

 新火種
2023-11-30
新火種
2023-11-30 


秒出圖!StabilityAI推出開源文生圖大模型SDXLTurbo

圖片來源:由無界 AI生成
圖生文大模型技術再次卷起來,現在開始卷實時出圖了。
11 月 28 日,開源大模型公司 Stability AI 正式發布了一種新的開源文生圖模型 SDXL Turbo,并已發布在了 Hugging Face 平臺上公開可用。用戶輸入提示詞之后,該工具能夠幾乎實時生成圖像。就目前的實測結果顯示,圖像生成質量有時候有些不足,但這種生成速度絕對顛覆目前市場上的所有產品,包括 Midjourney,DALL-E3等,帶來更多想象空間。
SDXL Turbo 采用了被稱為對抗擴散蒸餾 (Adversarial Diffusion Distillation,ADD) 的新技術,該技術使模型能夠一步合成圖像輸出并生成實時文本到圖像輸出,同時保持高采樣保真度。該技術的論文已經公開發布。不過,SDXL Turbo 目前還未開放商業使用。
研究論文地址:https://stability.ai/research/adversarial-diffusion-distillation
體驗鏈接:http://clipdrop.co/stable-diffusion-turbo
Hugging Face 下載鏈接:https://huggingface.co/stabilityai/sdxl-turbo
擴散模型取得新進展
SDXL Turbo 是 Stability AI 在擴散模型技術方面取得的新進展,它在 SDXL 1.0 的基礎上進行迭代,并為文本到圖像模型實現了一種新的蒸餾技術:對抗擴散蒸餾 (Adversarial Diffusion Distillation,ADD) 。 通過整合 ADD,SDXL Turbo 獲得了與 GAN(生成對抗網絡)共有的許多優勢,例如單步圖像輸出,同時避免了其他蒸餾方法中常見的偽影或模糊。
什么是 ADD
ADD 是一種新的模型訓練方法,只需 1-4 個步驟即可有效地對大規模基礎圖像擴散模型進行采樣,同時保持高圖像質量。 通過使用積分蒸餾來利用大規模現成的圖像擴散模型作為一種教師信號,并結合對抗性損失,以確保即使在一兩個采樣步驟的低步驟狀態下也能確保高圖像保真度。 分析結果顯示,這種方法明顯優于現有的幾步方法(GAN,潛在一致性模型),并且僅用四個步驟就達到了最先進的擴散模型(SDXL)的性能。 ADD 是第一種利用基礎模型實現單步實時圖像合成的方法。
與其他擴散模型相比的性能優勢
擴散模型在合成和編輯高分辨率圖像和視頻方面取得了顯著的性能,但其迭代性質阻礙了實時應用。
潛在擴散模型試圖通過在計算上更可行的潛在空間中表示圖像來解決這個問題,但它們仍然依賴于具有數十億參數的大型模型的迭代應用。
除了利用更快的采樣器進行擴散模型之外,關于模型蒸餾的研究也越來越多,例如漸進蒸餾和引導蒸餾。 這些方法將迭代采樣步驟的數量減少到 4-8 個,但可能會顯著降低原始性能。 此外,它們需要迭代訓練過程。 一致性模型通過在 ODE 軌跡上實施一致性正則化來解決后一個問題,并在少樣本設置中展示了基于像素的模型的強大性能。 LCM 專注于提取潛在擴散模型,并在 4 個采樣步驟中實現令人印象深刻的性能。 最近,LCM-LoRA 引入了低秩自適應訓練,用于高效學習 LCM 模塊,可以插入 SD 和 SDXL 的不同檢查點。 InstaFlow 建議使用整流流來促進更好的蒸餾過程。
所有這些方法都有共同的缺陷:在四個步驟中合成的樣本通常看起來模糊并表現出明顯的偽影。 如果采樣步驟較少,這個問題就會進一步放大。 GAN 也可以被訓練為用于文本到圖像合成的獨立單步模型。 它們的采樣速度令人印象深刻,但性能落后于基于擴散的模型。在某種程度上,這可以歸因于穩定訓練對抗目標所需的精細平衡的 GAN 特定架構。 在不破壞平衡的情況下擴展這些模型并集成神經網絡架構的進步是眾所周知的挑戰。
此外,當前最先進的文本到圖像 GAN 沒有像無分類器指導這樣的方法,這對于大規模的 DM 至關重要。
方法
我們的目標是以盡可能少的采樣步驟生成高保真樣本,同時匹配最先進模型的質量。 對抗性目標自然有助于快速生成,因為它訓練一個模型,該模型在單個前向步驟中輸出圖像流形上的樣本。 然而,嘗試將 GAN 擴展到大型數據集時發現,不僅要依賴判別器,還要采用預訓練的分類器或 CLIP 網絡來改善文本對齊。 正如中所述,過度利用判別網絡會引入偽影,并且圖像質量會受到影響。 相反,我們通過分數蒸餾目標利用預訓練擴散模型的梯度來提高文本對齊和樣本質量。 此外,我們不是從頭開始訓練,而是使用預訓練的擴散模型權重來初始化模型; 眾所周知,預訓練生成器網絡可以顯著改善對抗性損失的訓練。 最后,我們采用了標準擴散模型框架,而不是利用用于 GAN 訓練的純解碼器架構。 這種設置自然可以實現迭代細化。

采樣步驟的定性效果。 我們展示了使用 1、2 和 4 步對 ADD-XL 進行采樣時的定性示例。 單步采樣通常已經是高質量了,但增加步驟數可以進一步提高一致性(例如第二個提示,第一列的效果,明顯 4 步要比 1 步強很多)和對細節的關注(例如第二個提示,第二列的效果,同樣 4步更強)。 每一列中的種子是恒定的,我們看到總體布局在采樣步驟中得到保留,允許快速探索輸出,同時保留細化的可能性。
為了選擇 SDXL Turbo,研究團隊通過使用相同的提示詞生成輸出來比較多個不同的模型變體(StyleGAN-T++、OpenMUSE、IF-XL、SDXL 和 LCM-XL)。 然后,人類評估者會隨機看到兩個輸出,并被要求選擇最符合提示方向的輸出。 接下來,用相同的方法完成圖像質量的附加測試。 在這些盲測中,SDXL Turbo 能夠以一步擊敗 LCM-XL 的 4 步配置,并且僅用 4 步擊敗 SDXL 的 50 步配置。 通過這些結果,我們可以看到 SDXL Turbo 的性能優于最先進的多步模型,其計算要求顯著降低,而無需犧牲圖像質量。
為了選擇 SDXL Turbo,我們通過使用相同的提示生成輸出來比較多個不同的模型變體(StyleGAN-T++、OpenMUSE、IF-XL、SDXL 和 LCM-XL)。 然后,人類評估者會隨機看到兩個輸出,并被要求選擇最符合提示方向的輸出。 接下來,用相同的方法完成圖像質量的附加測試。 在這些盲測中,SDXL Turbo 能夠以一步擊敗 LCM-XL 的 4 步配置,并且僅用 4 步擊敗 SDXL 的 50 步配置。 通過這些結果,我們可以看到 SDXL Turbo 的性能優于最先進的多步模型,其計算要求顯著降低,而無需犧牲圖像質量。
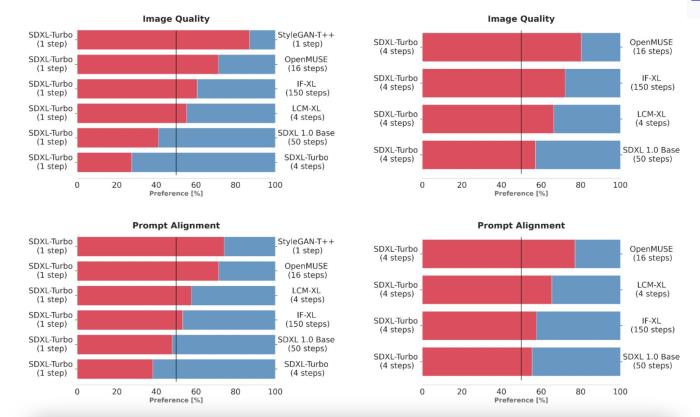
用戶偏好研究(單步)。 將 ADD-XL(1 步)的性能與既定基線進行比較。 在人類對圖像質量和即時對齊的偏好方面,ADD-XL 模型優于除 SDXL 之外的所有模型。 使用更多的采樣步驟進一步改進了我們的模型(底行)。
接近實時的速度
社區用戶已經開始上手體驗 SDXL Turbo,效果讓人驚嘆。有用戶使用消費級 4060TI 顯卡運行該大模型,能夠以 0.3 秒/張的速度生成 512x512的圖像。這種幾十倍的速度提升,正在給創作者帶來了新的想象空間。
鏈接:https://twitter.com/hylarucoder/status/1729670368409903420
SDXL Turbo 速度之快甚至能夠讓用戶邊輸入提示詞邊生成圖像。用戶還擴展了功能,可以增加參考圖來生成圖片。
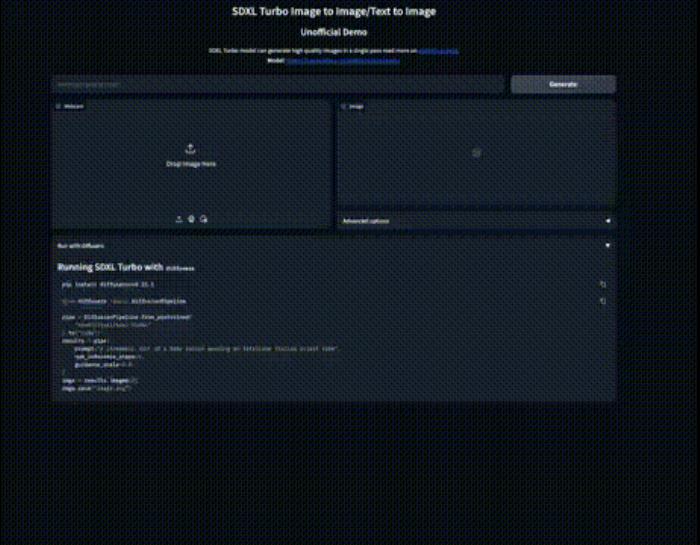
用戶設計的體驗地址:https://huggingface.co/spaces/diffusers/unofficial-SDXL-Turbo-i2i-t2i
此外,SDXL Turbo 還顯著提高了推理速度。 通過使用 A100 AI芯片,SDXL Turbo 可以在 207 毫秒內生成 512x512 圖像(即時編碼 + 單個去噪步驟 + 解碼,fp16),其中單個 UNet 前向評估占用了 67 毫秒。
Tags:
相關推薦



- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
