

 新火種
2024-01-05
新火種
2024-01-05 


谷歌聯合高校研發通用模型ProteoGAN,可設計具有新功能的蛋白質
近年來,隨著醫學與生物技術的發展,蛋白質設計的重要性正在不斷提高。以目標功能為起點來進行新型蛋白質的設計,在發現新的藥物等方面有廣闊的應用前景。
然而,由于蛋白質的序列結構與功能之間存在超級復雜的機制,對它進行設計往往耗時耗力,需要龐大的投入。最近,機器學習在該領域的引入有效地快速解決了由于復雜性而難以達成的許多任務,例如,全新治療方法的開發、設計特定功能的催化劑等。
不過,目前機器學習在蛋白質設計領域的應用,往往只專注于某個特定應用,或只能進行某個蛋白質族系內的新型設計。目前,蛋白質設計領域還沒有一種通用模型,可以針對各種應用進行各個蛋白質族系中的新型蛋白質設計。

(來源:資料圖)
最近,來自蘇黎世聯邦理工學院生物系統機器學習與計算機生物系博士生蒂姆·庫切拉(Tim Kucera)、馬泰奧·托尼納利(Matteo Togninalli)博士以及來自谷歌研究院大腦團隊研究員萊蒂蒂亞·孟·帕帕杉索斯(Laetitia Meng-Papaxanthos)共同發布了 ProteoGAN 模型,為基于條件的蛋白質設計提供了一種通用生成模型。
相關論文以《用于按照層級功能進行從頭蛋白質設計的條件生成模型》(Conditional generative modeling for de novo protein design with hierarchical functions)為題發表在 Bioinformatics 上[1]。
該研究團隊開發 ProteoGAN 這一蛋白質設計通用模型的背景之一,還有最近在自然語言生成等深度學習的其他子領域中,通用模型的影響力越來越大,其表現比只專注于某個特性功能的模型更佳。
因此研究人員假設,如果是在蛋白質設計領域,同樣有模型有能力學習各種不同蛋白質族系的共同原理,這種模型所生成新型蛋白質的質量也會更貼近需求。而且,這種模型甚至可能創造蛋白質此前沒有的新的功能。
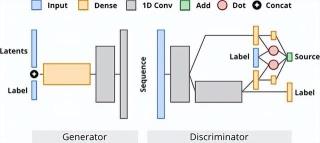
(來源:Bioinformatics)
對于生成類的模型來說,對其進行評估是一件難事,這主要是因為沒有可以將所生成的樣本進行參照對比的基本參照物。尤其是在蛋白質設計中,對于結果的驗證更加復雜,很難將所生成的數字結果真實地物理合成出來,以證實該新型蛋白質確實擁有設計需要的功能。在該研究中,研究人員選擇天然蛋白質作為參照物,將模型生成的蛋白質序列與之對比,來進行模型的評估。
在對模型評估的具體指標方面,研究人員也進行了深度的考量。在模型的分布相似度的評估中,團隊選擇了 MMD 方法進行評估;在模型的條件一致性的評估中,團隊選擇了平均倒數秩方法。為預測模型所生成的序列的多樣性,該團隊結合采用對偶性差距、特征維度上的平均熵以及序列之間的平均成對 RKHS 距離等多種方法。
基于所設置的對模型所設計生成的蛋白質進行評估與比較的方法,簡單來說,研究人員將 ProteoGAN 的模型架構設計為:在標簽集 GO 中給定一系列函數時,可以生成蛋白質序列的基于條件的 GAN 模型。其中,GO 可以對蛋白質功能進行描述的一系列標簽,而 GAN 模型則是一個已經在蛋白質序列設計方面被證實表現優異的模型。
在 ProteoGAN 的生成器和篩選器中,都含有卷積層和跳過連接。其中在生成器中,標簽與結構中的潛在噪聲向量輸入進行鏈接。在篩選器中,研究人員對各種不同的條件反射機制進行了探究。
為了解 ProteoGAN 模型的表現,研究人員將該模型在 UniProt 知識庫進行應用。在模型對該知識庫進行訓練之后,模型共生成了 157891 個新的蛋白質序列。其中,研究人員將功能標簽的總數限制成 50,而將每個標簽所相應的最少序列數設置為大約 5000。
此外,研究人員還將數據集進行了隨機拆分,將其分為訓練集、驗證集和測試集。其中,驗證集和測試集中的序列數量都大約占整個生成數據級的 10%,約有 15000 個序列。
在對 ProteoGAN 模型生成的蛋白質序列結果進行評估時,研究人員將其與此前更經典的概率語言模型和 HMM、CVAE、ProGen 等目前最新最前沿的蛋白質生成深度學習模型進行了對比。
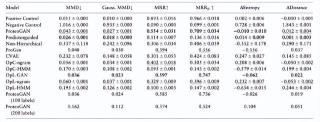
(來源:Bioinformatics)
為了解 ProteoGAN 的不同方面的影響,研究人員將模型進行不同方面的更改并與其進行比較。其中,所更改之后的不同“模型”分別有:每個標簽只有一個實例對應的 One-per-label GAN (OpL-GAN)、將 ProteoGAN 的調節機制去除的 Predictor-Guided、以及將標簽分層去除的非分層模型(Non-Hierarchical)。
通過使用之前設定的 MMD、MRR 等方法進行對比之后,研究人員發現,在分布相似性、條件一致性和多樣性等各個指標方面,ProteoGAN 模型的性能都優于其他對比模型。
參考資料:
1.Tim Kucera et al. Bioinformatics 38, 13, 3454–3461(2022).

相關推薦


- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
