

 新火種
2024-03-11
新火種
2024-03-11 


人大系初創(chuàng)與OpenAI三次“撞車”:類Sora架構(gòu)一年前已發(fā)論文
Sora一出,諸多創(chuàng)業(yè)公司的命運(yùn)因之改變。
我們最近聽說了個(gè)超級(jí)戲劇性的故事,就在中國,就是中關(guān)村的一家創(chuàng)業(yè)公司:
Sora出世前,他們拿著一篇如今被ICLR 2024接收的論文,十分費(fèi)勁地為投資人、求知者講了大半年,卻處處碰壁。
春節(jié)后,打電話來約見團(tuán)隊(duì)的投資人排起了長隊(duì),都是要學(xué)習(xí)Sora、學(xué)習(xí)團(tuán)隊(duì)論文成果。
為什么?
答案很簡單,Sora本來就是新晉頂流,再一次親身實(shí)踐了scaling law的正確可行。
更何況Sora背后的架構(gòu),與這支團(tuán)隊(duì)快1年前發(fā)表的論文提出的基于Transformer的Video統(tǒng)一生成框架,大、撞、車。
撞車到什么程度呢?用團(tuán)隊(duì)自身的話來說,“可以說是幾乎一模一樣,嗯,就還得仔細(xì)地找到底哪里不同”。
敢這么說話,有點(diǎn)意思。
要知道,國內(nèi)諸多團(tuán)隊(duì)都在通往AGI的道路上苦苦耕耘,但很多人至今還是很不看好國內(nèi)團(tuán)隊(duì)的技術(shù)創(chuàng)新能力。如果事實(shí)真像團(tuán)隊(duì)所說,那這就是國內(nèi)隊(duì)伍有實(shí)力做最前沿創(chuàng)新的實(shí)際證明。
于是,新火種得知后,火速聯(lián)系上這個(gè)團(tuán)隊(duì),帶著大家第一時(shí)間把撞車瓜徹底吃透。
(淺淺劇透一下,后來我們發(fā)現(xiàn)跟Sora撞車這個(gè)瓜背后,還有更戲劇的故事)

誰在和OpenAI“撞車”?
不賣關(guān)子,和OpenAI“撞車”的這家初創(chuàng)公司,正是成立于2021年的智子引擎。
而在它的身上,有太多的屬性和標(biāo)簽值得說道說道。
90后CEO:由中國人民大學(xué)高瓴人工智能學(xué)院博士生高一釗創(chuàng)立。人大系:核心團(tuán)隊(duì)成員多數(shù)來自人大,并且由高瓴人工智能學(xué)院盧志武教授擔(dān)任顧問一職。多模態(tài)大模型:公司成立之際大語言模型依舊是主流,卻早早打入多模態(tài)這條“無人區(qū)”的賽道。
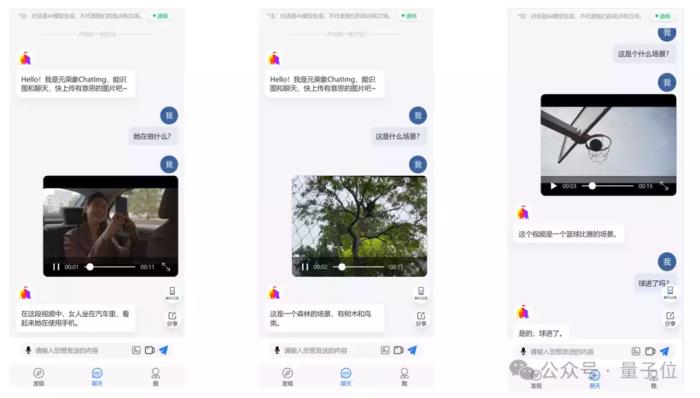
從目前智子引擎所交出的“作業(yè)”來看,最為矚目當(dāng)屬于2023年3月發(fā)布的世界首個(gè)公開評(píng)測(cè)多模態(tài)對(duì)話應(yīng)用ChatImg(元乘象),并且已經(jīng)迭代到了3.5版本。
例如給ChatImg隨機(jī)投喂一張圖片,它可以立即用看圖說話,用文字精準(zhǔn)描述圖片中的內(nèi)容。
而且在問及觀點(diǎn)性問題時(shí),例如“是否合理”,ChatImg的回答也是近乎接近人類的理解。
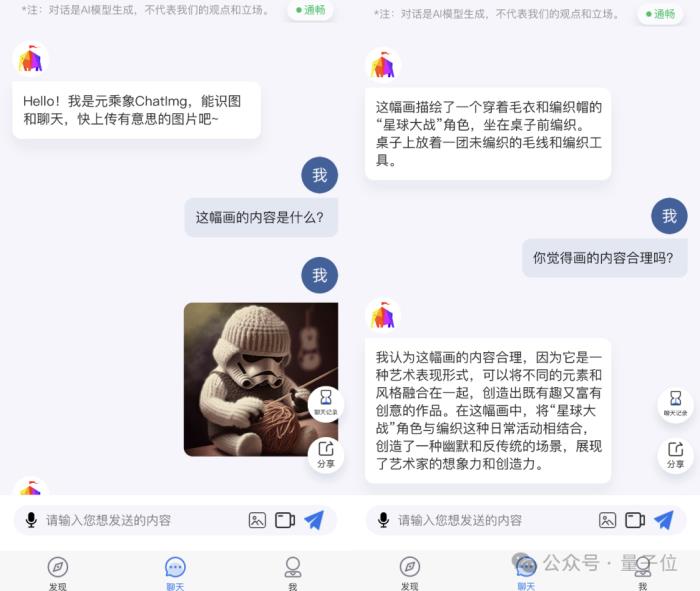
至于剛才提到與Sora“撞車”的論文,正是由這家“人大系”初創(chuàng)領(lǐng)銜,并聯(lián)合伯克利、港大等單位于2023年5月發(fā)表在arXiv上的VDT。

在我們與盧志武教授交流過程中,他這樣形容看到Sora技術(shù)報(bào)告后的感受:
因?yàn)镾ora在技術(shù)架構(gòu)上所采用的是Diffusion Transformer,這是區(qū)別于以往文生視頻(基于Stable Diffusion等)工作的關(guān)鍵點(diǎn)之一。
而僅從VDT論文的標(biāo)題中,我們就不難發(fā)現(xiàn),智子引擎在技術(shù)架構(gòu)上早已提出并采用了Diffusion Transformer,而且是首發(fā)的那種。
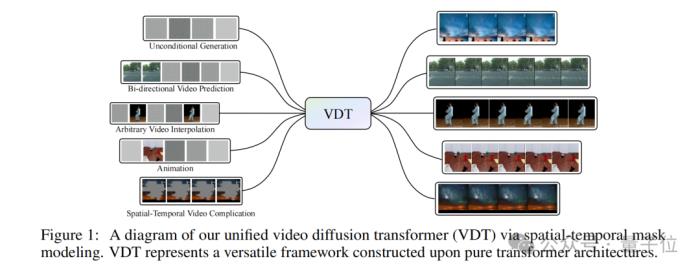
但單從Diffusion Transformer還不足以說明“大撞車”,我們還需看一下VDT論文里的個(gè)中細(xì)節(jié)。
首先,在時(shí)空注意力機(jī)制方面,VDT在Transformer中集成了專門設(shè)計(jì)的時(shí)間注意力和空間注意力模塊,這樣就可以讓模型能夠更好地捕捉和理解視頻數(shù)據(jù)中的時(shí)空關(guān)系。
舉個(gè)例子:
,假設(shè)你在看一部電影,導(dǎo)演通過鏡頭的切換和場(chǎng)景的布局來引導(dǎo)你關(guān)注故事的關(guān)鍵部分。時(shí)空注意力機(jī)制就像這樣的導(dǎo)演,它讓VDT能夠捕捉視頻中的關(guān)鍵時(shí)刻和動(dòng)作,使得生成的視頻更加生動(dòng)和連貫。
其次,是模塊化設(shè)計(jì),VDT的Transformer塊是模塊化的,這意味著它可以根據(jù)不同的視頻生成任務(wù)靈活調(diào)整,而不需要對(duì)整個(gè)模型架構(gòu)進(jìn)行大規(guī)模修改。
模塊化設(shè)計(jì)就好比像樂高積木一樣,可以用不同的積木塊來構(gòu)建各種形狀和結(jié)構(gòu),通過組合不同的模塊來適應(yīng)不同的視頻生成任務(wù),比如制作動(dòng)畫或者預(yù)測(cè)未來的視頻幀等等。
最后,則是VDT提出的一種統(tǒng)一的時(shí)空掩模建模機(jī)制,可以允許模型在不同的視頻生成任務(wù)中使用相同的架構(gòu),通過調(diào)整掩模來適應(yīng)不同的輸入和輸出需求。
它就宛如一個(gè)多功能工具箱,里面的工具可以用來做各種不同的修理工作,不需要額外為每種工作單獨(dú)購買工具;因此,VDT能夠在多種視頻生成任務(wù)中發(fā)揮作用,而不需要每次都重新訓(xùn)練。
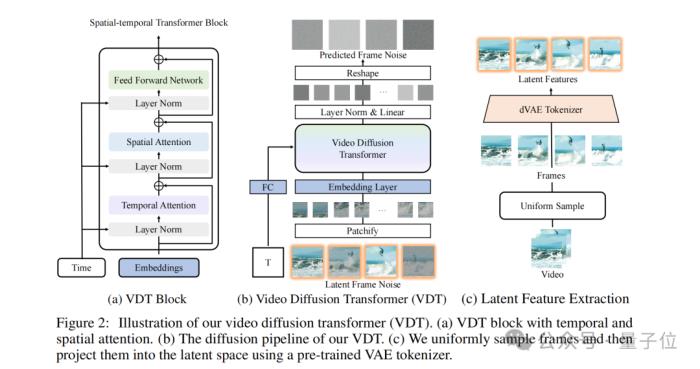
然后我們?cè)賹?duì)比Sora技術(shù)報(bào)告和VDT論文,就不難發(fā)現(xiàn)二者的大體思路是非常相似的。
例如Sora基于Transformer的特性使得它天然具有處理時(shí)空數(shù)據(jù)的能力,因?yàn)樗梢圆蹲揭曨l中的長期依賴關(guān)系。
Sora使用了一個(gè)視頻壓縮網(wǎng)絡(luò)來降低視覺數(shù)據(jù)的維度,這可以看作是一種模塊化設(shè)計(jì),因?yàn)樗鼘⒁曨l處理分解為壓縮和解碼兩個(gè)獨(dú)立的步驟。
以及Sora能夠處理不同時(shí)長、分辨率和寬高比的視頻和圖像,這表明它也有一個(gè)類似“多功能工具箱”一樣的統(tǒng)一表示方法來處理各種類型的輸入數(shù)據(jù)。
至于區(qū)別之處,可能僅是一些實(shí)現(xiàn)方法上的細(xì)節(jié)。
例如在時(shí)空維度的處理上,VDT是分別進(jìn)行注意力機(jī)制,而Sora則是將時(shí)間和空間統(tǒng)一,進(jìn)行單一的處理;再如Sora還考慮到了將文本條件融合等等。
既然技術(shù)上如此高度相似,很多人或許也會(huì)好奇,為什么Sora能做出來長達(dá)1分鐘的高質(zhì)量視頻,而VDT卻沒能出效果呢?
對(duì)此,盧志武教授也做出了解釋:
除此之外,盧志武教授也坦然地承認(rèn),要是想要做到Sora的效果,還需要非常龐大的算力支撐,這一點(diǎn)對(duì)于高校實(shí)驗(yàn)室來說著實(shí)是有些困難。
總而言之,無論是從發(fā)布時(shí)間還是技術(shù)架構(gòu)來看,VDT在技術(shù)路線上確實(shí)是與OpenAI的Sora發(fā)生了一次“撞車”事件。
不過有趣的一點(diǎn)是,在我們與智子引擎交流過程中還發(fā)現(xiàn)了更加戲劇性的事情——
這不是第一次與OpenAI“撞車”,前后竟然足足發(fā)生過三次!
一直與OpenAI同路,此前已經(jīng)兩次“撞車”
先簡單概括,智子引擎和OpenAI三次撞車,第一次是與Clip,第二次是與GPT-4V,第三次就是與剛剛發(fā)布的Sora。
乍一聽,可能會(huì)覺得有點(diǎn)想笑,怎么智子引擎像是大模型屆的汪峰(汪峰老師對(duì)不起),每次都被OpenAI搶過風(fēng)頭?
但你仔細(xì)想想,這可能是一種側(cè)面說明:
這支國內(nèi)團(tuán)隊(duì)長久地和OpenAI一路同行,在不知哪條路是通往AGI的情況下,甚至某些OpenAI都沒有打樣的時(shí)刻,居然每一步都走對(duì)了。

下面詳細(xì)說說同樣令人慨嘆萬千的“撞車”事件——
第一次與OpenAI發(fā)生“撞車”的故事,時(shí)間還需要追溯到2020年。
當(dāng)時(shí)智子引擎并沒有成立公司,彼時(shí)國內(nèi)外在大模型技術(shù)上也還是聚焦于文本,例如OpenAI的GPT-3,以及國內(nèi)北京智源人工智能研究院悟道項(xiàng)目等等。
但盧志武教授和高瓴人工智能學(xué)院的團(tuán)隊(duì)(即核心團(tuán)隊(duì)前身)便已經(jīng)著手準(zhǔn)備自研多模態(tài)大模型;方式是參與到由高瓴人工智能學(xué)院院長文繼榮帶隊(duì)的悟道·文瀾。
到了2020年12月,這支小分隊(duì)便已經(jīng)完成了文瀾的訓(xùn)練工作并發(fā)布了1.0的版本,是國內(nèi)第一個(gè)大規(guī)模預(yù)訓(xùn)練的多模態(tài)模型,并首次運(yùn)用多模態(tài)弱相關(guān)概念完成訓(xùn)練。
而時(shí)隔僅一個(gè)月,OpenAI便在多模態(tài)大模型領(lǐng)域出手了——2021年1月發(fā)布CLIP。由此,文瀾和CLIP一道,成為了多模態(tài)領(lǐng)域的開山之作。
值得一提的是,在同年的6月份,文瀾還進(jìn)行了一次迭代,發(fā)布2.0版本,參數(shù)量為50億,訓(xùn)練數(shù)據(jù)量達(dá)6.5億。
并且相關(guān)論文還在2022年被Nature Communications接收,成為世界首個(gè)被Nature子刊接收的多模態(tài)領(lǐng)域論文。
不難看出,智子引擎前身團(tuán)隊(duì)早在數(shù)年前便已經(jīng)和OpenAI在多模態(tài)大模型的研究和進(jìn)展上保持了近乎相同甚至超前的節(jié)奏。
這便是智子引擎與OpenAI的第一次“撞車”。

自身已經(jīng)有所研究和理解,加之OpenAI也在跟進(jìn),因此,這支隊(duì)伍認(rèn)為多模態(tài)大模型是值得繼續(xù)做下去的方向。
于是正如我們剛才提到的,智子引擎在2021年正式成立,公司的“標(biāo)簽”也是非常明確,就是多模態(tài)大模型。
而這也為智子引擎與OpenAI的第二次“撞車”埋下了伏筆。
2023年3月8日,在潛心“苦修”了長達(dá)兩年之久過后,正如我們剛才提到的,智子引擎正式發(fā)布了自己的第一個(gè)多模態(tài)產(chǎn)品——
ChatImg,是世界首個(gè)公開評(píng)測(cè)的通用多模態(tài)對(duì)話應(yīng)用。
據(jù)了解,ChatImg在技術(shù)上是基于多模態(tài)融合模塊和語言解碼器,參數(shù)量大約為150億,主打的就是讓AI學(xué)會(huì)看圖說話。
除了剛才我們展示的例子之外,ChatImg甚至是可以看一眼圖片,然后直接給用戶編故事。
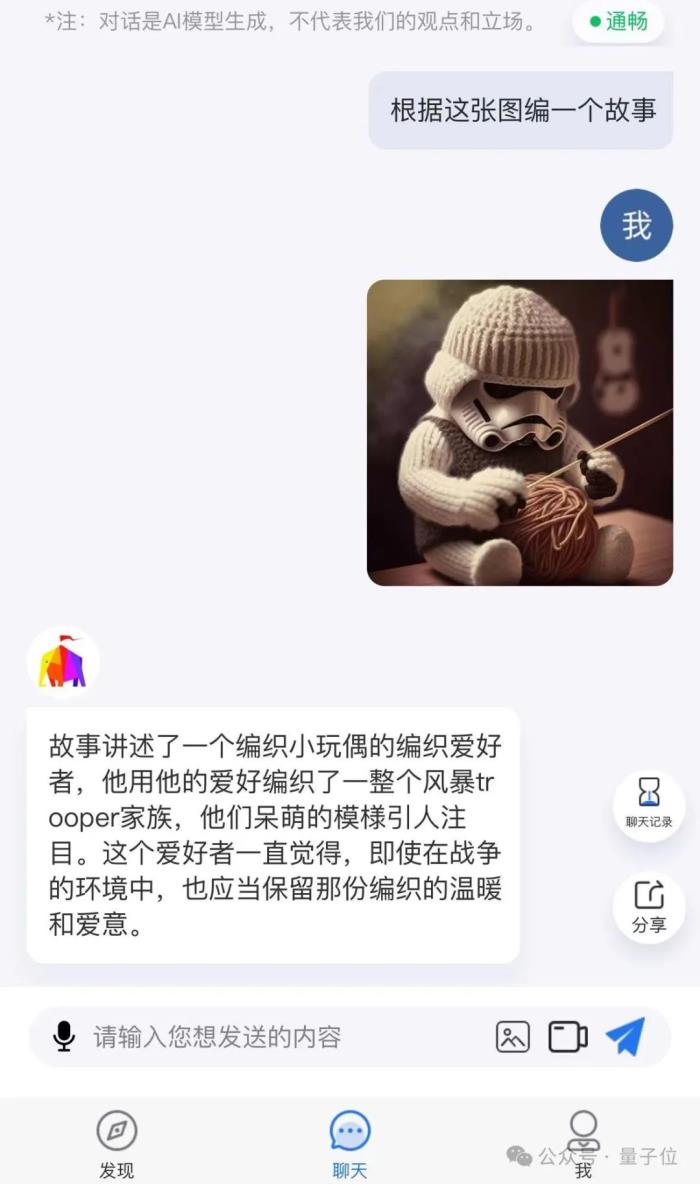
而OpenAI這邊,則是在2023年3月15日,發(fā)布了其多模態(tài)預(yù)訓(xùn)練大模型GPT-4。
在這一節(jié)點(diǎn)上,智子引擎再次與OpenAI在多模態(tài)大模型上“撞了一次車”,并且是提前發(fā)布了整整一周的那種。
至于智子引擎為何會(huì)選擇3月8日,其實(shí)也與OpenAI有著千絲萬縷的關(guān)系,用盧志武教授的話來說就是:
然而,這還是第二次“撞車”的一個(gè)開始。
在ChatImg發(fā)布2個(gè)月之后,智子引擎便將其迭代到了2.0版本,這一次,更是將看視頻說話的功能融入了進(jìn)來。
而OpenAI在多模態(tài)領(lǐng)域后來的大動(dòng)作,應(yīng)當(dāng)屬同年9月份所發(fā)布的GPT-4V,新增了語言和圖像交互功能。
但從5月份到現(xiàn)在這期間,智子引擎在多模態(tài)大模型上的腳步其實(shí)也并沒有放緩。
除了剛才我們提到的與Sora相似架構(gòu)的VDT研究之外,智子引擎更多的是將精力投入到了如何把ChatImg用起來。
正如高一釗在與我們交流過程中所述:
因此,從商業(yè)化的角度來看,智子引擎似乎在多模態(tài)領(lǐng)域又比OpenAI提前了一步。
在智子引擎這里,多模態(tài)技術(shù)與商業(yè)化是并駕齊驅(qū)的。團(tuán)隊(duì)看來,與AI研發(fā)相比,應(yīng)用場(chǎng)景的拓展和落地同等重要,二者雙線程推進(jìn),才能形成閉環(huán)效應(yīng)。
在電網(wǎng)、電力、化工、巡檢等多個(gè)場(chǎng)景,基于大模型的泛化能力和涌現(xiàn)特性,智子引擎已經(jīng)利用一個(gè)多模態(tài)大模型,滿足了過去十幾乃至幾十個(gè)小模型才能解決的實(shí)際需求。
“我們對(duì)2024年收入實(shí)現(xiàn)爆發(fā)性增長非常有信心。”商業(yè)化進(jìn)展順利,研發(fā)的資金支持也就有了眉目。
那么接下來的一個(gè)問題:
三次“撞車”,意味著什么?
Sora為AI視頻賽道再添一把烈火后,大家都在打問號(hào),和一年前拿著ChatGPT追問如出一轍:
誰能第一個(gè)復(fù)現(xiàn)Sora?在奔向AGI終極目標(biāo)的道路上,我們與國外的差距,是不是又被拉大了?
但冷靜下來,看看咱們手里已經(jīng)有了的技術(shù),事實(shí)或許并沒有那么悲觀。
就拿智子引擎來說吧,和OpenAI技術(shù)路線的撞車一次,可能是單純的巧合,或有許多運(yùn)氣成分在。
但三個(gè)顛覆性節(jié)點(diǎn)的三次撞車,似乎已經(jīng)能夠說明,國內(nèi)確確實(shí)實(shí)有這么一家大模型公司代表,長年以來所堅(jiān)持的通往AGI的技術(shù)路線,步子其實(shí)都踩在后來公認(rèn)的正確路線上。
甚至有一兩步,還邁在了業(yè)內(nèi)王者OpenAI之前。
這還只是一家公司。別忘了,智子引擎只是國內(nèi)大模型初創(chuàng)公司的一個(gè)典型代表,是業(yè)界學(xué)界千千萬萬AI研究團(tuán)隊(duì)的縮影。
我們近期搜集到不少業(yè)內(nèi)人士討論及觀點(diǎn)——尤其是Claude 3問鼎全球大模型王座,在多個(gè)角度超越GPT-4后,大伙兒對(duì)OpenAI的過分神話更加趨于冷靜。
甚至開始呼吁,目光不必過多聚焦在國外巨頭身上。
放眼國內(nèi),也有很多成果是世界領(lǐng)先、值得借鑒的。不少還像智子引擎的VDT一樣,不僅走在世界前面的,更重要的是,核心技術(shù)是國內(nèi)學(xué)者原創(chuàng)提出的。
Sora時(shí)代,我們與最尖端的水平,或許比GPT時(shí)代的差距更小。
當(dāng)然了,也許你和我們一樣有疑問,都說了技術(shù)撞車,還發(fā)表在前,為什么拿出震驚世界demo的,不是VDT而是Sora?
“因?yàn)橛?jì)算資源的限制,我們沒能做出OpenAI那樣長達(dá)60s的高質(zhì)量視頻。”但第三次撞車給智子引擎帶來的不只是遺憾,也不只是對(duì)團(tuán)隊(duì)思路的外部肯定。
更多的還有數(shù)不清的機(jī)會(huì)——
現(xiàn)在,因?yàn)镾ora的舉世矚目,VDT這樣曾經(jīng)給外人講不透的技術(shù)來到聚光燈下,得到了更多的曝光。
一切都有了更大的可能性。
相關(guān)推薦




- 免責(zé)聲明
- 本文所包含的觀點(diǎn)僅代表作者個(gè)人看法,不代表新火種的觀點(diǎn)。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對(duì)本文可能提及或鏈接的任何項(xiàng)目不表示認(rèn)可。 交易和投資涉及高風(fēng)險(xiǎn),讀者在采取與本文內(nèi)容相關(guān)的任何行動(dòng)之前,請(qǐng)務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨(dú)立判斷。新火種不對(duì)因依賴本文觀點(diǎn)而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
