

 新火種
2024-02-20
新火種
2024-02-20 


離開OpenAI的大神卡帕西“開課了”:新項目日增千星,還是熟悉的min代碼風(fēng)
大神Karpathy從OpenAI離職,原本揚言要大休一周。
但轉(zhuǎn)眼,新項目就已上線GitHub,日增上千星的那種。
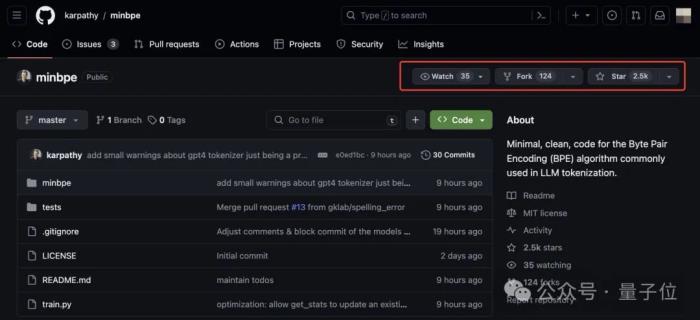
還是熟悉的卡式配方:
74行Python代碼搞定大模型標(biāo)記化(tokenization)中常用的BPE(Byte Pair Encoding)算法,實現(xiàn)該算法的最小、最干凈代碼版本。
甚至:

是不是有點快3萬標(biāo)星的nanoGPT內(nèi)味兒了?
這波啊,還真是讓網(wǎng)友們給猜著了:

畢竟,Karpathy除了前特斯拉AI總監(jiān)、OpenAI創(chuàng)始成員的title,最為網(wǎng)友所熟悉的,就是“AI領(lǐng)域大善人”、“擅長將復(fù)雜問題簡單化的卡老師”這樣的身份了(手動狗頭)。
BPE代碼最小化版本
還是具體來看一下,Karpathy老師這次又煮出了一鍋什么樣的飯。

項目名minbpe已經(jīng)說明一切:BPE算法的最小、最干凈代碼版本。
BPE(字節(jié)對編碼)是隨著GPT-2而流行起來的標(biāo)記化算法。現(xiàn)在,包括GPT系列、Llama系列和Mistral在內(nèi),一眾大模型都用到了這一算法來訓(xùn)練分詞器。
BPE的主要優(yōu)勢在于:
高效:通過合并頻繁出現(xiàn)的字節(jié)對來逐步構(gòu)建詞匯表,可以有效地減少模型需要處理的詞匯量。靈活:可以將詞匯表外的單詞分解為已知子詞來進(jìn)行處理,有助于模型理解和生成未在訓(xùn)練中出現(xiàn)的單詞。
而在minbpe這個項目中,Karpathy提供了兩個Tokenizer(分詞器),它們都可以執(zhí)行分詞器的3個主要功能:
基于特定文本訓(xùn)練詞匯表和合并操作把文本編碼成token把token解碼為文本
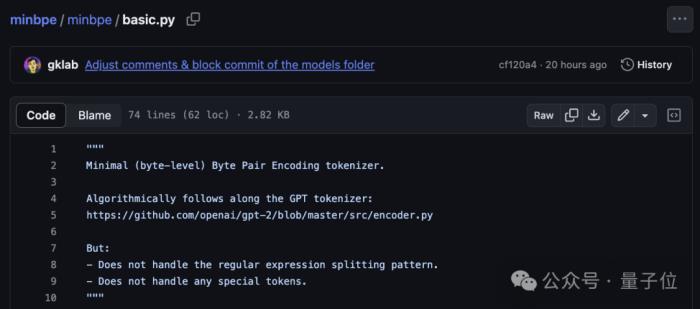
具體而言,在basic.py中,minbpe用74行Python代碼,完成了對直接在文本上運行的BPE算法的最簡單實現(xiàn)。
在regex.py中,minbpe實現(xiàn)的是一個正則表達(dá)式分詞器,該分詞器利用正則表達(dá)式進(jìn)一步拆分輸入的文本。
另外,在正則表達(dá)式分詞器的基礎(chǔ)之上,minbpe還在gpt4.py中提供了一個GPT4Tokenizer,可以準(zhǔn)確在線tiktoken庫中的GPT-4標(biāo)記化。
注:tiktoken是一種快速BPE分詞器。
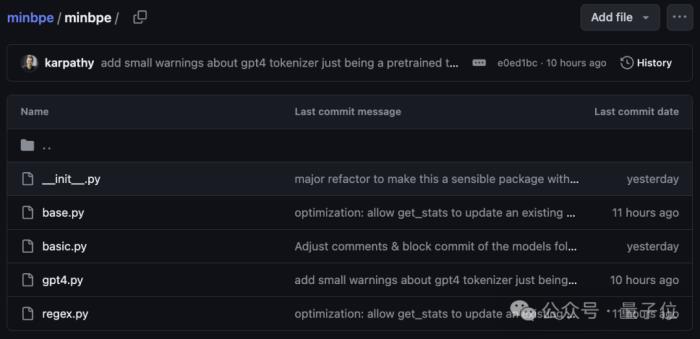
base.py則是一個基類,包含了訓(xùn)練、編碼和解碼的存根(stubs),提供了保存和加載的功能,并集成了一些常見的輔助工具函數(shù)。在實際應(yīng)用中,開發(fā)者應(yīng)該通過繼承這個基類來實現(xiàn)具體的分詞器功能。
Karpathy提到,他在霉霉的維基百科文本上嘗試訓(xùn)練了兩個主要的分詞器。train.py在他的M1 MacBook上運行時間大概為25秒。
如果你還有什么不清楚的地方,別擔(dān)心,卡老師已經(jīng)計劃要出視頻了:
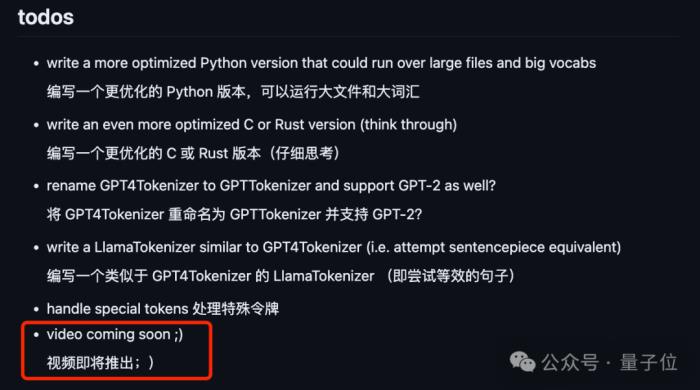
Karpathy出走OpenAI,許多猜測指向他的“下一篇章”是大語言模型系統(tǒng)(LLM OS)。
如今正式工作還未揭示,但看樣子Karpathy已經(jīng)拾起了“教學(xué)育人”的副業(yè),小伙伴們可以蹲起來了(doge)。
— 完 —
相關(guān)推薦



- 免責(zé)聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應(yīng)被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認(rèn)可。 交易和投資涉及高風(fēng)險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進(jìn)行充分的盡職調(diào)查。最終的決策應(yīng)該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負(fù)任何責(zé)任。
