

 新火種
2024-11-05
新火種
2024-11-05 

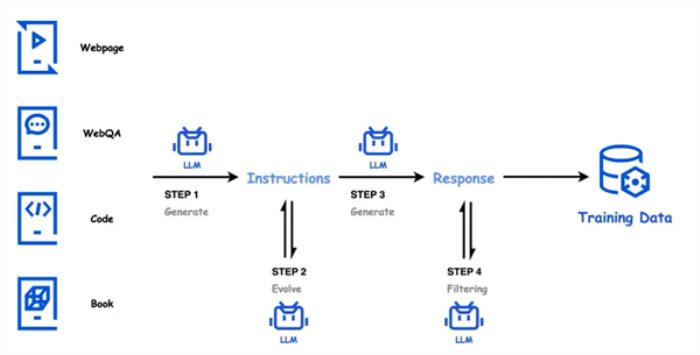
騰訊發布開源MoE大語言模型Hunyuan-large:總參數398B為業內最大
11月5日消息,騰訊今日宣布推出業界參數規模最大、效果最好的開源MoE大語言模型Hunyuan-Large。
Huanyuan-large模型的總參數量為389B、激活參數為52B、訓練token數量為7T、最大上下文長度為256K、詞表大小為12.8w。
在技術創新方面,Hunyuan-large通過高質量的合成數據來增強模型訓練,彌補了自然數據的不足。
其中,該模型預訓練支持處理高達256K的文本序列,大幅提升了長文本上下文的處理能力,能夠更高效地完成長文本任務。
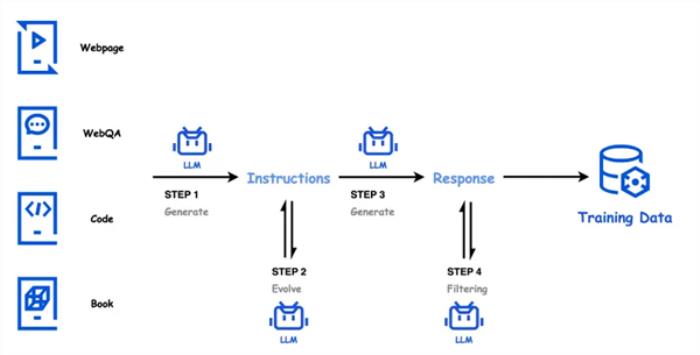
據了解,Hunyuan-large在CMMLU、MMLU、CEva1、MATH等多學科綜合評測集上表現優異,在中英文自然語言處理、代碼生成、數學運算等9大能力維度中全面領先,超越了Llama3.1和Mixtral等一流開源模型。
此外,騰訊還宣布將推出自研的長文評測集“企鵝卷軸(PenguinScrolls)”,以填補行業在真實長文評測集上的空白。
企鵝卷軸基于公開的金融、法律、學術論文等長文本構建,文本長度從1K到128K不等,覆蓋深度閱讀理解和長文推理任務。

相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
