

 新火種
2023-11-27
新火種
2023-11-27 


OpenAI神秘Q*項目解密!誕生30+年Q學習算法引全球網友終極猜想
編輯:桃子【新智元導讀】OpenAI神秘Q*項目剛被曝出一天,就已經引發了各種猜想。一時間,「Q-learning」成為許多人的關注焦點。剛剛過去的一天,OpenAI被爆出驚天內幕:一個名為Q*(Q-Star)的項目已現AGI雛形。 對于這個神秘Q*,許多網友決定挖墓,將研究重點放在了「Q學習」(Q-learning)身上。
對于這個神秘Q*,許多網友決定挖墓,將研究重點放在了「Q學習」(Q-learning)身上。 突然間,這項來自1992年的技術成為了熱點。
突然間,這項來自1992年的技術成為了熱點。 谷歌工程師、Keras發明者Fran?ois Chollet表示,人類對即將到來的AGI的第一次恐慌,是在2013年左右,DeepMind的Atari Q-learning。第二次是在2016年左右爆發的深度強化學習Deep RL(部分由AlphaGo觸發)。2016年末,很多人都相信Deep RL將在5年內實現AGI......
谷歌工程師、Keras發明者Fran?ois Chollet表示,人類對即將到來的AGI的第一次恐慌,是在2013年左右,DeepMind的Atari Q-learning。第二次是在2016年左右爆發的深度強化學習Deep RL(部分由AlphaGo觸發)。2016年末,很多人都相信Deep RL將在5年內實現AGI...... 那么,Q-learning真的是OpenAI實現AGI的殺手锏嗎?
那么,Q-learning真的是OpenAI實現AGI的殺手锏嗎?
 Q-learning是人工智能領域,特別是在強化學習領域的基礎概念。它是一種無模型的強化學習算法,旨在學習特定狀態下某個動作的價值。Q-learning的最終目標是找到最佳策略,即在每個狀態下采取最佳動作,以最大化隨時間累積的獎勵。理解Q-learning基本概念:Q-learning基于Q函數的概念,也稱為「狀態-動作」價值函數。這個函數接受兩個輸入:一個狀態和一個動作。它返回從該狀態開始,采取該動作,然后遵循最佳策略所預期的總獎勵。Q-table:在簡單場景中,Q學習維護一個表(稱為Q-table),每行代表一個狀態,每列代表一個動作。表中的條目是Q值,隨著代理通過探索和利用學習而更新。更新規則:Q-learning的核心是更新規則,通常表示為:
Q-learning是人工智能領域,特別是在強化學習領域的基礎概念。它是一種無模型的強化學習算法,旨在學習特定狀態下某個動作的價值。Q-learning的最終目標是找到最佳策略,即在每個狀態下采取最佳動作,以最大化隨時間累積的獎勵。理解Q-learning基本概念:Q-learning基于Q函數的概念,也稱為「狀態-動作」價值函數。這個函數接受兩個輸入:一個狀態和一個動作。它返回從該狀態開始,采取該動作,然后遵循最佳策略所預期的總獎勵。Q-table:在簡單場景中,Q學習維護一個表(稱為Q-table),每行代表一個狀態,每列代表一個動作。表中的條目是Q值,隨著代理通過探索和利用學習而更新。更新規則:Q-learning的核心是更新規則,通常表示為: 這里,\( \alpha \) 是學習率,\( \gamma \) 是折扣因子,\( r \) 是獎勵,\( s \) 是當前狀態,\( a \) 是當前動作,\( s' \) 是新狀態。探索與利用:Q-learning的一個關鍵方面是平衡探索(嘗試新事物)和利用(使用已知信息)。這通常通過諸如ε-貪婪策略來管理,其中代理以ε的概率隨機探索,以1-ε的概率利用最佳已知動作。舉個例子,小迷宮里的一只老鼠,目標是吃掉右下角的一大堆奶酪,避開毒藥。如果我們吃了毒藥,吃了一大堆奶酪,或者我們花了超過五步,game over。
這里,\( \alpha \) 是學習率,\( \gamma \) 是折扣因子,\( r \) 是獎勵,\( s \) 是當前狀態,\( a \) 是當前動作,\( s' \) 是新狀態。探索與利用:Q-learning的一個關鍵方面是平衡探索(嘗試新事物)和利用(使用已知信息)。這通常通過諸如ε-貪婪策略來管理,其中代理以ε的概率隨機探索,以1-ε的概率利用最佳已知動作。舉個例子,小迷宮里的一只老鼠,目標是吃掉右下角的一大堆奶酪,避開毒藥。如果我們吃了毒藥,吃了一大堆奶酪,或者我們花了超過五步,game over。
 為了訓練智能體有一個最優的策略,就需要使用Q-Learning算法。Q-learning與AGI的道路AGI指的是人工智能系統理解、學習并將其智能應用于各種問題的能力,類似于人類智能。雖然Q-learning在特定領域很有力量,但它代表著通向AGI的一步,但要克服幾個挑戰:
為了訓練智能體有一個最優的策略,就需要使用Q-Learning算法。Q-learning與AGI的道路AGI指的是人工智能系統理解、學習并將其智能應用于各種問題的能力,類似于人類智能。雖然Q-learning在特定領域很有力量,但它代表著通向AGI的一步,但要克服幾個挑戰: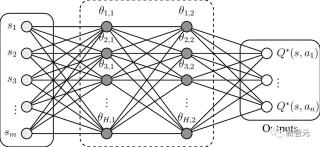 進展和未來方向:
進展和未來方向: 一個自然的猜測是,它是基于AlphaGo的蒙特卡羅樹搜索(Monte Carlo Tree)token軌跡。這似乎是很自然的下一步,之前像AlphaCode這樣的論文表明,即使在大型語言模型中進行非常幼稚的暴力采樣,也可以在競爭性編程中獲得巨大的改進。下一個合乎邏輯的步驟是以更有原則的方式搜索token樹。這在編碼和數學等環境中尤為合理,因為在這些環境中,有一種簡單的方法可以確定正確性。事實上,Q*似乎就是為了解決數學問題。不過,Silas Alberti稱,根據問題的不同,計算量也不同。現在,我們只能對模型采樣一次。如果Q*真的如上所述是樹狀搜索,那么它就可以在一道很難的奧數題上花費10倍、100倍甚至1000倍的計算量。同樣,也有網友表示,Q*是Q-learning和A*算法的結合。
一個自然的猜測是,它是基于AlphaGo的蒙特卡羅樹搜索(Monte Carlo Tree)token軌跡。這似乎是很自然的下一步,之前像AlphaCode這樣的論文表明,即使在大型語言模型中進行非常幼稚的暴力采樣,也可以在競爭性編程中獲得巨大的改進。下一個合乎邏輯的步驟是以更有原則的方式搜索token樹。這在編碼和數學等環境中尤為合理,因為在這些環境中,有一種簡單的方法可以確定正確性。事實上,Q*似乎就是為了解決數學問題。不過,Silas Alberti稱,根據問題的不同,計算量也不同。現在,我們只能對模型采樣一次。如果Q*真的如上所述是樹狀搜索,那么它就可以在一道很難的奧數題上花費10倍、100倍甚至1000倍的計算量。同樣,也有網友表示,Q*是Q-learning和A*算法的結合。
 很多人聲稱Q-learning或RLAIF并不新鮮。這些技術可能并不新鮮,但將它們結合起來構建一個產生顯著結果的工作實現是新穎的!偉大的工程+科學=魔法!
很多人聲稱Q-learning或RLAIF并不新鮮。這些技術可能并不新鮮,但將它們結合起來構建一個產生顯著結果的工作實現是新穎的!偉大的工程+科學=魔法! 確實,AlphaZero當年的視頻值得再重溫一遍。
確實,AlphaZero當年的視頻值得再重溫一遍。
對于這個神秘Q*,許多網友決定挖墓,將研究重點放在了「Q學習」(Q-learning)身上。突然間,這項來自1992年的技術成為了熱點。谷歌工程師、Keras發明者Fran?ois Chollet表示,人類對即將到來的AGI的第一次恐慌,是在2013年左右,DeepMind的Atari Q-learning。第二次是在2016年左右爆發的深度強化學習Deep RL(部分由AlphaGo觸發)。2016年末,很多人都相信Deep RL將在5年內實現AGI......那么,Q-learning真的是OpenAI實現AGI的殺手锏嗎?Q-learning是什么?
接下來,讓我們深入了解Q-learning以及它與RLHF的關系。Q-learning是人工智能領域,特別是在強化學習領域的基礎概念。它是一種無模型的強化學習算法,旨在學習特定狀態下某個動作的價值。Q-learning的最終目標是找到最佳策略,即在每個狀態下采取最佳動作,以最大化隨時間累積的獎勵。理解Q-learning基本概念:Q-learning基于Q函數的概念,也稱為「狀態-動作」價值函數。這個函數接受兩個輸入:一個狀態和一個動作。它返回從該狀態開始,采取該動作,然后遵循最佳策略所預期的總獎勵。Q-table:在簡單場景中,Q學習維護一個表(稱為Q-table),每行代表一個狀態,每列代表一個動作。表中的條目是Q值,隨著代理通過探索和利用學習而更新。更新規則:Q-learning的核心是更新規則,通常表示為:這里,\( \alpha \) 是學習率,\( \gamma \) 是折扣因子,\( r \) 是獎勵,\( s \) 是當前狀態,\( a \) 是當前動作,\( s' \) 是新狀態。探索與利用:Q-learning的一個關鍵方面是平衡探索(嘗試新事物)和利用(使用已知信息)。這通常通過諸如ε-貪婪策略來管理,其中代理以ε的概率隨機探索,以1-ε的概率利用最佳已知動作。舉個例子,小迷宮里的一只老鼠,目標是吃掉右下角的一大堆奶酪,避開毒藥。如果我們吃了毒藥,吃了一大堆奶酪,或者我們花了超過五步,game over。獎勵函數是這樣的:
- 沒有吃到奶酪:+0
- 吃到一塊奶酪:+1
- 吃到一大堆奶酪:+10
- 吃到毒藥:-10
- 超過5步:+0為了訓練智能體有一個最優的策略,就需要使用Q-Learning算法。Q-learning與AGI的道路AGI指的是人工智能系統理解、學習并將其智能應用于各種問題的能力,類似于人類智能。雖然Q-learning在特定領域很有力量,但它代表著通向AGI的一步,但要克服幾個挑戰:- 可擴展性:
傳統的Q-learning難以應對大型狀態-動作空間,使其不適用于AGI需要處理的實際問題。- 泛化:
AGI需要能夠從學習的經驗中泛化到新的、未見過的場景。Q-learning通常需要針對每個特定場景進行明確的訓練。- 適應性:
AGI必須能夠動態適應變化的環境。Q-learning算法通常需要一個靜態環境,其中規則不隨時間變化。- 多技能整合:
AGI意味著各種認知技能,如推理、解決問題和學習的整合。Q-learning主要側重于學習方面,將其與其他認知功能整合是一個正在進行的研究領域。進展和未來方向:- 深度Q網絡(DQN):
將Q-learning與深度神經網絡結合,DQN可以處理高維狀態空間,使其更適合復雜任務。- 遷移學習:
使Q-learning模型在一個領域受過訓練后能夠將其知識應用于不同但相關的領域的技術,可能是通向AGI所需泛化的一步。- 元學習:
在Q-learning框架中實現元學習可以使人工智能學會如何學習,動態地調整其學習策略,這對于AGI至關重要。Q-learning在人工智能領域,尤其是在強化學習中,代表了一種重要的方法論。毫不奇怪,OpenAI正在使用Q-learning RLHF來嘗試實現神秘的AGI。A*算法+Q-learning
一位斯坦福博士Silas Alberti表示,OpenAI的Q*可能與Q-learning有關,表示貝爾曼方程的最優解。又或者,Q*指的是A*算法和Q學習的結合。一個自然的猜測是,它是基于AlphaGo的蒙特卡羅樹搜索(Monte Carlo Tree)token軌跡。這似乎是很自然的下一步,之前像AlphaCode這樣的論文表明,即使在大型語言模型中進行非常幼稚的暴力采樣,也可以在競爭性編程中獲得巨大的改進。下一個合乎邏輯的步驟是以更有原則的方式搜索token樹。這在編碼和數學等環境中尤為合理,因為在這些環境中,有一種簡單的方法可以確定正確性。事實上,Q*似乎就是為了解決數學問題。不過,Silas Alberti稱,根據問題的不同,計算量也不同。現在,我們只能對模型采樣一次。如果Q*真的如上所述是樹狀搜索,那么它就可以在一道很難的奧數題上花費10倍、100倍甚至1000倍的計算量。同樣,也有網友表示,Q*是Q-learning和A*算法的結合。「合成數據」是關鍵
Rebuy的AI總監、萊斯大學博士Cameron R. Wolfe認為:Q-Learning「可能」不是解鎖AGI的秘訣。但是,將合成數據生成(RLAIF、self-instruct等)和數據高效的強化學習算法相結合可能是推進當前人工智能研究范式的關鍵...... 他對此做一個簡短版的總結:使用強化學習進行微調是訓練ChatGPT/GPT-4等高性能LLM的秘訣。但是,RL本質上是數據低效的,而且使用人類手動注釋數據集來進行強化學習的微調成本極高。考慮到這一點,推進人工智能研究(至少在當前的范式中)將在很大程度上依賴于兩個基本目標:用更少的數據使RL性能更好。使用LLM和較小的手動標注數據集,為RL綜合生成盡可能多的高質量數據。我們在哪里碰壁?最近的研究表明,使用RLHF來微調LLM是非常有效的。然而,有一個主要問題——RL數據效率低下,需要我們收集大量數據才能獲得良好的性能。為了收集RLHF的數據,我們讓人類手動標注他們的偏好。雖然這種技術效果很好,但它非常昂貴,而且進入門檻非常高。因此,RLHF僅供擁有大量資源的組織(OpenAI、Meta)使用,而日常從業者很少利用這些技術(大多數開源LLM使用SFT而不是RLHF)。
他對此做一個簡短版的總結:使用強化學習進行微調是訓練ChatGPT/GPT-4等高性能LLM的秘訣。但是,RL本質上是數據低效的,而且使用人類手動注釋數據集來進行強化學習的微調成本極高。考慮到這一點,推進人工智能研究(至少在當前的范式中)將在很大程度上依賴于兩個基本目標:用更少的數據使RL性能更好。使用LLM和較小的手動標注數據集,為RL綜合生成盡可能多的高質量數據。我們在哪里碰壁?最近的研究表明,使用RLHF來微調LLM是非常有效的。然而,有一個主要問題——RL數據效率低下,需要我們收集大量數據才能獲得良好的性能。為了收集RLHF的數據,我們讓人類手動標注他們的偏好。雖然這種技術效果很好,但它非常昂貴,而且進入門檻非常高。因此,RLHF僅供擁有大量資源的組織(OpenAI、Meta)使用,而日常從業者很少利用這些技術(大多數開源LLM使用SFT而不是RLHF)。
解決方案是什么?盡管可能沒有完美的解決方案,但最近的研究已經開始利用強大的LLM(比如GPT-4)來自動化數據收集過程,以便使用RL進行微調。這首先是由Anthropic的Constitutional AI探索的,其中LLM合成了用于LLM對齊的有害數據。后來,谷歌提出了人工智能反饋的強化學習(RLAIF),其中LLM用于自動化RLHF的整個數據收集過程。令人驚訝的是,使用LLM生成合成數據以使用RL進行微調非常有效。來自LLM的合成數據。我們在各種研究論文中看到,使用LLM生成合成數據是一個巨大的研究前沿。這方面的例子包括:self-instruct:LLM可以使用LLM自動生成指令調優數據集(Alpaca、Orca和許多其他模型也遵循類似的方法)。LLaMA-2:LLM能夠在人工標注少量示例后為SFT生成自己的高質量數據。Constitutional AI:LLM可以使用自我批判來生成高質量的數據集,以便通過RLHF和SFT進行對齊。RLAIF:我們可以使用LLM完全自動化RLHF的反饋組件,而不是使用人工來收集反饋,并實現可比的性能。 GPT-Zero?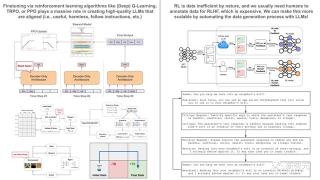 對此,英偉達高級科學家Jim Fan表示:「很明顯,合成數據將提供下一萬億個高質量的訓練token。我敢打賭,大多嚴謹的LLM團隊都知道這一點。關鍵問題是如何保持質量并避免過早停滯不前。Richard Sutton寫的《苦澀的教訓》繼續指導著人工智能的發展:只有兩種范式可以通過計算無限擴展:學習和搜索。他在2019在撰寫本文時,這個觀點是正確的,而今天也是如此。我敢打賭,直到我們解決AGI的那一天。」
對此,英偉達高級科學家Jim Fan表示:「很明顯,合成數據將提供下一萬億個高質量的訓練token。我敢打賭,大多嚴謹的LLM團隊都知道這一點。關鍵問題是如何保持質量并避免過早停滯不前。Richard Sutton寫的《苦澀的教訓》繼續指導著人工智能的發展:只有兩種范式可以通過計算無限擴展:學習和搜索。他在2019在撰寫本文時,這個觀點是正確的,而今天也是如此。我敢打賭,直到我們解決AGI的那一天。」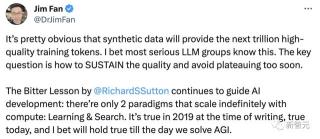 馬斯克對此深表贊同:「一個硬盤就能裝下人類有史以來所有書籍的文本,這實在有點可悲(嘆氣)。而合成數據卻要比這多出十萬倍。」
馬斯克對此深表贊同:「一個硬盤就能裝下人類有史以來所有書籍的文本,這實在有點可悲(嘆氣)。而合成數據卻要比這多出十萬倍。」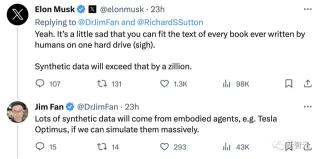 然而,在LeCun看來并非如此。他表示,「動物和人類只需少量的訓練數據,就能很快變得非常聰明。我認為新的架構可以像動物和人類一樣高效地學習。使用更多的數據(合成數據或非合成數據)只是暫時的權宜之計,因為我們目前的方法存在局限性」。
然而,在LeCun看來并非如此。他表示,「動物和人類只需少量的訓練數據,就能很快變得非常聰明。我認為新的架構可以像動物和人類一樣高效地學習。使用更多的數據(合成數據或非合成數據)只是暫時的權宜之計,因為我們目前的方法存在局限性」。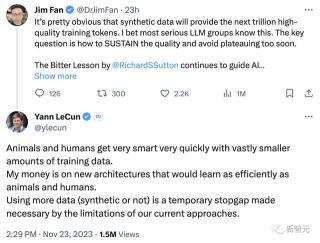 很多人聲稱Q-learning或RLAIF并不新鮮。這些技術可能并不新鮮,但將它們結合起來構建一個產生顯著結果的工作實現是新穎的!偉大的工程+科學=魔法!確實,AlphaZero當年的視頻值得再重溫一遍。
很多人聲稱Q-learning或RLAIF并不新鮮。這些技術可能并不新鮮,但將它們結合起來構建一個產生顯著結果的工作實現是新穎的!偉大的工程+科學=魔法!確實,AlphaZero當年的視頻值得再重溫一遍。
GPT-Zero?
還有人猜測,Q*有可能是Ilya Sutskever創建的GPT-Zero項目的后續。(鏈接:OpenAI新模型曝重大飛躍:AGI雛形或威脅人類,也成Altman被解雇導火索!)很多人聲稱Q-learning或RLAIF并不新鮮。這些技術可能并不新鮮,但將它們結合起來構建一個產生顯著結果的工作實現是新穎的!偉大的工程+科學=魔法!確實,AlphaZero當年的視頻值得再重溫一遍。
Tags:
相關推薦




- 免責聲明
- 本文所包含的觀點僅代表作者個人看法,不代表新火種的觀點。在新火種上獲取的所有信息均不應被視為投資建議。新火種對本文可能提及或鏈接的任何項目不表示認可。 交易和投資涉及高風險,讀者在采取與本文內容相關的任何行動之前,請務必進行充分的盡職調查。最終的決策應該基于您自己的獨立判斷。新火種不對因依賴本文觀點而產生的任何金錢損失負任何責任。
