

 新火種
2024-04-15
新火種
2024-04-15 


谷歌爆改Transformer,“無限注意力”讓1B小模型讀完10部小說
谷歌大改Transformer,“無限”長度上下文來了。
現在,1B大模型上下文長度可擴展到1M(100萬token,大約相當于10部小說),并能完成Passkey檢索任務。
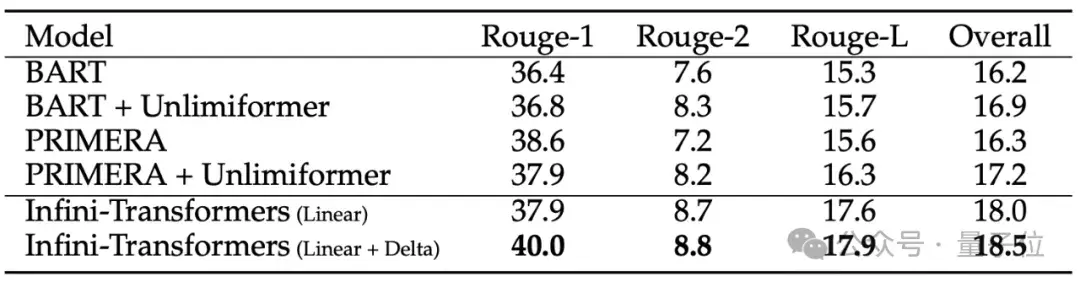
8B大模型在500K上下文長度的書籍摘要任務中,拿下最新SOTA。
這就是谷歌最新提出的Infini-attention機制(無限注意力)。

它能讓Transformer架構大模型在有限的計算資源里處理無限長的輸入,在內存大小上實現114倍壓縮比。
什么概念?
就是在內存大小不變的情況下,放進去114倍多的信息。好比一個存放100本書的圖書館,通過新技術能存儲11400本書了。
這項最新成果立馬引發學術圈關注,大佬紛紛圍觀。

加之最近DeepMind也改進了Transformer架構,使其可以動態分配計算資源,以此提高訓練效率。
有人感慨,基于最近幾個新進展,感覺大模型越來越像一個包含高度可替換、商品化組件的軟件棧了。

引入壓縮記憶
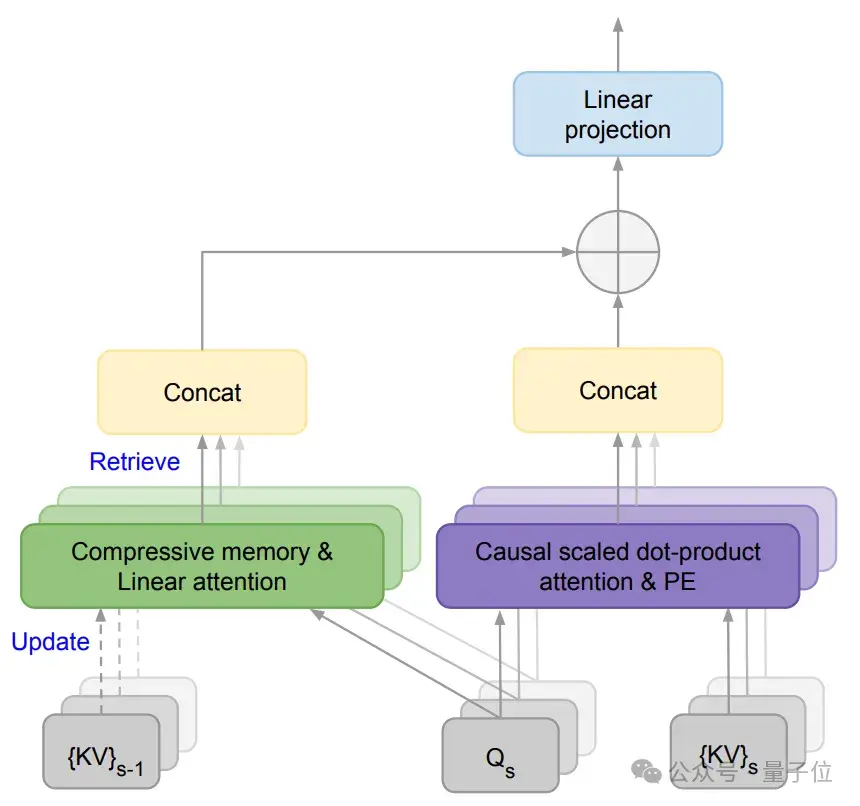
該論文核心提出了一種新機制Infini-attention。
它通過將壓縮記憶(compressive memory)整合到線性注意力機制中,用來處理無限長上下文。
壓縮記憶允許模型在處理新輸入時保留和重用之前的上下文信息。它通過固定數量的參數來存儲和回憶信息,而不是隨著輸入序列長度的增加而增加參數量,能減少內存占用和計算成本。
線性注意力機制不同于傳統Transformer中的二次方復雜度注意力機制,它能通過更小的計算開銷來檢索和更新長期記憶。
在Infini-attention中,舊的KV狀態({KV}s-1)被存儲在壓縮記憶中,而不是被丟棄。
通過將查詢與壓縮記憶中存儲的鍵值進行匹配,模型就可以檢索到相關的值。
PE表示位置嵌入,用于給模型提供序列中元素的位置信息。
對比來看Transformer-XL,它只緩存最后一段KV狀態,在處理新的序列段時就會丟棄舊的鍵值對,所以它只能保留最近一段的上下文信息。
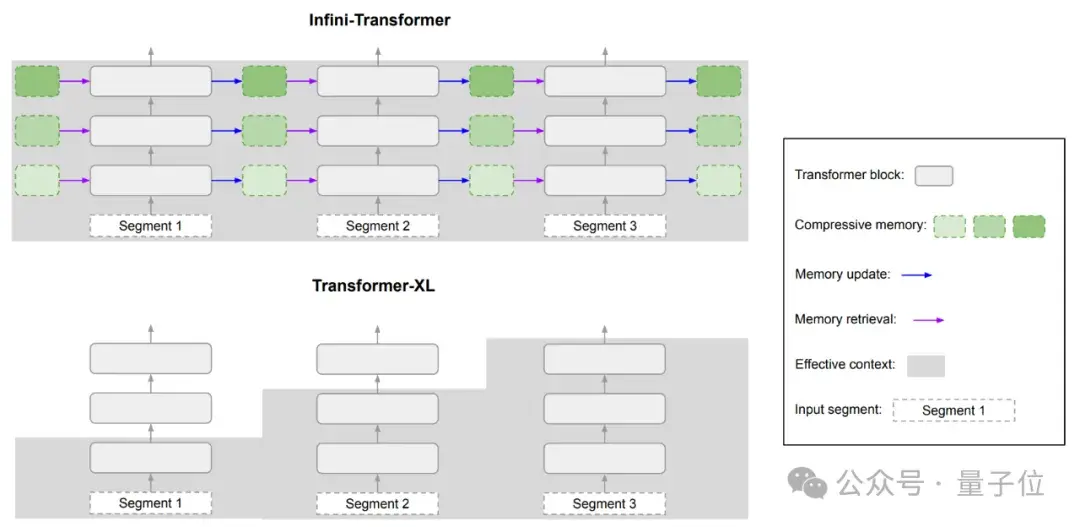
對比幾種不同Transformer模型可處理上下文的長度和內存占用情況。
Infini-attention能在內存占用低的情況下,有效處理非常長的序列。

Infini-attention在訓練后,分化出了兩種不同類型的注意力頭,它們協同處理長期和短期上下文信息。
專門化的頭(Specialized heads):這些頭在訓練過程中學習到了特定的功能,它們的門控得分(gating score)接近0或1。這意味著它們要么通過局部注意力機制處理當前的上下文信息,要么從壓縮記憶中檢索信息。
混合頭(Mixer heads):這些頭的門控得分接近0.5,它們的作用是將當前的上下文信息和長期記憶內容聚合到單一的輸出中。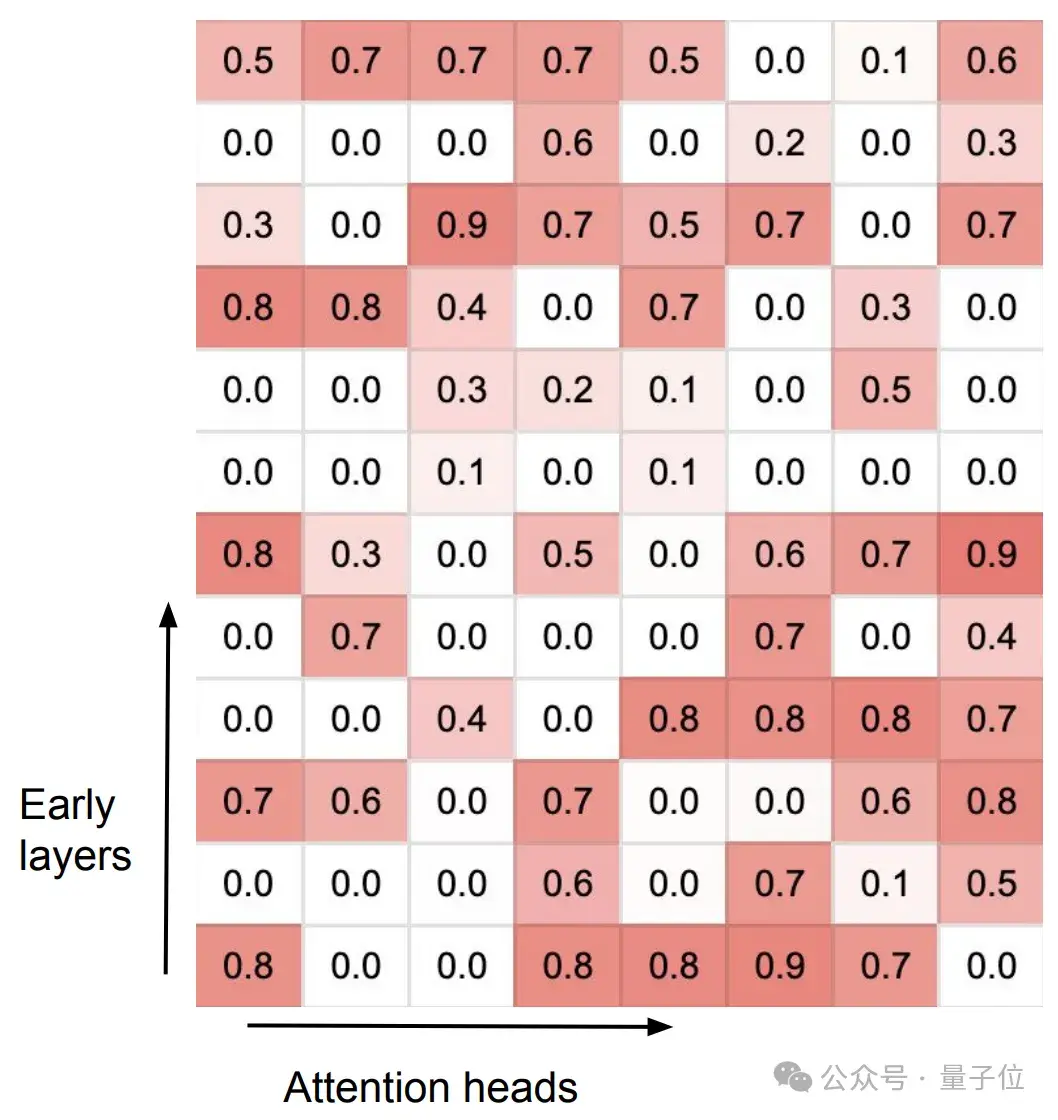
研究團隊將訓練長度增加到100K,在Arxiv-math數據集上進行訓練。
在長下文語言建模任務中,Infini-attention在保持低內存占用的同時,困惑度更低。
對比來看,同樣情況下Memorizing Transformer存儲參數所需的內存是Infini-attention的114倍。
消融實驗比較了“線性”和“線性+增量”記憶兩種模式,結果顯示性能相當。

實驗結果顯示,即使在輸入只有5K進行微調的情況下,Infini-Transformer可成功搞定1M長度(100萬)的passkey檢索任務。
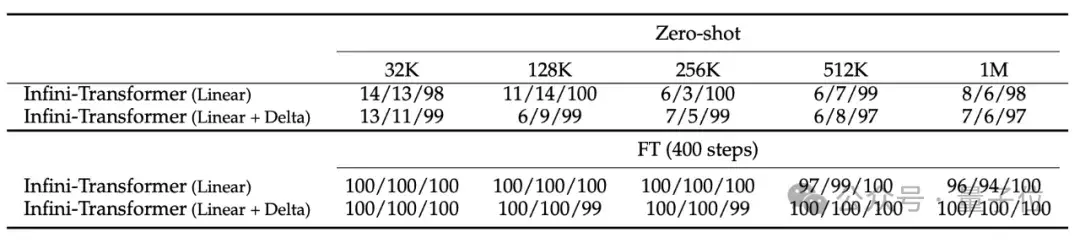
在處理長達500K長度的書籍摘要任務時,Infini-Transformer達到最新SOTA。
Bard成員參與研究
該研究由谷歌團隊帶來。
其中一位作者(Manaal Faruqui)在Bard團隊,領導研究Bard的模型質量、指令遵循等問題。

最近,DeepMind的一項工作也關注到了高效處理長序列數據上。他們提出了兩個新的RNN模型,在高效處理長序列時還實現了和Transformer模型相當的性能和效率。

感覺到谷歌最近的研究重點之一就是長文本,論文在陸續公布。
網友覺得,很難了解哪些是真正開始推行使用的,哪些只是一些研究員心血來潮的成果。
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
