

 新火種
2023-12-11
新火種
2023-12-11 


后期狂喜!用照片絲滑替換視頻主角,動作幅度再大也OK
后期狂喜了家人們~
現在,只需少量圖片就能定制化替換視頻主角,效果還是如此的絲滑!
且看這個叫做“VideoSwap”的新視頻編輯模型——
小貓一鍵變小狗,基操~

如果原物體本身扭動幅度大一些?也完全沒問題:

細看倆者之間的運動軌跡,給你保持得是一毛一樣:

再如果,替換前后的物體形狀差別較大呢?
例如車身較高的SUV換更長的超跑,大郵輪換小白船。
吶,也是一整個完美替換,基本看不出任何破綻:


對比谷歌今年2月發的同類視頻替換模型Dreamix:

不得不說,現在這技術進步真是肉眼可見啊~
那么,它是如何做到的呢?
方法也很有意思。
只需幾個語義點,拽一拽就OK不管是風格轉換還是主題/背景轉換,這種視頻編輯任務的主要挑戰都是如何從源視頻中提取運動軌跡傳輸到新視頻、覆蓋到新元素上,同時確保時間一致性。
此前的模型(原理包括編碼源運動、使用注意力圖、光流等)大多數顧此失彼,要么在時間一致性上做的不好,要么會嚴格限制形狀變化。
在此,VideoSwap提出使用少量語義點來描述物體的運動軌跡。
如下圖所示,飛機的運動軌跡就可以通過機翼、機頭和機尾的4個點來表示。

而在替換成直升機時,我們可以刪除兩個點,在只保留機頭和機尾來對齊運動軌跡的同時,免除形狀約束,讓體型不一樣的直升機得以替換。
除了刪除語義點,它還能拖拽。
像開頭展示的這個SUV變超跑,由于車身變長了,我們不對語義點進行處理,超跑就變形了:

對此,我們只要將SUV車頭和車尾的幾個點稍加挪動就OK:

下面這個天鵝的替換視頻也是經過了語義點拖拽:

那么具體來說,VideoSwap是如何操作的呢?
從它的pipeline來看,簡單來說,VideoSwap也是基于擴散模型(潛擴散)。
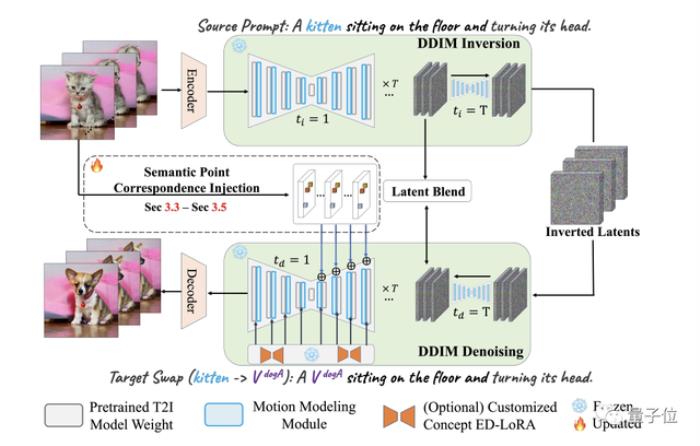
它首先用VAE編碼器對源視頻進行編碼,獲得潛空間表示;然后用DDIM反演將它變換回有噪聲的表示。
接著用文本提示中的源主題(例如貓)替換目標主題(狗),并使用DDIM scheduler進行去噪。
在這個去噪過程中,就可以引入語義點對應關系來引導目標主題遵循原來的運動軌跡進行生成了。
最后,為了保留背景,作者在此還采用了一個潛混合的概念。
此外,他們還通過將視頻運動層集成圖像擴散模型中,來確保結果的時間一致性。
這里的關鍵點之一就是VideoSwap中的語義點提取和注冊(register)pipeline。(“注冊”是指把語義點安插到源視頻)
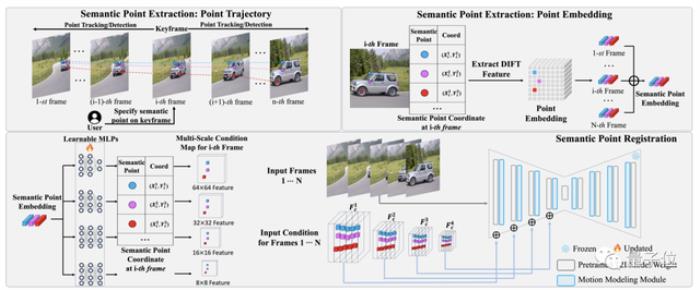
首先它需要我們在關鍵幀中標出關鍵語義點,然后再從視頻中提取所標語義點對應軌跡的embedding。
接下來在語義點匹配中,embedding由多個2層可學習MLP投射,并根據其坐標位置放置到空特征中,然后逐元素添加到擴散模型中作為運動引導。
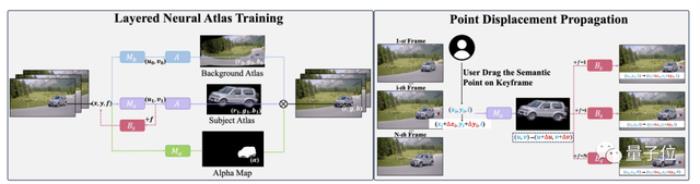
至于用戶拖動語義點后還可以讓視頻保持很好的一致性,這里用到的技術則是基于分層神經圖譜(LNA)的點位移傳播。
通過被訓練過的LNA,用戶拖動產生的位移就能通過它的規范空間一致地傳播到每一幀之中。
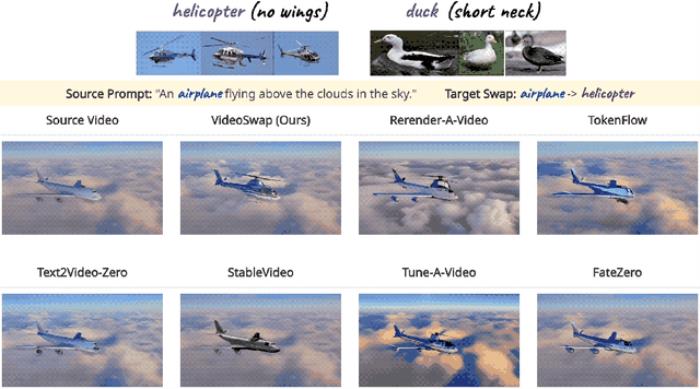
最后,作者表示:基于以上這些方法,VideoSwap通過大量測試,最終取得了SOTA成績,成為目前最好的視頻變換模型。
這是它和一些主流方法的效果對比:
目標是把飛機變直升機。
可以看到,除了VideoSwap,絕大多數方法都只在機頭部分往直升機的方向靠攏,不細看都發現不了,并且有的還伴隨著明顯的閃爍和偽影。
作者介紹
VideoSwap由新加坡國立大學和Meta合作完成。

一作Yuchao Gu為新加坡國立大學博士生,此前碩士畢業于南開大學,他的研究方向正是AIGC,尤其為視頻生成為主。
他同時也是Meta GenAI方向的實習生。
通訊作者為新加坡國立大學助理教授Mike Z. Shou,他此前是Facebook AI的研究員。

相關推薦

- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
