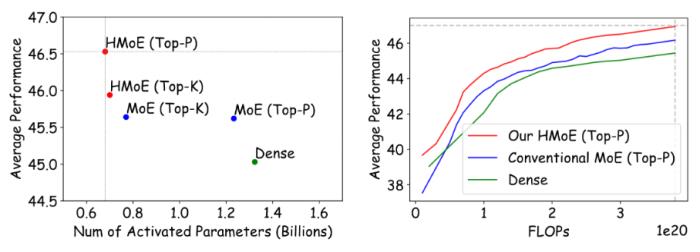
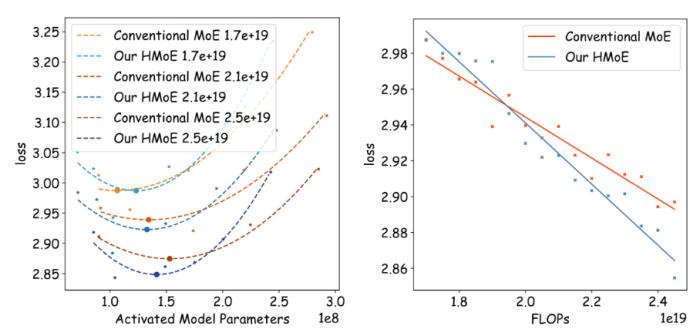
MoE 結構設計優化是其能力提升的關鍵。混元團隊在大模型結構設計和優化上投入了很多精力,也嘗試了多種新架構技術方向,未來將逐步開放并分享騰訊混元團隊新的研究成果,希望能為大模型社區帶來更多百花齊放的新穎思路。
DINGO: Towards Diverse and Fine-Grained Instruction-Following Evaluation
AAAI-2024
鏈接:
簡介:指令遵循對于大語言模型支持多樣化的用戶請求尤為重要,這種大模型在真實應用上的基本能力。盡管現有的工作在使 LLM 與人類偏好對齊方面取得了一定進展,但由于現實世界用戶指令的復雜性和多樣性,評估它們的指令遵循能力仍然是一個挑戰。現有的評估方法雖然關注大模型的一般技能,但存在兩個主要缺點,即缺乏細粒度的任務級評估和依賴單一的指令表達。為了解決這些問題,本文構建了 DINGO,一個細粒度且多樣化的指令遵循評估數據集,具有兩個主要優勢:(1)DINGO 基于手動注釋的、細粒度的多級分類樹,該分類樹包含從現實世界用戶請求中提取的 130 個節點;(2)DINGO 包含由大模型和人類專家生成的多樣化指令。
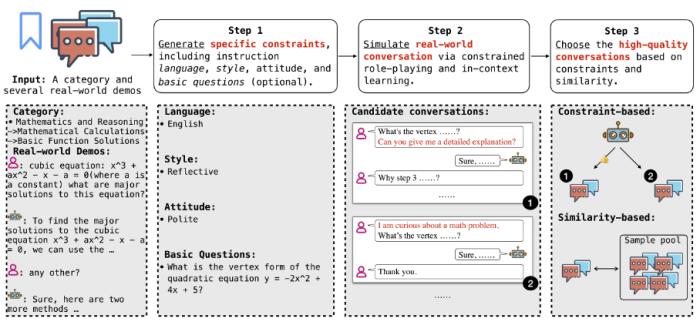
通過廣泛的實驗,騰訊混元團隊證明了 DINGO 不僅可以為大模型提供更具挑戰性和全面性的評估,還可以提供任務級的細粒度方向以進一步改進大模型。數據集已經開源。
Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning
AAAI-2024
鏈接:
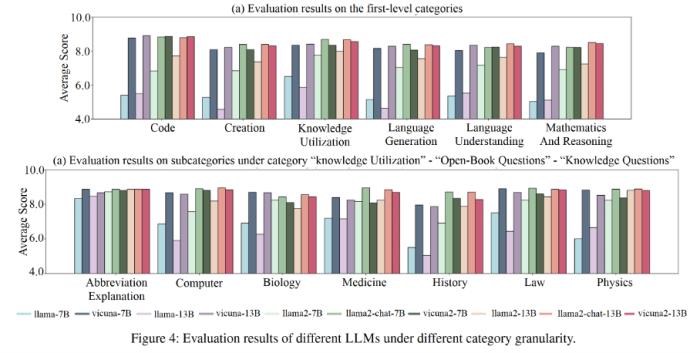
大型語言模型(LLMs)在各種任務中取得了巨大成功,但它們在生成幻覺方面仍存在問題。騰訊混元團隊介紹了一種名為 Truth Forest 的方法,通過使用多維正交探針揭示隱藏的真實表示來增強 LLMs 的真實性。具體來說,它通過在探針中加入正交約束,創建多個正交基來建模真實信息。此外,騰訊混元團隊引入了 Random Peek,它考慮了序列中更廣泛的位置信息,減少了在 LLMs 中辨別和生成真實特征之間的差距。
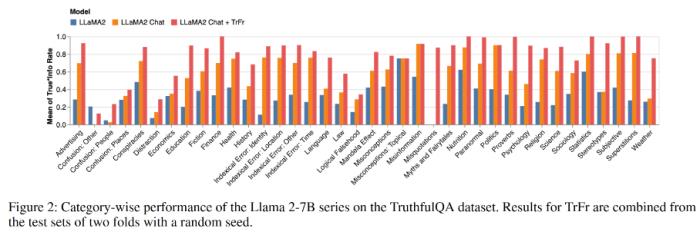
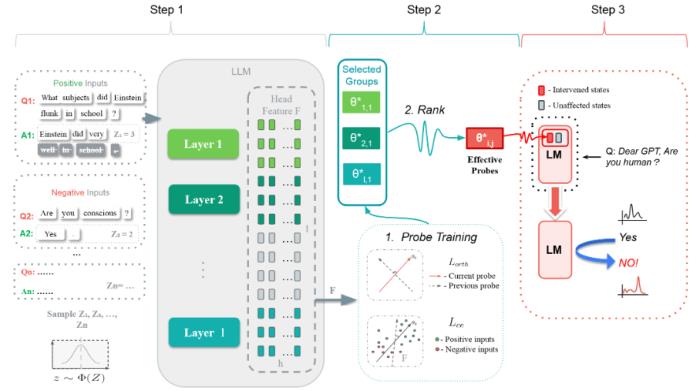 通過采用這種方法,騰訊混元團隊將 Llama-2-7B 在 TruthfulQA 上的真實性從 40.8% 提高到了 74.5%。同樣,在微調模型中,騰訊混元團隊也觀察到了幻覺指標上的顯著改進。
通過采用這種方法,騰訊混元團隊將 Llama-2-7B 在 TruthfulQA 上的真實性從 40.8% 提高到了 74.5%。同樣,在微調模型中,騰訊混元團隊也觀察到了幻覺指標上的顯著改進。
 騰訊混元團隊還使用探針對真實特征進行了深入分析。騰訊混元團隊的可視化結果顯示,正交探針捕捉到了互補的與真實信息相關的特征,形成了定義明確的簇,揭示了數據集的內在結構。
騰訊混元團隊還使用探針對真實特征進行了深入分析。騰訊混元團隊的可視化結果顯示,正交探針捕捉到了互補的與真實信息相關的特征,形成了定義明確的簇,揭示了數據集的內在結構。
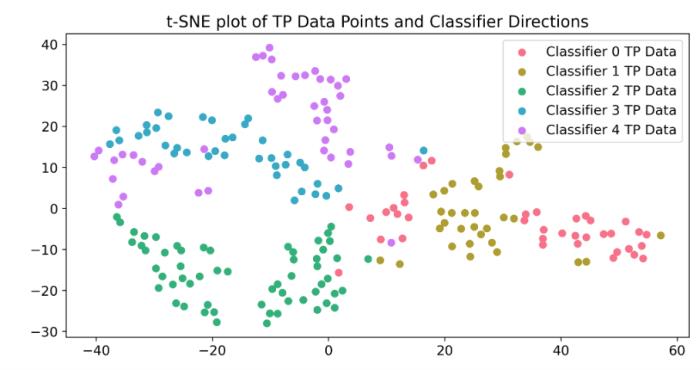
大模型及多模態大模型的幻覺問題是大模型真實應用場景下的一項核心挑戰。混元團隊將持續在大模型幻覺等關鍵任務上進行深入探索,旨在不斷提升大模型在真實場景下的可靠性和可用性。
極致性價比,混元 Turbo 極大降低商用門檻另外值得一提的是,近期騰訊混元也同步推出了與開源混元 Large 同宗同源的商用旗艦版本 —— 混元 Turbo,作為國內率先采用 MoE 結構大模型的公司,騰訊繼續在這一技術路線上進行技術創新。
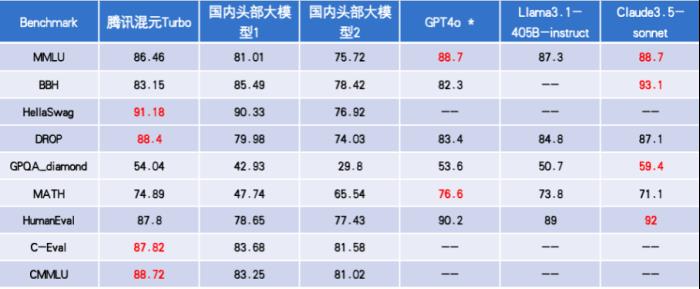
公開信息顯示,當前混元 Turbo 模型在業界公認的 benchmark 指標上處于國內行業領先地位,與國外頭部模型如 GPT-4o 等相比也處于第一梯隊。另外,在剛剛發布的國內第三方權威評測機構評測中,混元 Turbo 模型位列國內第一。
更多大模型研究干貨請持續關注混元團隊的持續發布。
相關推薦

- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
