

 新火種
2023-12-20
新火種
2023-12-20 

夸張!EMNLP投稿近5000篇,獎項出爐:北大、騰訊摘最佳長論文
本屆 EMNLP 大會在投稿人數(shù)上創(chuàng)了新高,整體接收率也較上屆略有提升。
EMNLP 是自然語言處理領(lǐng)域的頂級會議之一,EMNLP 2023 于 12 月 6 日 - 10 日在新加坡舉行。 因為今年 ChatGPT 的爆火帶動大模型、NLP 概念,EMNLP 2023 的投稿論文數(shù)量也達到近 5000 篇,甚至略高于 ACL 2023。
因為今年 ChatGPT 的爆火帶動大模型、NLP 概念,EMNLP 2023 的投稿論文數(shù)量也達到近 5000 篇,甚至略高于 ACL 2023。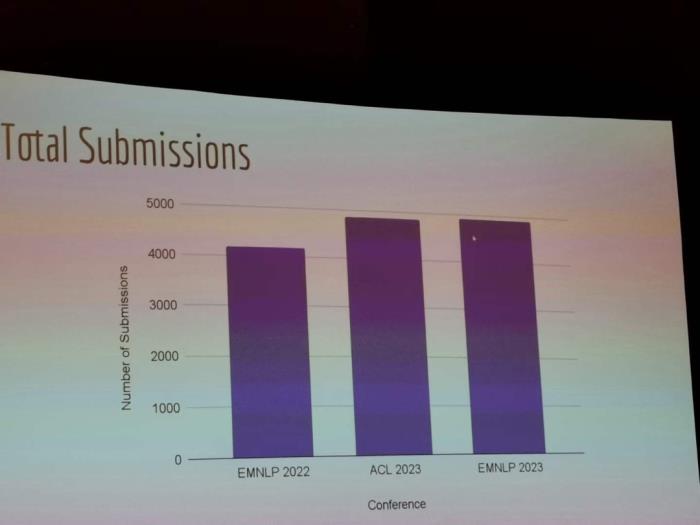 在接收率方面,長論文接收率為 23.3%,短論文接收率為 14%,整體接收率為 21.3%。這一數(shù)據(jù)相較 EMNLP 2022 的 20% 略有提升。
在接收率方面,長論文接收率為 23.3%,短論文接收率為 14%,整體接收率為 21.3%。這一數(shù)據(jù)相較 EMNLP 2022 的 20% 略有提升。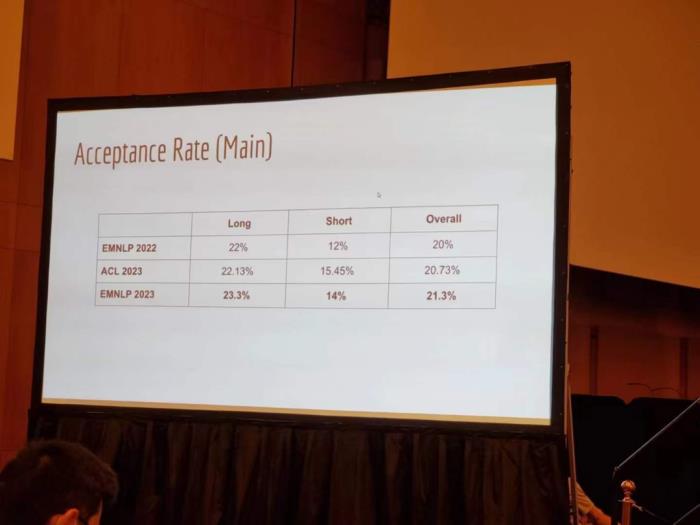 我們從這次 EMNLP 的 local chair 李海洲老師的一張 PPT 上,可以感受下這場大會的發(fā)展歷程。
我們從這次 EMNLP 的 local chair 李海洲老師的一張 PPT 上,可以感受下這場大會的發(fā)展歷程。 除了這些論文數(shù)據(jù)外,今年 EMNLP 的獲獎?wù)撐囊矀涫荜P(guān)注。
除了這些論文數(shù)據(jù)外,今年 EMNLP 的獲獎?wù)撐囊矀涫荜P(guān)注。 EMNLP 2023 頒發(fā)了最佳長論文、最佳短論文、最佳主題論文、最佳 Demo 論文和最佳行業(yè)論文各一篇,以及多篇不同賽道的杰出論文。同時,官方公布了 EMNLP 2024 將于 2024 年 11 月 12-16 日、佛羅里達州邁阿密市舉辦。
EMNLP 2023 頒發(fā)了最佳長論文、最佳短論文、最佳主題論文、最佳 Demo 論文和最佳行業(yè)論文各一篇,以及多篇不同賽道的杰出論文。同時,官方公布了 EMNLP 2024 將于 2024 年 11 月 12-16 日、佛羅里達州邁阿密市舉辦。 EMNLP 2023 最佳長論文論文標題:Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
EMNLP 2023 最佳長論文論文標題:Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning 機構(gòu):北京大學、騰訊 WeChat AI論文摘要:上下文學習為大型語言模型(LLM)提供了執(zhí)行不同任務(wù)的演示示例,成為了一種很有潛力的機器學習方法。然而,LLM 如何從所提供的上下文中學習的基礎(chǔ)機制仍在探索之中。因此,北京大學和騰訊 WeChat AI 的研究者通過信息流的視角探究上下文學習的工作機制。研究結(jié)果發(fā)現(xiàn),演示示例中的標簽詞發(fā)揮了錨點(anchor)的作用,具體表現(xiàn)為以下兩個方面:語義信息在淺計算層的處理過程中聚合為標簽詞表示;標簽詞中的整合信息作為 LLM 最終預測的參考。基于這些發(fā)現(xiàn),研究者提出一種提升上下文學習性能的錨點重加權(quán)方法、一種加速推理的演示壓縮技術(shù)、以及用于判斷 GPT2-XL 中上下文學習誤差的分析框架。
機構(gòu):北京大學、騰訊 WeChat AI論文摘要:上下文學習為大型語言模型(LLM)提供了執(zhí)行不同任務(wù)的演示示例,成為了一種很有潛力的機器學習方法。然而,LLM 如何從所提供的上下文中學習的基礎(chǔ)機制仍在探索之中。因此,北京大學和騰訊 WeChat AI 的研究者通過信息流的視角探究上下文學習的工作機制。研究結(jié)果發(fā)現(xiàn),演示示例中的標簽詞發(fā)揮了錨點(anchor)的作用,具體表現(xiàn)為以下兩個方面:語義信息在淺計算層的處理過程中聚合為標簽詞表示;標簽詞中的整合信息作為 LLM 最終預測的參考。基于這些發(fā)現(xiàn),研究者提出一種提升上下文學習性能的錨點重加權(quán)方法、一種加速推理的演示壓縮技術(shù)、以及用于判斷 GPT2-XL 中上下文學習誤差的分析框架。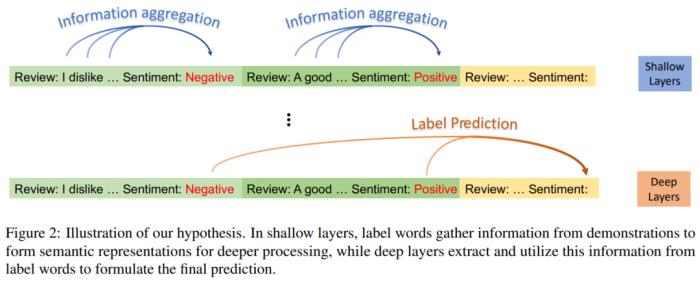 研究者提出的假設(shè)。在淺層,標簽詞從演示中收集信息,以形成語義表示來進行更深層處理;深層從標簽詞中提取并利用這些信息以形成最終預測。本文研究結(jié)果具有前景廣闊的應用,再次驗證了上下文學習的工作機制,為未來研究鋪平了道路。
研究者提出的假設(shè)。在淺層,標簽詞從演示中收集信息,以形成語義表示來進行更深層處理;深層從標簽詞中提取并利用這些信息以形成最終預測。本文研究結(jié)果具有前景廣闊的應用,再次驗證了上下文學習的工作機制,為未來研究鋪平了道路。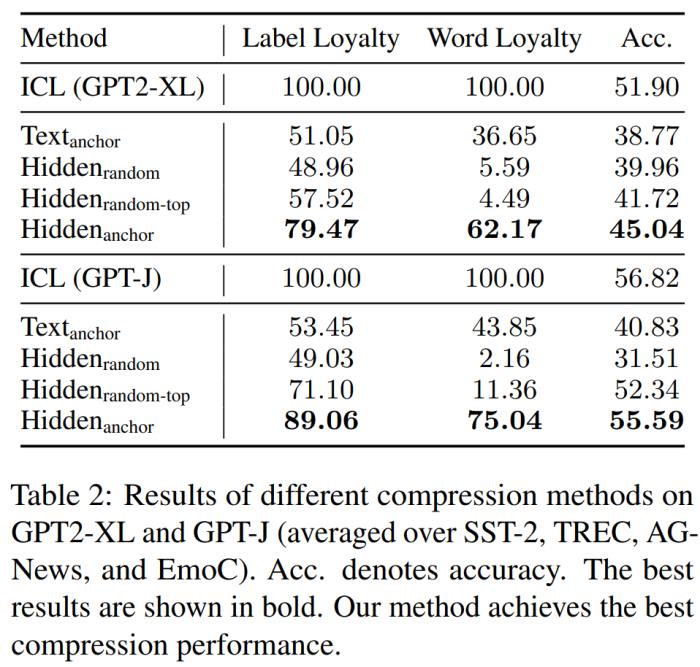 GPT2-XL 和 GPT-J 上不同壓縮方法的結(jié)果比較。EMNLP 2023 最佳短論文論文標題:Faster Minimum Bayes Risk Decoding with Confidence-based Pruning
GPT2-XL 和 GPT-J 上不同壓縮方法的結(jié)果比較。EMNLP 2023 最佳短論文論文標題:Faster Minimum Bayes Risk Decoding with Confidence-based Pruning 機構(gòu):劍橋大學論文摘要:最小貝葉斯風險(MBR)解碼是輸出在模型分布上對某個效用函數(shù)具有最高預期效用的假設(shè)。在條件語言生成問題,尤其是神經(jīng)機器翻譯中,無論是在人類評估還是自動評估中,它的準確性都超過了束搜索(beam search)。然而,基于采樣的標準 MBR 算法的計算成本遠高于束搜索,它需要大量采樣以及對效用函數(shù)的二次調(diào)用,這限制了它的適用性。本文介紹了一種 MBR 算法,它可以逐漸增加用于估計效用的樣本數(shù)量,同時剪枝根據(jù)引導抽樣獲得的置信估計不太可能具有最高效用的假設(shè)。與標準 MBR 相比,該方法所需的樣本更少,調(diào)用效用函數(shù)的次數(shù)也大幅減少,同時準確性方面相差無幾。
機構(gòu):劍橋大學論文摘要:最小貝葉斯風險(MBR)解碼是輸出在模型分布上對某個效用函數(shù)具有最高預期效用的假設(shè)。在條件語言生成問題,尤其是神經(jīng)機器翻譯中,無論是在人類評估還是自動評估中,它的準確性都超過了束搜索(beam search)。然而,基于采樣的標準 MBR 算法的計算成本遠高于束搜索,它需要大量采樣以及對效用函數(shù)的二次調(diào)用,這限制了它的適用性。本文介紹了一種 MBR 算法,它可以逐漸增加用于估計效用的樣本數(shù)量,同時剪枝根據(jù)引導抽樣獲得的置信估計不太可能具有最高效用的假設(shè)。與標準 MBR 相比,該方法所需的樣本更少,調(diào)用效用函數(shù)的次數(shù)也大幅減少,同時準確性方面相差無幾。 算法 2:基于置信的剪枝函數(shù)。研究者使用 chrF++ 和 COMET 作為效用 / 評估指標,在三種語言對的實驗中證明了該方法的有效性。
算法 2:基于置信的剪枝函數(shù)。研究者使用 chrF++ 和 COMET 作為效用 / 評估指標,在三種語言對的實驗中證明了該方法的有效性。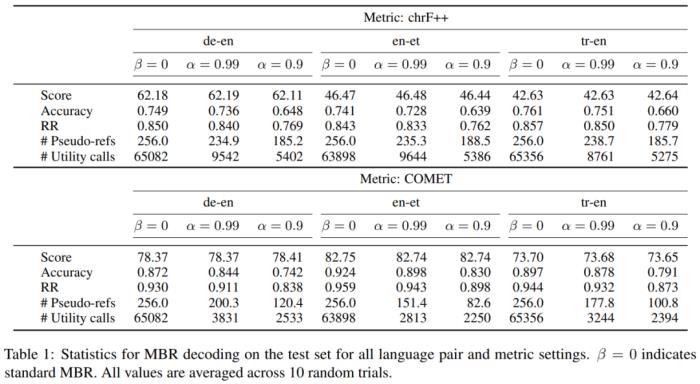 實驗結(jié)果。EMNLP 2023 最佳主題論文論文標題:Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs Through a Global Prompt Hacking Competition
實驗結(jié)果。EMNLP 2023 最佳主題論文論文標題:Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs Through a Global Prompt Hacking Competition 機構(gòu):馬里蘭大學、Mila、 Towards AI、斯坦福大學等論文摘要:大型語言模型 (LLM) 通常部署在用戶直接參與的交互式環(huán)境中,例如聊天機器人、寫作助手。這些部署很容易受到即時「注入」和「越獄」(統(tǒng)稱為即時黑客攻擊)的攻擊,其中模型被操縱以忽略其原始指令并遵循潛在的惡意指令。盡管人們廣泛認為這是一個重大的安全威脅,但關(guān)于即時黑客攻擊的定量研究仍然比較少。因此,該研究發(fā)起了全球即時黑客競賽,允許自由形式的人工輸入攻擊,并針對三個 SOTA LLM 提出了超過 60 萬條對抗性 prompt。實驗結(jié)果表明,當前的 LLM 確實可以通過即時黑客攻擊進行操縱。
機構(gòu):馬里蘭大學、Mila、 Towards AI、斯坦福大學等論文摘要:大型語言模型 (LLM) 通常部署在用戶直接參與的交互式環(huán)境中,例如聊天機器人、寫作助手。這些部署很容易受到即時「注入」和「越獄」(統(tǒng)稱為即時黑客攻擊)的攻擊,其中模型被操縱以忽略其原始指令并遵循潛在的惡意指令。盡管人們廣泛認為這是一個重大的安全威脅,但關(guān)于即時黑客攻擊的定量研究仍然比較少。因此,該研究發(fā)起了全球即時黑客競賽,允許自由形式的人工輸入攻擊,并針對三個 SOTA LLM 提出了超過 60 萬條對抗性 prompt。實驗結(jié)果表明,當前的 LLM 確實可以通過即時黑客攻擊進行操縱。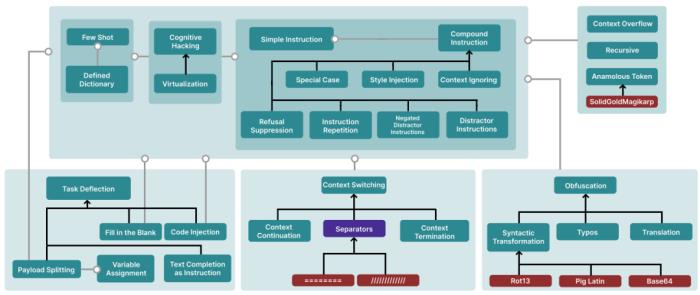 prompt 黑客技術(shù)分類。EMNLP 2023 最佳 Demo 論文論文標題:PaperMage: A Unified Toolkit for Processing, Representing, and Manipulating Visually-Rich Scientific Documents
prompt 黑客技術(shù)分類。EMNLP 2023 最佳 Demo 論文論文標題:PaperMage: A Unified Toolkit for Processing, Representing, and Manipulating Visually-Rich Scientific Documents 機構(gòu):艾倫人工智能研究院、MIT、加州大學伯克利分校、華盛頓大學、美國西北大學論文摘要:科研領(lǐng)域的學術(shù)文獻往往是復雜的、理論的,并且大部分是 PDF 格式的文檔,查閱文獻需要花費大量時間。為了解決該問題,該論文提出一個開源的 Python 工具包 ——papermage,用于分析和處理視覺效果豐富、結(jié)構(gòu)化的科學文檔。
機構(gòu):艾倫人工智能研究院、MIT、加州大學伯克利分校、華盛頓大學、美國西北大學論文摘要:科研領(lǐng)域的學術(shù)文獻往往是復雜的、理論的,并且大部分是 PDF 格式的文檔,查閱文獻需要花費大量時間。為了解決該問題,該論文提出一個開源的 Python 工具包 ——papermage,用于分析和處理視覺效果豐富、結(jié)構(gòu)化的科學文檔。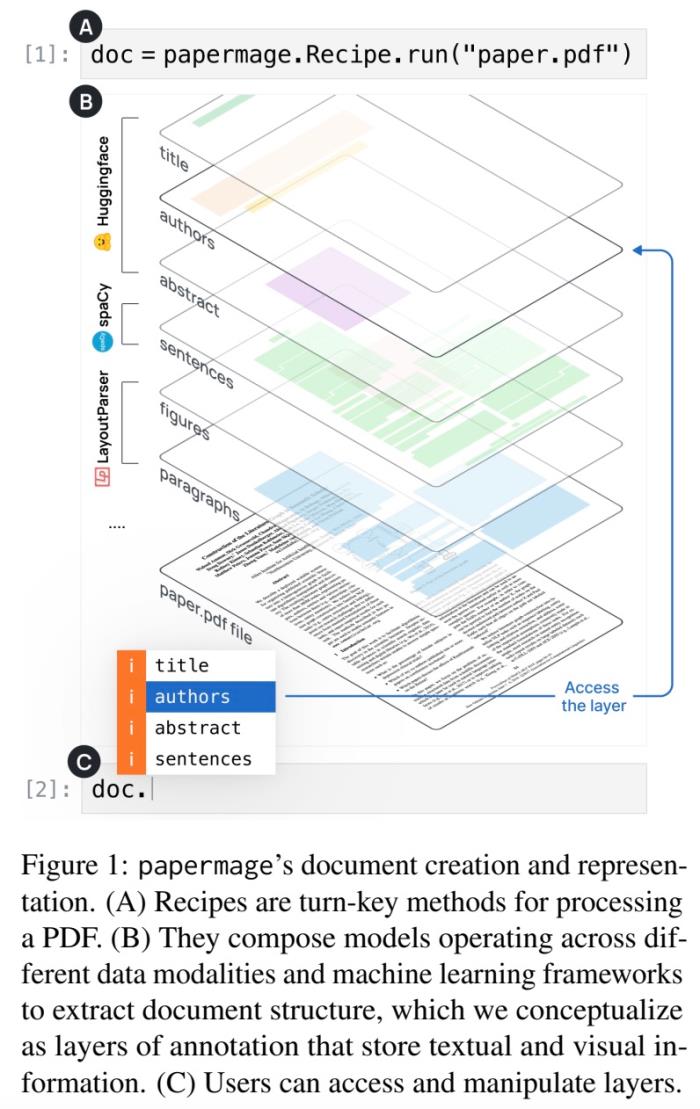 papermage 通過將不同的 SOTA NLP 和 CV 模型集成到一個統(tǒng)一的框架中,為科學文獻提供了清晰直觀的抽象,并為常見的科學文檔提供處理用例。在學術(shù)文獻搜索引擎 Semantic Scholar 的支持下,papermage 已經(jīng)可以處理多個 AI 應用研究原型的科學文獻。
papermage 通過將不同的 SOTA NLP 和 CV 模型集成到一個統(tǒng)一的框架中,為科學文獻提供了清晰直觀的抽象,并為常見的科學文檔提供處理用例。在學術(shù)文獻搜索引擎 Semantic Scholar 的支持下,papermage 已經(jīng)可以處理多個 AI 應用研究原型的科學文獻。 EMNLP 2023 最佳行業(yè)論文論文標題:Personalized Dense Retrieval on Global Index for Voice-enabled Conversational Systems
EMNLP 2023 最佳行業(yè)論文論文標題:Personalized Dense Retrieval on Global Index for Voice-enabled Conversational Systems 機構(gòu):亞馬遜 Alexa AI 研究團隊論文摘要:語音控制的人工智能對話系統(tǒng)容易受語音變化噪音的干擾,并且難以解決含糊不清的實體問題。通常情況下,部署個性化實體解析(ER)、查詢重寫(QR)從這些錯誤模式中恢復。以往的工作通過限制檢索空間至用戶與設(shè)備的歷史互動建立的個性化索引來實現(xiàn)個性化。雖然這種限制性檢索能夠?qū)崿F(xiàn)高精度,但預測僅限于用戶近期歷史中的實體,因此無法廣泛覆蓋未來的請求。此外,為大量用戶維護單個索引需要既耗費內(nèi)存又難以擴展。本文提出了一種個性化實體檢索系統(tǒng),它不局限于個性化索引并對語音噪聲和歧義具有穩(wěn)健性。研究者將用戶的收聽偏好嵌入到檢索中使用的上下文查詢嵌入中。他們展示了提出模型糾正多種錯誤模式的能力,并在實體檢索任務(wù)上比基線提高了 91%。他們還優(yōu)化了端到端方法,使其在保持性能提升的同時,也符合在線延遲的限制。
機構(gòu):亞馬遜 Alexa AI 研究團隊論文摘要:語音控制的人工智能對話系統(tǒng)容易受語音變化噪音的干擾,并且難以解決含糊不清的實體問題。通常情況下,部署個性化實體解析(ER)、查詢重寫(QR)從這些錯誤模式中恢復。以往的工作通過限制檢索空間至用戶與設(shè)備的歷史互動建立的個性化索引來實現(xiàn)個性化。雖然這種限制性檢索能夠?qū)崿F(xiàn)高精度,但預測僅限于用戶近期歷史中的實體,因此無法廣泛覆蓋未來的請求。此外,為大量用戶維護單個索引需要既耗費內(nèi)存又難以擴展。本文提出了一種個性化實體檢索系統(tǒng),它不局限于個性化索引并對語音噪聲和歧義具有穩(wěn)健性。研究者將用戶的收聽偏好嵌入到檢索中使用的上下文查詢嵌入中。他們展示了提出模型糾正多種錯誤模式的能力,并在實體檢索任務(wù)上比基線提高了 91%。他們還優(yōu)化了端到端方法,使其在保持性能提升的同時,也符合在線延遲的限制。 其他杰出論文獎除了以上獎項,EMNLP 2023 官方還頒發(fā)了一些賽道的杰出論文獎,如賓夕法尼亞州立大學研究者的論文《The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis》獲得了情感分析、文體分析和論據(jù)挖掘賽道的杰出論文獎。
其他杰出論文獎除了以上獎項,EMNLP 2023 官方還頒發(fā)了一些賽道的杰出論文獎,如賓夕法尼亞州立大學研究者的論文《The Sentiment Problem: A Critical Survey towards Deconstructing Sentiment Analysis》獲得了情感分析、文體分析和論據(jù)挖掘賽道的杰出論文獎。 圖源:twitter
圖源:twitter
蘇黎世聯(lián)邦理工學院(ETH)博士后研究員 Ethan Gotlieb Wilcox 參與的兩篇論文獲得了杰出論文獎。 圖源:twitter
圖源:twitter
蒂爾堡大學、阿姆斯特丹大學研究者的論文《Homophone Disambiguation Reveals Patterns of Context Mixing in Speech Transformers》也獲得了杰出論文獎。 圖源:twitter
圖源:twitter
相關(guān)推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內(nèi)容相關(guān)的任何行動之前,請務(wù)必進行充分的盡職調(diào)查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產(chǎn)生的任何金錢損失負任何責任。
